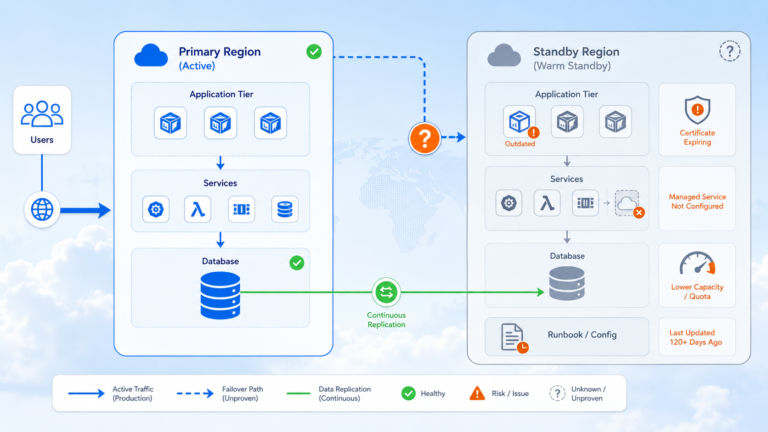
Unplanned cloud downtime costs UK enterprises an average of £4,700 per minute, yet the majority of organisations running in the cloud today have never successfully tested their recovery procedures under realistic conditions. The number is striking not because outages are frequent, they are not, but because when a regional failure does occur, the gap between what teams assumed their architecture could survive and what it actually recovers from becomes impossible to ignore. The three major cloud providers have all published their own post-incident reports from regional impairments in the past three years. The common thread across those incidents was not that the cloud platform failed catastrophically. It was that customer architectures placed dependencies on regional control planes or global services in ways their architects had not fully modelled. Multi-region architecture is not a product of pessimism about cloud reliability. It is a realistic accounting of what modern enterprise workloads actually require.
Most organisations treat multi-region architecture as a disaster recovery problem. They deploy a primary workload in one region, configure some form of backup or replication to a secondary, write a runbook they have never executed, and call it done. This approach conflates two distinct objectives that require different architectural responses. High availability and continuity of operations demand that a workload can withstand a regional impairment with minimal or zero user impact. Data sovereignty and latency optimisation demand that specific data or compute runs within a defined geographic boundary, close to users. Treating these as the same problem produces architectures that are expensive to operate, difficult to test, and uncertain in their actual recovery characteristics. The consequence is that most enterprise teams do not truly know their real RTO or RPO until they are forced to find out in production.
This post provides a structured framework for selecting the right multi-region pattern, explains how AWS, Azure, and GCP approach the hardest parts of the problem differently, and gives you the decision criteria to make an informed architectural choice rather than defaulting to whichever pattern feels most familiar.
The Four Patterns and What They Actually Commit You To
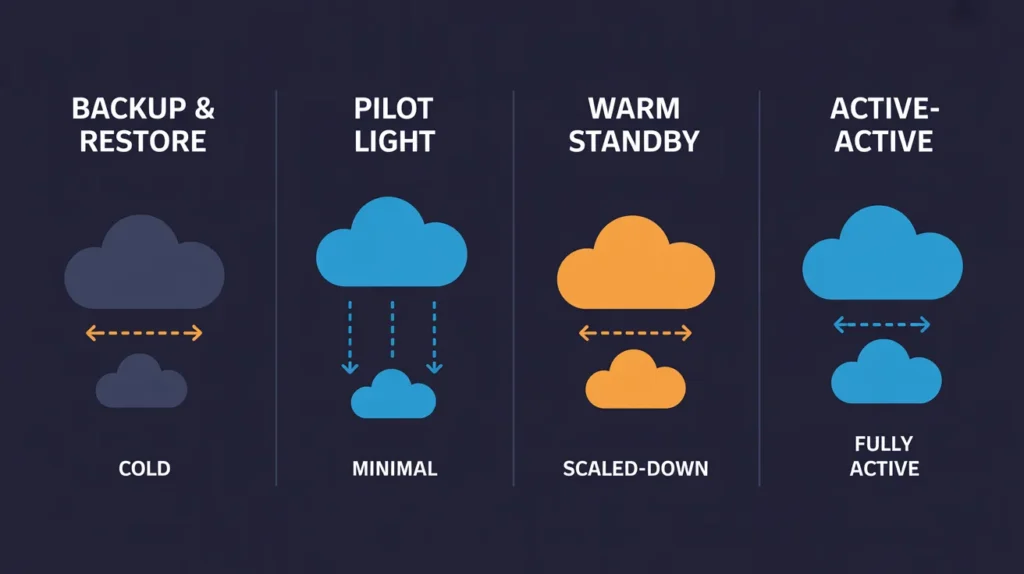
The AWS Well-Architected Disaster Recovery guidance describes four patterns that serve as a useful taxonomy regardless of which cloud platform you are using. Understanding the genuine implications of each, not just the headline RTO and RPO figures, is essential before making a commitment.
Backup and Restore represents the lowest cost and highest risk position. Your data is replicated to a secondary region on a schedule, but no compute is provisioned there. RTO sits in the range of one to four hours, sometimes longer for complex workloads, and RPO is bounded by your backup interval. For most enterprise workloads, this is not a genuine recovery strategy so much as a data protection strategy. It prevents data loss but does not prevent extended outages. The pattern is appropriate for non-critical workloads, development environments, and regulatory archive requirements, but organisations that apply it to customer-facing production systems are typically underestimating their actual RTO requirements until an incident proves otherwise.
Pilot Light introduces a minimal footprint in the secondary region. Core data replication is active, and a skeleton of the most critical infrastructure sits in a provisioned but scaled-down state. When failover is triggered, compute resources are scaled up from the pilot configuration. RTO ranges from ten to sixty minutes depending on scale-up complexity and the sophistication of your failover automation. This is where many enterprise teams land as a compromise between cost and recovery speed. The challenge is that the “light” part frequently grows. Teams add dependencies to the pilot region over time, replication lag accumulates for certain data stores that were not included in the initial design, and scale-up procedures contain untested assumptions about provisioning speed that do not hold during an actual regional impairment when API call rates may be constrained.
Warm Standby runs a scaled-down but fully functional replica of your production workload in the secondary region. All data replication is active, traffic routing is configured and health-checked, and failover triggers automatically or requires only a brief manual decision. RTO drops to minutes and RPO to seconds or low tens of seconds for most database technologies. This pattern is appropriate for workloads where a few minutes of degraded or unavailable service is acceptable but multi-hour outages are not. It costs significantly more than Pilot Light, typically 50 to 70 percent of your active infrastructure cost added as standing overhead, but removes most of the uncertainty that Pilot Light introduces.
Active-Active is the only pattern that provides genuine zero-RTO and near-zero RPO. Both regions serve live traffic simultaneously. Failover is not a discrete event but a traffic routing change, typically completed in seconds by your global load balancer. The cost implication is clear: you are running two production environments. The complexity implication is less obvious. Active-Active demands that every layer of your stack, compute, state, configuration, authentication, observability, operates correctly when requests can land in either region at any moment. Data consistency becomes the central challenge, because writes in Region A must either reach Region B synchronously (adding latency) or accept a window of eventual consistency (creating potential conflicts). Resolving these trade-offs requires deliberate architectural choices that compound in complexity as the number of services in your workload grows.
The Data Replication Problem
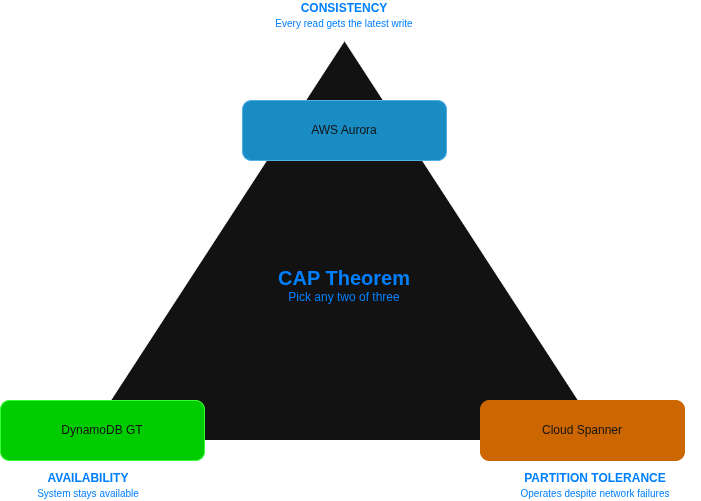
No component of multi-region architecture causes more architectural rework than data replication, and none is more frequently underestimated during initial design. The CAP theorem’s constraint, that a distributed system can guarantee at most two of consistency, availability, and partition tolerance simultaneously, is not merely academic. It dictates real choices about what your application can and cannot safely do when the network partition between regions is active.
The three cloud platforms have taken meaningfully different approaches to their managed replication offerings. AWS provides Aurora Global Database, which replicates committed transactions from the primary region to up to five secondary regions with a typical lag of under one second. For active-passive configurations this works well, but because the secondary is read-only, write traffic cannot be redirected without a promotion step that itself takes 60 to 120 seconds. DynamoDB Global Tables takes a fundamentally different approach, providing multi-active replication across regions where any region can accept writes simultaneously. Conflict resolution uses last-writer-wins semantics, which is appropriate for many use cases but requires application-level awareness for workloads where concurrent conflicting writes are meaningful.
Azure’s Cosmos DB is the most architecturally flexible of the managed multi-region database services across the three clouds. Its five configurable consistency levels let architects tune the consistency-latency trade-off precisely: Strong consistency provides linearisability but doubles read latency by reading from the closest quorum, while Eventual consistency provides the lowest latency at the cost of potential read staleness. The multi-write regions capability enables Active-Active deployments with conflict resolution policies configurable per-container. For relational workloads, Azure SQL Failover Groups abstract the underlying geo-replication into a readable secondary with automatic DNS-based failover, though the secondary remains read-only until failover is triggered. Azure Blob Storage geo-redundant storage (GRS) replicates data asynchronously to a paired region with RPO measured in hours rather than seconds, which is frequently misunderstood as suitable for low-RPO scenarios, it is not.
GCP’s approach with Cloud Spanner represents the most radical departure from conventional database architecture. Spanner provides synchronous, globally distributed consistency using TrueTime, Google’s globally synchronised clock infrastructure. Writes commit synchronously across all regions before returning success to the application, which eliminates replication lag entirely at the cost of write latency that increases with the physical distance between regions. For a dual-region configuration within Europe (covering Belgium and the Netherlands regions), write latency overhead is typically 10 to 20 milliseconds, which is acceptable for most transactional workloads. For truly global configurations spanning multiple continents, that overhead climbs and must be evaluated against the application’s latency requirements. Cloud SQL cross-region read replicas follow a more conventional asynchronous replication model and are appropriate for read-heavy workloads where the primary region handles all writes.
For object storage and static assets, all three clouds provide cross-region replication with similar characteristics: asynchronous replication with seconds to low-minute lag for small objects. S3 Cross-Region Replication, Azure Blob GRS, and GCP Cloud Storage multi-region buckets are all mature, reliable services for this tier of your data architecture. The meaningful differences emerge at the database and state management layer, which is where the architectural decisions have the most consequence.
Global Traffic Routing
Once your data architecture is settled, the traffic routing layer determines how quickly and reliably your multi-region system responds to regional impairments. The three platforms differ significantly in their approach, and the differences are not merely cosmetic.
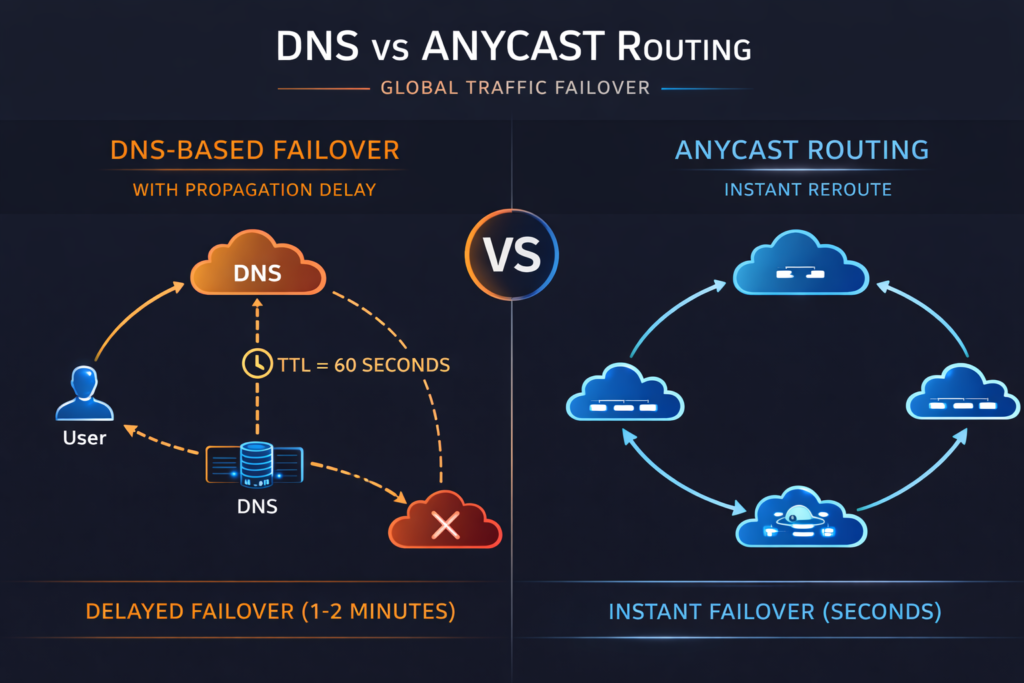
AWS provides two distinct services that many teams conflate. Route 53 is a DNS-based routing service that can direct traffic using latency-based, geoproximity, weighted, or health-check-based routing policies. DNS-based failover inherently introduces TTL delays, typically 60 to 120 seconds, before traffic is redirected during a health-check failure. AWS Global Accelerator uses Anycast IP addresses and the AWS backbone network to route traffic to the nearest healthy endpoint without DNS involvement, providing failover in under 30 seconds for most configurations. For latency-sensitive or strict RTO workloads, Global Accelerator is the appropriate choice, though it adds cost that Route 53 alone does not.
Azure offers Traffic Manager for DNS-based routing and Azure Front Door for anycast, layer-seven routing with integrated WAF and CDN capabilities. Front Door’s global presence points of presence enable intelligent routing and provide sub-30-second failover for application-layer health failures, while also terminating TLS at the edge and providing DDoS protection. For teams already using Front Door for performance or security reasons, the multi-region failover capability is essentially included. Teams relying solely on Traffic Manager should account for DNS TTL propagation in their RTO calculations.
GCP’s Global Load Balancing is architecturally distinct from both AWS and Azure approaches. A single Anycast IP address distributes traffic across all backend regions, and the routing decision happens at Google’s network edge, not at the DNS layer. There is no equivalent TTL delay because the Anycast IP itself does not change during failover, Google’s network simply stops routing packets to unhealthy backends and directs them to healthy ones within seconds. This single-IP model also simplifies certificate management and eliminates the DNS propagation uncertainty that affects both AWS Route 53 and Azure Traffic Manager configurations. For teams building new multi-region workloads on GCP, the Global Load Balancer is one of the more underappreciated architectural advantages the platform provides.
Network Architecture Across Regions
The network connectivity between your regions, and between your cloud environments and on-premises infrastructure, has implications for both performance and cost that are frequently discovered late in a multi-region migration. Cross-region data transfer costs can be two to three times higher than within-region transfer costs, and they accumulate quickly in architectures with significant inter-region replication or synchronisation traffic.
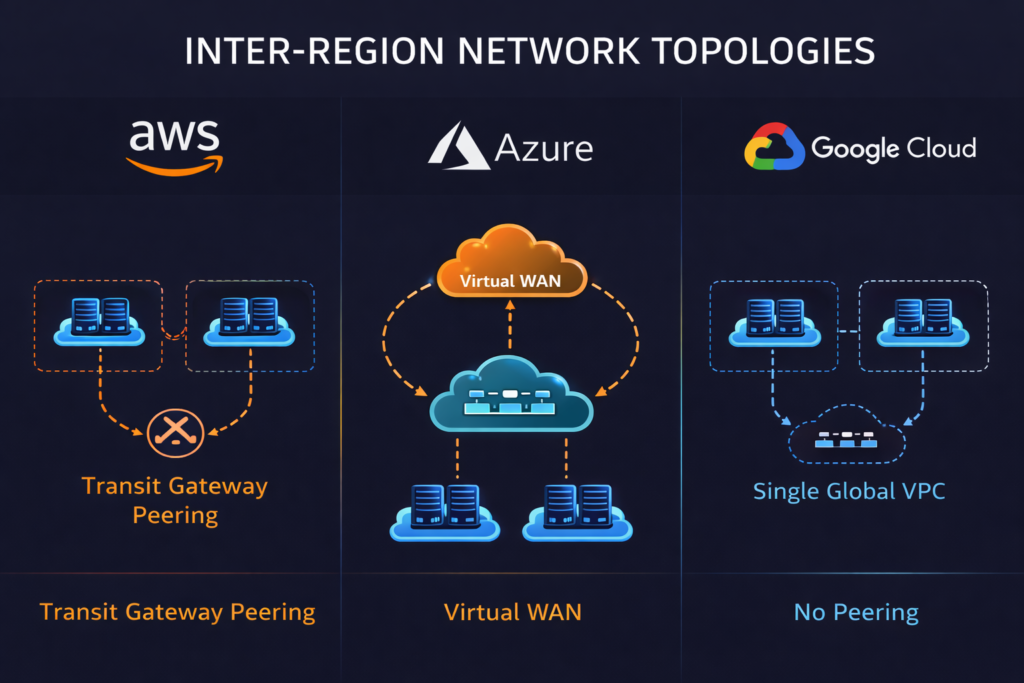
AWS Transit Gateway provides inter-region connectivity through Transit Gateway peering, enabling a hub-spoke model that scales more cleanly than VPC peering as the number of regions grows. For workloads with dedicated connectivity requirements, AWS Direct Connect Gateway extends on-premises connectivity to multiple regions through a single Direct Connect connection. The AWS Well-Architected Framework’s reliability pillar recommends treating each region as an independent fault isolation boundary, which means avoiding control plane dependencies that span regions in the data path.
Azure’s Virtual WAN, covered in detail in our enterprise network hub architecture guide, provides a managed global transit backbone that simplifies multi-region connectivity significantly compared to manually peered hub-spoke topologies. ExpressRoute Global Reach enables on-premises sites to communicate with multiple Azure regions through a single ExpressRoute circuit, which reduces both cost and operational complexity for hybrid multi-region configurations.
GCP’s network architecture provides a structural advantage that matters significantly for multi-region workloads: a single global VPC can span all regions without peering. Resources in London can communicate with resources in Iowa over Google’s private backbone without routing through public internet and without configuring VPC peering relationships. This simplifies inter-region communication considerably and reduces the operational overhead of multi-region network management, though it also means that network security controls must be applied at the subnet and firewall rule level rather than at the VPC boundary.
Vendor Comparison Matrix
| Capability | AWS | Azure | GCP |
|---|---|---|---|
| Managed relational multi-region | Aurora Global DB (async, <1s lag) | SQL Failover Groups (async) | Cloud Spanner (synchronous) |
| Multi-write NoSQL | DynamoDB Global Tables | Cosmos DB (multi-write regions) | Firestore (multi-region) |
| Traffic routing (DNS) | Route 53 | Traffic Manager | Cloud DNS |
| Traffic routing (Anycast) | Global Accelerator | Azure Front Door | Global Load Balancing (native) |
| Inter-region networking | Transit Gateway peering | Virtual WAN | Single global VPC (no peering) |
| Object storage replication | S3 CRR | Blob GRS / GZRS | Cloud Storage multi-region |
| Failover orchestration | Route 53 ARC | Azure Site Recovery | n/a (relies on GCLB health checks) |
| RPO for managed relational DB | Seconds (<1s typical) | Seconds (async) | Zero (synchronous) |
| Minimum RTO for warm standby | Minutes (with ARC) | Minutes | Seconds (with GCLB) |
Real-World Case Studies
Department of Premier and Cabinet, Tasmania (Government / Public Safety)
Scale context: 650,000+ end users, serving the entire Tasmanian population through the TasALERT emergency communications platform.
Challenge: The agency needed a public safety communications platform capable of surviving regional cloud impairments during precisely the conditions when it would be most heavily used, natural disasters including bushfires and floods.
Solution implemented: DPAC deployed the first Active-Active multi-region architecture used by an Australian public agency, distributing the complete workload infrastructure and data across both the Sydney and Melbourne AWS regions. AWS Elastic Beanstalk handled automated scaling, while Route 53 managed health-check-based traffic routing between regions.
Measurable outcomes: The platform has achieved 100% availability and uptime since launch. During the February 2024 bushfires, the Active-Active architecture maintained continuous availability during a 532% surge in traffic, precisely the conditions where a single-region architecture would have faced its highest risk.
Source: https://aws.amazon.com/solutions/case-studies/department-premier-cabinent-tasmania-case-study/
RS2 Smart Processing Limited (Financial Services / Payment Processing)
Scale context: BankWORKS SaaS platform serving banks, payment gateways, and ATMs across 27 countries covering 121 currencies.
Challenge: As a PCI-DSS certified payment processor, RS2 required annual compliance audits that included a mandatory 24-hour failover exercise, operating all production workloads from the secondary region and then failing back. Their architecture needed to meet specific RTO and RPO thresholds under audit conditions, not just theoretical targets.
Solution implemented: RS2 deployed AWS Elastic Disaster Recovery across 44 servers running in their primary AWS region, enabling cross-region replication and point-in-time recovery. The solution was implemented in May 2022 and completed in July 2022, providing automated cross-region failover and failback capability.
Measurable outcomes: During the first full 24-hour audit drill in October 2022, RS2 successfully ran all production workloads including live write transactions from the secondary region, then failed back to primary. Measured RTO is 30 minutes and RPO is under 1 minute against a compliance requirement of 1-hour RPO, exceeding compliance requirements by a significant margin.
Source: https://aws.amazon.com/solutions/case-studies/rs2-smart-processing-limited-case-study/
Capital One (Financial Services / Consumer Banking)
Scale context: One of the largest US consumer banks, serving tens of millions of customers across digital banking, credit card, and lending products.
Challenge: Capital One was running workloads across on-premises data centres with quarterly and monthly release cycles and development environment provisioning that took up to three months. The organisation needed to migrate to cloud-native architecture while improving resilience and development velocity simultaneously.
Solution implemented: Capital One executed an eight-year migration to AWS, closing all on-premises data centres and rebuilding approximately 80% of its nearly 2,000 applications from the ground up as cloud-native services. The mobile app and core banking services were built on multi-region Active-Active architecture using EC2, Lambda, DynamoDB, and SNS.
Measurable outcomes: Active-active multi-region architecture replaced a conventional disaster recovery approach. Release frequency moved from quarterly and monthly to multiple times daily. Development environment provisioning dropped from three months to minutes. The Capital One mobile app maintained continuous availability for account access, payments, and transaction visibility during the COVID-19 pandemic demand surge.
Source: https://aws.amazon.com/solutions/case-studies/capital-one-all-in-on-aws/
Cost Analysis and ROI
Multi-region architecture is expensive, and the cost is frequently understated during the architecture phase. Understanding the genuine cost model for each pattern is essential to making an honest business case.
Active-Active doubles your infrastructure spend in the simplest case: you are running two production environments. In practice, it is often 1.6 to 1.9 times the single-region cost because some services, particularly managed global services for routing, DNS, and identity, are shared rather than duplicated. The data transfer costs between regions are the element most commonly missed in initial estimates. Replication traffic for high-throughput databases and object stores can add 15 to 25 percent to the total bill for data-intensive workloads. For the Active-Active pattern to be commercially justifiable, the cost of downtime (including direct revenue loss, SLA penalties, and reputational impact) must exceed the ongoing architectural overhead at the expected frequency of regional impairments.
Warm Standby adds approximately 50 to 70 percent overhead to your single-region infrastructure cost. The secondary environment runs at reduced capacity, typically 10 to 20 percent of production scale, but must include full replicas of all managed services, network connectivity, and monitoring. The commercial justification is easier to establish than Active-Active because the overhead is lower, but the RTO commitment must be honest: warm standby RTO of “minutes” requires tested, automated failover procedures, not a runbook that someone reads during an incident.
Pilot Light is often the most commercially attractive pattern for workloads that truly need multi-region resilience but cannot justify Active-Active or Warm Standby costs. The standing overhead is 20 to 30 percent of single-region infrastructure, with burst costs during a failover event when secondary region resources are scaled up. The hidden cost of Pilot Light is operational: teams must maintain failover procedures, test them regularly (quarterly is the minimum for any pattern you rely on), and account for provisioning time that may be constrained during a regional event when other customers are simultaneously attempting the same scale-up operations.
The cost of data transfer between regions deserves specific attention because it scales with workload. AWS charges between $0.02 and $0.09 per GB for inter-region transfer depending on the source and destination regions. Azure charges between $0.02 and $0.05 per GB. GCP charges $0.08 per GB for most region pairs. For a workload replicating 10 TB of data per month between regions, this represents $200 to $900 in transfer costs alone. These figures compound quickly for data-intensive workloads and should be modelled explicitly before committing to a replication architecture. Our FinOps Evolution guide covers the governance frameworks needed to track these costs as they scale.
Decision Framework
The correct multi-region pattern for a given workload is determined primarily by its RTO and RPO requirements, which should be specified by the business owner rather than assumed by the engineering team. The following framework provides a starting point for that conversation.
Active-Active is the appropriate pattern when RTO is measured in seconds, RPO approaches zero, and the workload directly generates revenue or supports safety-critical operations. Regulated financial services, payment processing, real-time trading, and emergency services communication platforms fall into this category. It is also appropriate when the primary driver for multi-region is latency reduction for geographically distributed users rather than resilience, because serving traffic from multiple regions simultaneously is the only way to guarantee proximity for all users. The DPAC Tasmania case study illustrates both drivers simultaneously: the emergency alert platform needed both maximum resilience and responsiveness for users distributed across a large geographic area.
Warm Standby is the right choice when RTO of five to fifteen minutes is truly acceptable, RPO of seconds to low tens of seconds is sufficient, and the cost of Active-Active cannot be justified by the business case. Many enterprise internal platforms, high-value back-office systems, and B2B SaaS platforms fall into this category. The defining characteristic is that a short period of degraded service during failover is tolerable, but multi-hour outages are not. UK organisations operating under FCA or PRA oversight frequently need to demonstrate tested RTO capabilities in this range as part of operational resilience assessments.
Pilot Light is appropriate for workloads where RTO of thirty to sixty minutes is truly acceptable and RPO of five to fifteen minutes is sufficient. This covers a substantial portion of enterprise workloads including internal tooling, reporting systems, and non-customer-facing services that run in production but are not on the critical path for revenue generation. The qualification “truly acceptable” is important: teams frequently underestimate the business impact of extended outages until they occur, so the RTO and RPO targets should be signed off by business stakeholders rather than assumed by engineering.
Backup and Restore is appropriate for development environments, compliance archives, and workloads where the business explicitly accepts multi-hour RTO and RPO. It should not be presented to business stakeholders as a multi-region resilience strategy for production workloads; it is a data protection strategy.
Regulatory requirements add a second dimension to this decision for UK-regulated organisations. The FCA’s operational resilience framework requires firms to identify important business services, define impact tolerances (broadly analogous to RTO and RPO), and demonstrate that they can remain within those tolerances by March 2025. NHS Digital workloads have NHS service standard requirements including specific availability targets. GDPR data residency requirements may constrain the regions available for replication, which matters particularly for EU-based secondary regions when the primary is in the UK.
Implementation Roadmap
Phase 1: Foundation (Months 1 to 3)
The foundation phase establishes the data replication architecture and validates that your RPO target is achievable before any compute migration begins. For each data store in your workload, define the target RPO and select the replication mechanism appropriate to that target. For databases, enable cross-region replication and measure actual replication lag against the target under production-representative load. This measurement is frequently the point at which teams discover that their assumed RPO is not achievable with the services they have selected, or that replication traffic costs are significantly higher than modelled. Resolve these issues in Phase 1 before committing to a full multi-region architecture.
Network connectivity between regions should be established and validated during this phase. Confirm that cross-region latency between your chosen regions is within the acceptable range for your workload’s synchronous dependencies. For teams with existing on-premises connectivity, validate that the secondary region is reachable with appropriate latency through your existing Direct Connect, ExpressRoute, or Cloud Interconnect configuration.
Phase 2: Traffic Routing and Failover Automation (Months 4 to 9)
Phase 2 deploys the compute layer in the secondary region, configures global traffic routing, and builds the automated failover procedures that your RTO depends on. For Warm Standby and Active-Active patterns, the secondary compute must be running and serving health-check traffic before failover can be validated. Configure health checks against meaningful application-level indicators, not just TCP connectivity: a health check that responds 200 OK while the application cannot serve real requests provides false confidence.
Failover automation should be implemented as code, version-controlled, and validated in a staging environment that mirrors production. AWS Application Recovery Controller, Azure Site Recovery, and GCP’s health-check-based load balancer responses each provide orchestration mechanisms, but the application-specific steps, configuration changes, database promotion, cache invalidation, are your responsibility to automate. The RS2 case study illustrates what happens when this automation is truly tested: the 24-hour audit drill revealed no gaps because the team had validated the procedure before relying on it.
Observability in a multi-region architecture requires explicit design. Your monitoring must be able to distinguish a regional impairment from a full outage, route alerts to on-call engineers even when one region is impaired, and provide visibility into replication lag and traffic distribution across regions. Our AWS Well-Architected Review framework post covers the observability patterns that translate directly to multi-region monitoring requirements.
Phase 3: Maturity and Continuous Validation (Months 10 to 18)
The final phase is less about deployment and more about proving that your multi-region architecture behaves as designed under conditions that approximate real failures. Chaos engineering exercises, ranging from injecting synthetic latency into cross-region replication to simulating full regional impairment in a non-production environment, are the only reliable way to validate that your RTO and RPO targets are achievable rather than theoretical. Many organisations that have never tested their failover procedures discover during their first exercise that the runbook contains assumptions that do not hold under the conditions that typically accompany a genuine regional impairment.
Cost governance requires ongoing attention in a multi-region architecture because the operational baseline is significantly higher than single-region. Establish tagging and cost allocation for multi-region infrastructure from day one, and monitor replication traffic costs separately from compute and storage. These costs tend to grow quietly as workloads expand.
Future Trends
Cell-based architecture represents the most significant evolution in multi-region design for large-scale systems. Rather than thinking in terms of regions, cell-based architectures decompose a workload into independent cells that each serve a subset of customers, with geographic distribution handled by routing customers to the nearest healthy cell. AWS’s deployment of this pattern internally has been documented in detail, and the approach is increasingly visible in large-scale SaaS architectures. For most enterprise teams, cell-based architecture is not yet the right starting point, but understanding the pattern is valuable because it resolves the toughest challenges of Active-Active at scale, particularly around blast radius containment and partial failover.
AI-driven failover decision support is beginning to appear in enterprise monitoring platforms. Rather than triggering failover based on binary health-check pass/fail signals, predictive systems can identify degradation patterns that precede impairments and initiate pre-emptive traffic shifting before users are affected. This capability is most mature in proprietary observability platforms and is beginning to appear in native cloud tooling.
Strategic Recommendations
For organisations that have not yet deployed a multi-region architecture, start by auditing your existing single-region architecture against the four patterns rather than assuming you need Active-Active. The majority of enterprise workloads have genuine business requirements that are met by Warm Standby or Pilot Light, and overbuilding for Active-Active where it is not required adds complexity and cost without proportional benefit.
For organisations already operating in multiple regions, the most valuable investment is usually in the testing and validation layer rather than the architecture itself. If you cannot demonstrate that your failover procedures work correctly under production conditions, your architecture’s RTO and RPO targets are aspirational rather than guaranteed. Quarterly failover exercises, automated failover testing in staging, and defined blast radius boundaries are the indicators that distinguish operational multi-region capability from paper architecture.
For regulated organisations, treat your operational resilience framework compliance as an architecture input rather than a compliance checkbox. The FCA’s requirements to demonstrate impact tolerance adherence by March 2025 should be driving specific RTO and RPO targets for important business services, which in turn should be driving pattern selection. Teams that derive their multi-region pattern from regulatory impact tolerance requirements, validate it through testing, and document the evidence are in a significantly better position than teams that design architectures and then attempt to map them retroactively to regulatory requirements.
The data replication and traffic routing decisions are irreversible in the short term once a workload is live, so they deserve the most careful analysis during the design phase. Everything else, including compute scale, failover automation sophistication, and chaos engineering maturity, can be improved incrementally. Get the data architecture right first.
Useful Links
- AWS Multi-Region Fundamentals
- AWS Well-Architected Reliability Pillar
- AWS Disaster Recovery of Workloads
- Azure Site Recovery documentation
- Azure Cosmos DB distribution documentation
- GCP Cloud Spanner regional and multi-region configurations
- GCP Global Load Balancing overview
- DPAC Tasmania case study (AWS)
- RS2 Smart Processing case study (AWS)
- Capital One case study (AWS)