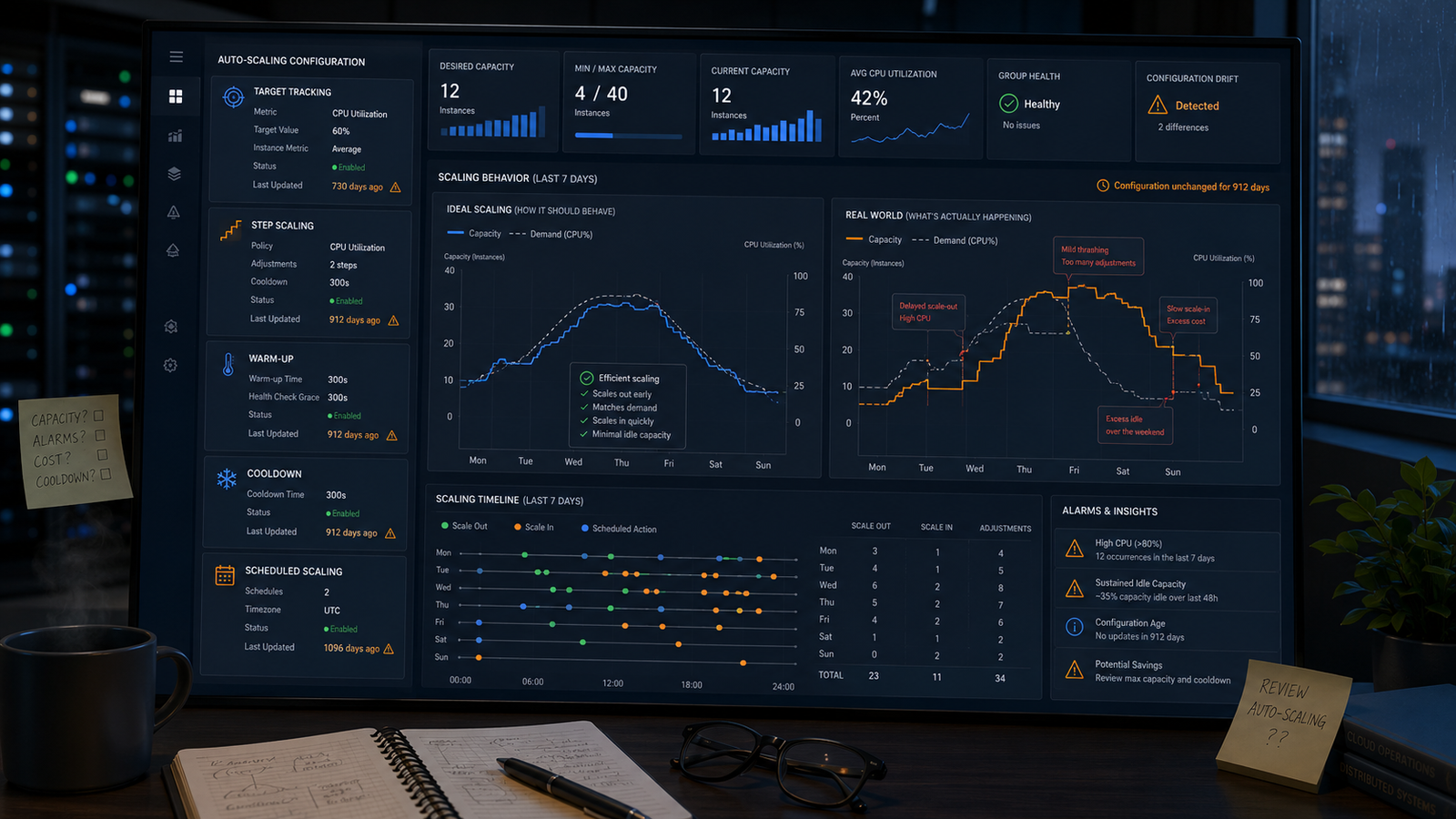
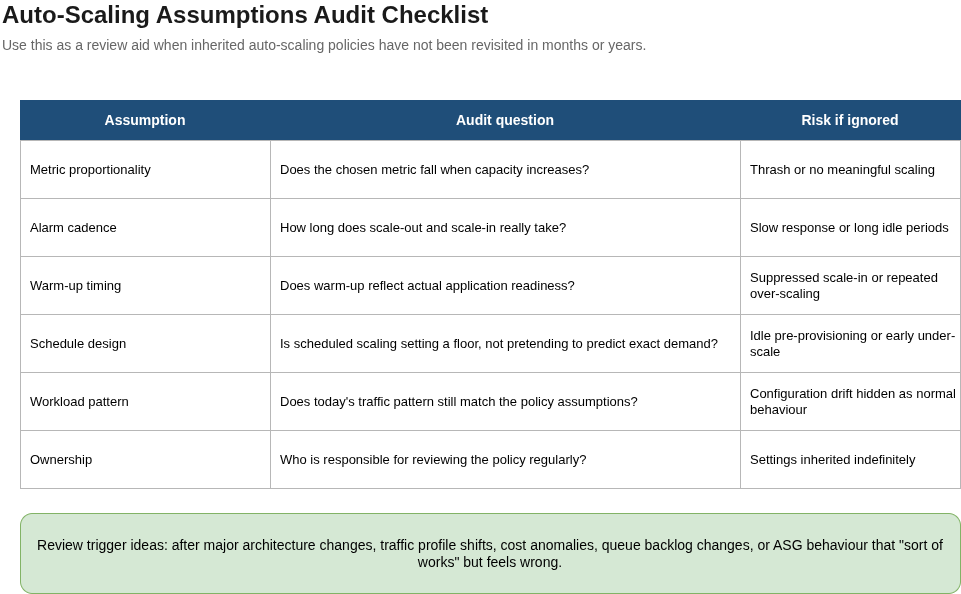
Most AWS Auto Scaling configurations are set up once, inherited by the next team, and trusted indefinitely. The failure mode is never dramatic. It is the group that thrashes every three minutes and appears to self-correct. It is the Monday morning under-scale that nobody traces back to a configuration written two years ago. It is the scale-in that takes seventy-five minutes because nobody changed a metric cadence nobody knew existed. The three mechanisms available, target tracking, step scaling, and scheduled scaling, each encode assumptions about how your traffic behaves. Those assumptions had a shelf life.
When you create a target tracking policy, AWS creates two CloudWatch alarms on your behalf and explicitly forbids you from editing them. Until November 2024, both alarms ran on a fixed evaluation cadence: three consecutive breaching datapoints to trigger scale-out, fifteen to trigger scale-in. With basic monitoring, the default, EC2 metrics publish every five minutes. That cadence means fifteen minutes to scale out and seventy-five minutes to scale in. AWS’s November 2024 “Highly Responsive Scaling Policies” update made target tracking auto-tune its responsiveness, but groups created before that date are running the legacy cadence unless they publish a custom high-resolution metric. Most production ASGs have not. The scale-in conservatism is also by design: target tracking will not remove capacity unless doing so keeps the metric below the target, and even then only when utilisation has dropped “usually more than 10% lower” than the target value. A group targeting 50% CPU will frequently sit at 35-45% after a traffic taper. That is the correct call for availability and a sustained cost tax if it applies across a hundred instances.
Warm-up and cooldown are different primitives, and treating them as synonyms is the root cause of more scaling incidents than any other single misconfiguration. Simple scaling uses cooldown: a hard gate that blocks all further scaling activity until the period expires. Target tracking and step scaling use warm-up. During warm-up, new instances count toward group capacity to prevent over-provisioning, scale-out can continue, and scale-in is blocked. A group under step scaling will keep adding capacity during a sustained breach while an engineer watching it assumes cooldown has locked things down. The failure in the other direction is equally common: warm-up inflated to compensate for a slow boot rather than fixing the boot. With a 600-second warm-up, scale-in is suppressed for ten minutes after every scale-out event regardless of whether demand has dropped. DefaultInstanceWarmup, which unifies warm-up behaviour across target tracking, step scaling, and instance refresh, has been available since April 2022 and is not enabled by default. If unset, each event type falls back to a different timing assumption, silently.

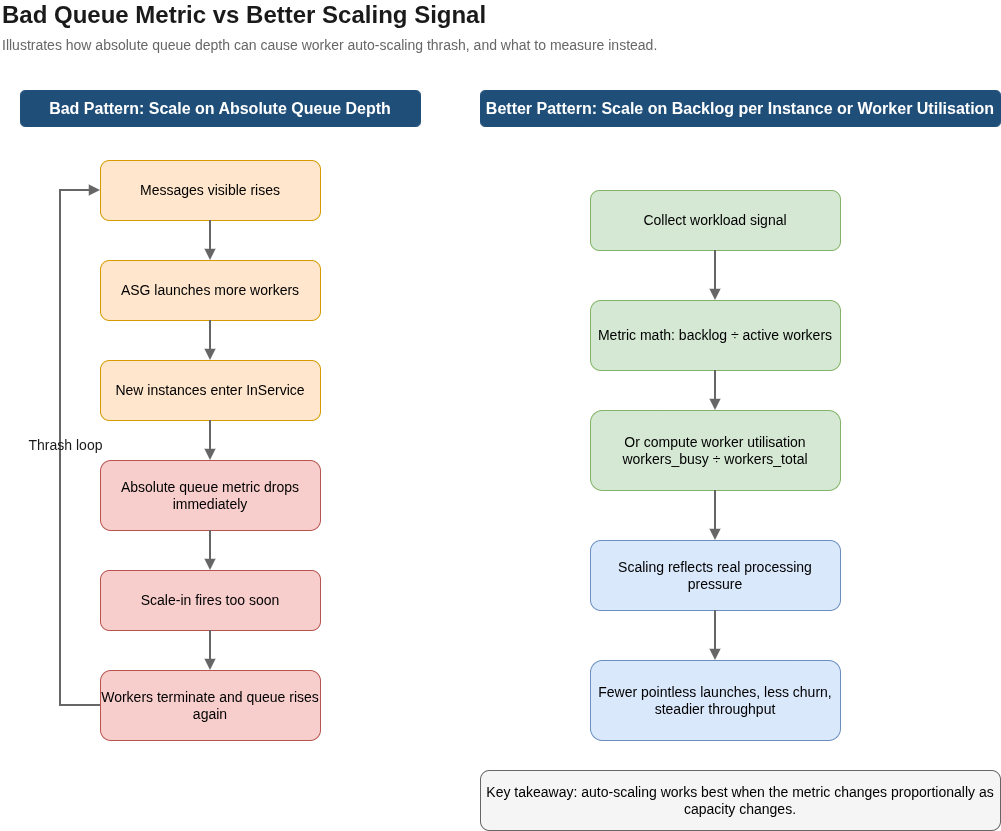
Target tracking only works correctly on metrics that move proportionally when capacity changes. CPU utilisation works for CPU-bound applications. ALBRequestCountPerTarget works because the load balancer divides requests across registered targets. The total RequestCount at the load balancer does not, because adding instances does not reduce the total number of requests arriving. The queue-depth version of this is the most common production thrash. An SQS-based worker ASG scaling on ApproximateNumberOfMessagesVisible looks correct until new instances enter InService and the per-instance derived metric collapses immediately, before those instances have consumed a single message. Scale-in fires, instances are terminated, the metric spikes, and the cycle repeats every few minutes. The correct pattern is a backlog-per-instance metric via metric math, or a worker-utilisation metric computed as workers_busy / workers_total, which reflects actual processing capacity rather than absolute queue depth. This class of thrash is also expensive beyond the obvious: launch and termination cycles consume capacity reservation, ELB registration time, and application bootstrap resources on instances that perform almost no useful work before being terminated.
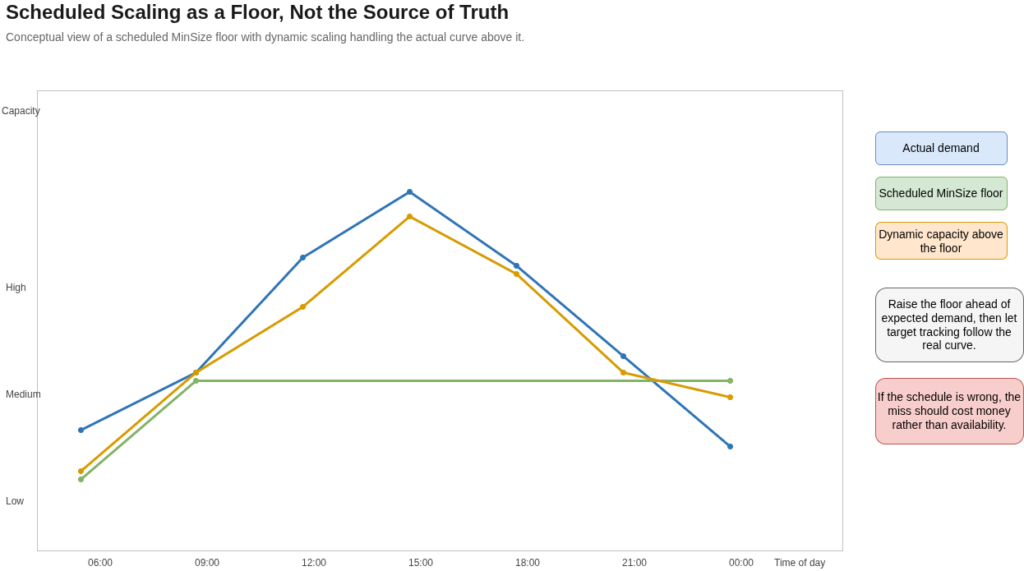
Scheduled scaling fails when the schedule becomes the source of truth rather than a floor constraint. The mechanism is deterministic: at the cron tick, it sets minimum size, maximum size, or desired capacity and defers to dynamic policies for everything else. When traffic arrives before the schedule fires, you are under-provisioned until a dynamic policy catches up. At a fifteen-minute alarm cadence and a four-minute boot, that is roughly twenty minutes of constrained capacity. When traffic does not arrive at all, pre-provisioned capacity sits idle until the next scale-down fires. The cron expression defaults to UTC, which drifts an hour twice a year for any team not specifying an IANA time zone. The pattern that survives these failure modes is to use scheduled actions to raise MinSize as a floor ahead of anticipated demand, leaving target tracking to handle the actual curve on top. A schedule miss then costs money rather than availability. The broader FinOps framing for this kind of policy-level trade-off is in our FinOps Evolution guide, which addresses how to separate idle-by-design from idle-by-misconfiguration in cloud spend attribution.
The three mechanisms are well-documented individually. What is less documented is what they assume about the workload running under them. Target tracking configured for a gradual web API may not survive a shift to event-driven processing. Step scaling authored for a clean CPU gradient will fail silently at the extremes if threshold ranges have gaps. Scheduled scaling set up for a stable weekday pattern will strand capacity the first time demand does not match the calendar. The right audit question is not whether auto-scaling is configured. It is whether the assumptions made during configuration still describe the workload running today.
Useful Links
- Target tracking scaling policies for Amazon EC2 Auto Scaling
- Faster scaling with Amazon EC2 Auto Scaling Target Tracking (November 2024)
- Available warm-up and cooldown settings
- EC2 Auto Scaling default instance warm-up announcement (April 2022)
- Step scaling policies for Amazon EC2 Auto Scaling
- Scheduled scaling for Amazon EC2 Auto Scaling
- How Application Auto Scaling target tracking works
- Scaling your applications faster with EC2 Auto Scaling Warm Pools
- Enhancing auto scaling resilience by tracking worker utilisation metrics
- Predictive scaling for Amazon EC2 Auto Scaling