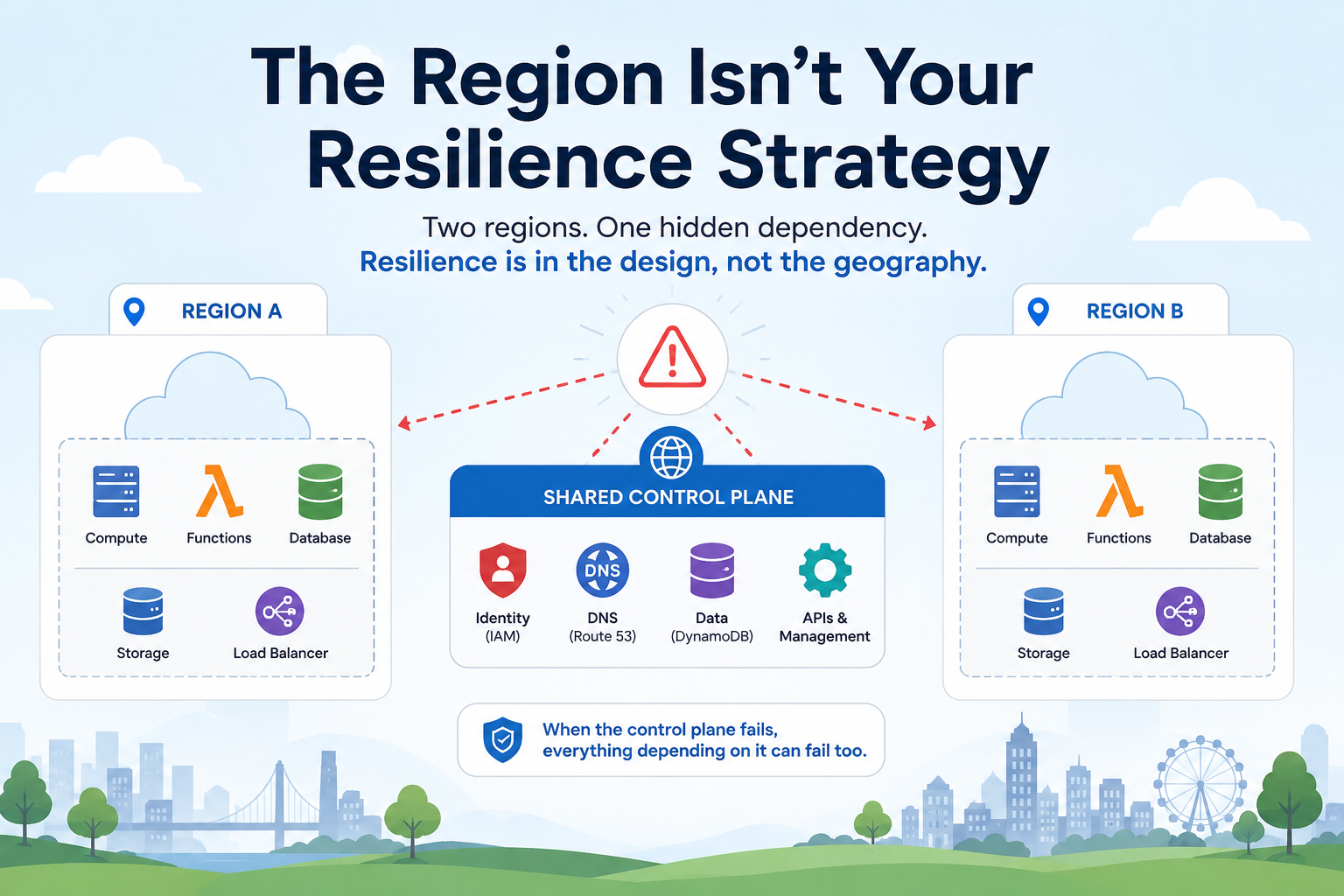
“We’re deployed across two regions” has become the enterprise answer to the resilience question. Architects include it in design documents, leadership repeats it to auditors, and engineering teams treat it as sufficient. In most cases, it is not. Having infrastructure in a second region is a prerequisite for resilience, not evidence of it. The difference matters enormously, and the October 2025 AWS outage made the distinction visible in a way that no architecture review document could.
That outage began with a DNS race condition in a single DynamoDB management system in us-east-1 and cascaded into a 14-hour disruption affecting EC2, Lambda, IAM, and CloudFront, including services running in European regions. The reason is structural: us-east-1 is not just another AWS region. Excluding GovCloud and the EU sovereign region, every AWS control-plane call routes through Virginia: IAM authentication, Route 53 updates, DynamoDB global tables, all of it. Customers running workloads in Frankfurt or Tokyo watched their services fail because the control plane they depended on lived somewhere else entirely.
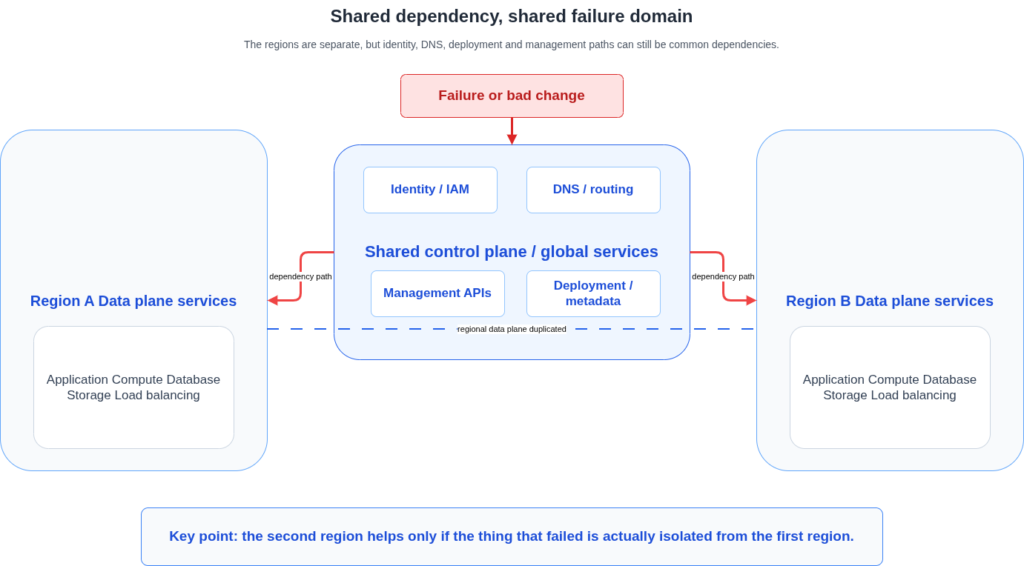
The region is rarely the failure domain. Industry data consistently shows that 54% of cloud disruptions affect a single region or zone, but the causes are not what most resilience plans address. Configuration errors account for 41% of recorded cloud outages. DNS and network failures account for another 27%. These failure modes are not mitigated by spinning up a second region. A misconfigured security group, a botched deployment, an IAM policy change that propagates globally: none of these are stopped by the fact that your standby infrastructure exists in West Europe. The pattern the October 2025 outage exposed was not unique to AWS. A separate June 2025 analysis found that 31% of organisations with multi-region or multi-cloud setups experienced simultaneous failures in both environments because of shared DNS and identity configurations. Regional redundancy at the data plane level provides no protection when the control plane is a shared dependency.

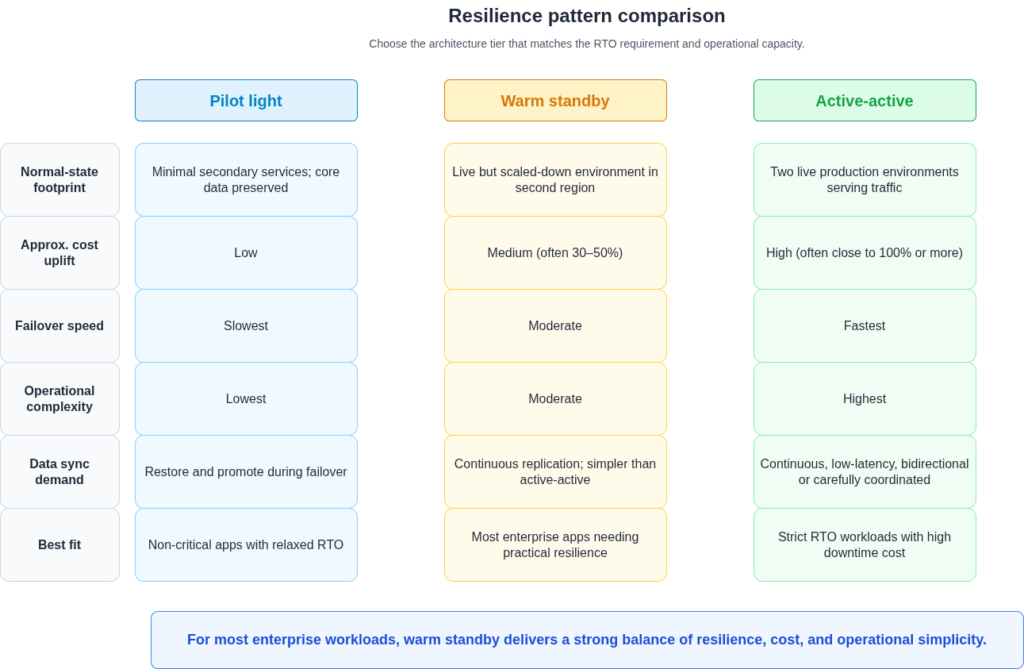
Active-active architecture solves a problem most organisations do not have. Running production traffic across two regions simultaneously offers genuine protection against true regional loss and near-zero failover time. It also doubles infrastructure costs and requires complex, continuous data synchronisation. Conventional relational databases typically need enterprise-grade licensing to support the multi-region replication model, and the operational surface area grows substantially. The organisations for whom this trade-off makes sense are those with both the RTO requirements and the engineering capacity to operate it correctly: global financial platforms, e-commerce businesses where every minute of downtime has a quantifiable revenue cost, regulated workloads with contractual availability commitments. For the majority of enterprise applications, a warm standby architecture with a 30-50% infrastructure cost increase and a validated failover runbook delivers comparable protection at a fraction of the operational burden. The instinct to reach for active-active because a competitor went down during an outage is understandable. It is also usually the wrong response to the wrong diagnosis. As noted in our multi-region architecture patterns guide, the architecture tier should follow the RTO requirement, not the other way around.
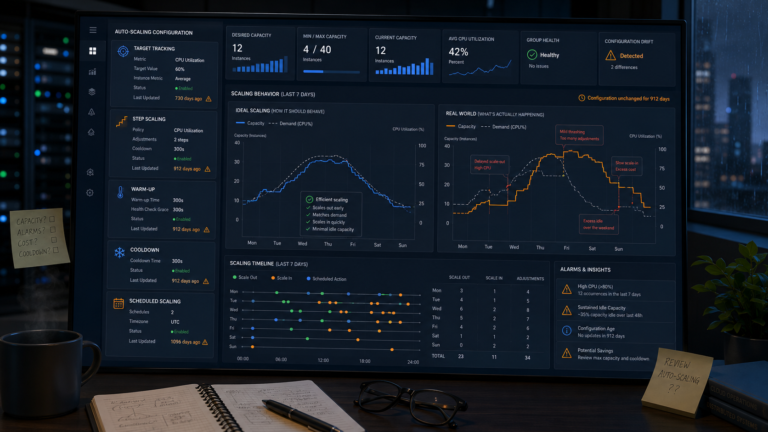
An untested failover is not a failover. Only 49% of organisations run automated failover testing at least once per quarter. That means roughly half the organisations with multi-region deployments have never confirmed, under realistic conditions, that the failover actually works. Configuration drifts. Credentials expire. DNS TTLs that seemed reasonable at design time create delays that breach RTO targets when they are finally exercised. The confidence that comes from having a second region provisioned is genuine: the architecture is in place, the replication is running, the runbooks are written. What it does not confirm is whether the team can execute that failover in 20 minutes at 2am with three people on the call and monitoring also partially degraded. The 2025 outages revealed numerous cases where automated failover failed precisely when it was needed, having never been exercised under the conditions it was designed for. That is not an architecture failure. It is a testing discipline failure, and it is far more common.
What actually reduces blast radius. The organisations that came through the October 2025 outage with the shortest recovery times shared some characteristics that had little to do with whether they were in one region or two. They had decoupled their authentication paths from provider-managed global services where possible. They had designed for graceful degradation rather than binary availability. They had runbooks that were tested quarterly and owned by named individuals, not by a shared wiki page last edited eighteen months ago. They understood which of their services were control-plane-dependent and had documented the implications. These are not glamorous architectural decisions. They do not feature prominently in design review presentations. They are also the decisions that determine whether an incident is a 40-minute recovery or a 14-hour one. The Azure resilience primitives covered in our regions, availability zones, and fault domains guide give useful grounding for thinking through dependency isolation at each layer.
The question worth asking in your next architecture review is not “are we multi-region?” It is “what are our actual failure modes, and have we tested our response to each of them in the last six months?” The answer to the second question tells you far more about your resilience posture than the answer to the first.
Useful Links
- AWS October 2025 US-EAST-1 Outage – ThousandEyes Analysis
- Parametrix Cloud Outage Risk Report 2024
- AWS Multi-Region Architecture and DR Tiers – TechTarget
- Cloud Outage Statistics 2025–2026 – DataStackHub
- AWS Disaster Recovery – AWS Well-Architected Framework
- Azure Reliability Design Principles – Microsoft Docs
- Google Cloud Disaster Recovery Planning Guide