Most architects evaluating GCP networking start with the wrong question. After years of building on AWS or Azure, the instinct is to ask “how do I connect my VPCs across regions?” and then spend weeks designing transit VPC patterns, cross-region peering chains, and multi-region route tables. The problem is that GCP does not have regional VPCs. A GCP VPC is a global resource that spans every region simultaneously, with subnets as the regional unit of allocation. The question experienced architects should actually be asking is: “how do I segment and govern a single global network across hundreds of projects and dozens of teams?” That reframe changes every decision that follows: which services you choose, how you design for security, and which mistakes you will make if you arrive carrying mental models built on platforms that work very differently.
The cost of getting that mental model wrong is measured in months, not hours. Teams that replicate AWS-style multi-VPC-per-region architectures on GCP quickly hit VPC peering’s hard limits. Peering on GCP is non-transitive: if VPC A peers with VPC B, and VPC B peers with VPC C, VPC A cannot reach VPC C. What works for a handful of workloads becomes a combinatorial nightmare at scale, requiring N(N-1)/2 peering connections to achieve full mesh reachability. Ten VPCs require 45 distinct peering relationships. Connecting 20 requires 190. Azure architects encounter a different version of the same trap, designing hub-spoke topologies and expecting to configure bidirectional peering, user-defined routes, and gateway transit settings, constructs that are either unnecessary or work completely differently in GCP’s model.
Three services compose into the foundation of every production GCP network: Shared VPC for centralised network ownership across projects, Network Connectivity Center (NCC) for hub-and-spoke connectivity orchestration, and Private Service Connect (PSC) for service-oriented private access. Used together, they replace the peering mesh with something that scales to enterprise size without accumulating per-connection management overhead. Each service addresses a distinct layer of the problem, and each rewards architects who approach it on GCP’s own terms rather than looking for direct equivalents to what they already know.
The Global VPC: The Foundation You Must Internalise First
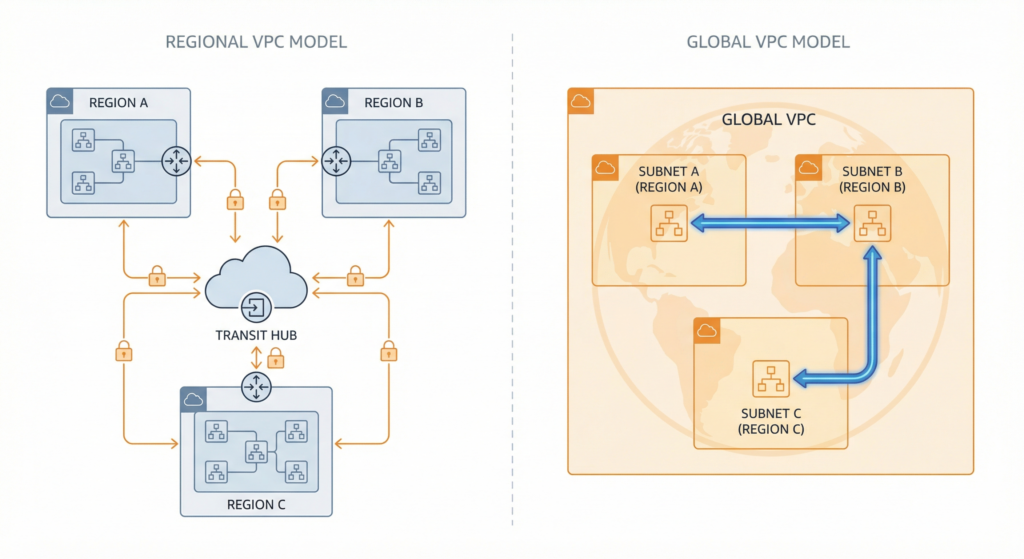
Before any of the three services make sense, GCP’s VPC model must be understood clearly, because it underpins everything else. A GCP VPC is a global logical construct that spans all regions simultaneously. Subnets are regional, each associated with a single region while automatically covering all zones within that region. Routes and firewall rules operate at the VPC level and are global by default.
The practical implication is significant. A multi-region deployment in AWS requires creating separate VPCs per region, connecting them via Transit Gateway or VPC peering, duplicating security groups, and managing region-specific route tables. The GCP equivalent is a single VPC with regional subnets. Cross-region communication between resources in the same VPC happens automatically over Google’s private backbone using internal IP addresses, with no additional configuration, no transit service, and no extra routing cost within the VPC.
GCP subnets also behave differently from their AWS counterparts. An AWS subnet maps to a single Availability Zone, which is why the standard pattern involves creating three subnets per region for AZ redundancy. A GCP subnet spans all zones in a region. There is no concept of a zone-specific subnet; one subnet per region already provides full multi-zone coverage.
The global scope introduces a trade-off that experienced architects should account for immediately: blast radius. A misconfigured firewall rule in GCP applies across all regions simultaneously, whereas AWS’s regional VPC model naturally contains damage to a single region. GCP compensates with a layered firewall architecture. Hierarchical firewall policies, applied at the organisation or folder level, provide guardrails that project administrators cannot override. Below these sit network firewall policies (global or regional, attachable to multiple VPCs) and the legacy per-VPC firewall rules that most teams start with. The evaluation order is strict: hierarchical policies run first, followed by network firewall policies and legacy VPC rules. A unique goto_next action in hierarchical policies allows controlled delegation: security teams can enforce organisation-wide blocks at the top of the hierarchy while permitting application teams to manage service-specific rules at the project level.
For AWS architects, the relevant mapping is: hierarchical firewall policies approximate AWS Firewall Manager in function. There is no GCP equivalent of NACLs; there is no stateless subnet-level filter. GCP firewall rules target VMs using network tags or service accounts rather than attaching to interfaces the way Security Groups do. For Azure architects: hierarchical policies map loosely to Azure Firewall Policy at the hub, but with global scope rather than regional deployment. This is a meaningful difference when you are used to designing per-region security perimeters.
Shared VPC: Centralised Network Ownership at Scale
Shared VPC is GCP’s answer to the fundamental enterprise networking challenge of separating network ownership from workload ownership. One GCP project is designated as the host project, which owns the VPC networks, subnets, routes, and firewall rules. Other projects become service projects and deploy their compute workloads (VMs, GKE clusters, Cloud SQL instances, Cloud Run services) into the host project’s subnets, using the host project’s network as though it were their own.
The access model works at the subnet level, not the VPC level. A Shared VPC Admin can share subnet A without sharing subnet B in the same VPC, which means network access governance is granular by region and by team. The compute.networkUser IAM role, granted at either the project or individual subnet scope, determines which service project principals can deploy into which subnets. Google recommends granting at the subnet level for least privilege, and because subnets are regional, this simultaneously controls which regions a team can use without additional policy configuration.
The IAM structure cleanly separates four sets of responsibilities. The Shared VPC Admin holds compute.xpnAdmin and is responsible for enabling host projects and attaching service projects. The Network Admin holds compute.networkAdmin and manages the subnets, routes, and VPN or Interconnect gateways within the host project. The Security Admin holds compute.securityAdmin and controls firewall rules. Service project teams receive compute.networkUser on their allocated subnets and retain full control over their own compute resources. The critical property of this model is that service project administrators cannot create or modify firewall rules on the shared VPC; firewall governance remains exclusively with the host project’s Security Admin.
This matters operationally. Network resource quotas such as firewall rules, routes, and subnets count against the host project. Compute quotas such as VMs and IP addresses count against the service project deploying the resource. Billing follows the service project. The VPC peering limit of approximately 25 connections per VPC is irrelevant here because Shared VPC uses a single VPC, meaning all service projects share the same network without creating peering relationships.
The closest AWS analogue is VPC subnet sharing via Resource Access Manager, where an owner account shares subnets with participant accounts within the same AWS Organisation. The structural parallel is genuine: both share at the subnet level, both centralise network ownership, and both allow participants to deploy resources into shared subnets. The meaningful difference is that AWS participants can manage their own Security Groups on shared subnets, whereas GCP service projects have no firewall rule authority at all. GCP provides stricter centralised governance by design, but this can create bottlenecks if the platform team cannot respond quickly to application team requests for new firewall rules, a real operational consideration when evaluating the model.
Azure architects looking for an equivalent will not find one. The closest pattern is hub-spoke with VNet peering, where shared infrastructure lives in the hub. But Azure spokes require bidirectional peering configuration, route tables with user-defined routes, and explicit gateway transit settings. Shared VPC eliminates all of this: service projects deploy directly into existing subnets with no additional network configuration. Think of it as allowing spoke subscriptions to place workloads directly into the hub VNet’s subnets, with no peering required.
Shared VPC makes sense when a central platform or networking team manages infrastructure for multiple application teams, when consistent firewall and routing policy across projects is a requirement, and when hybrid connectivity should be provisioned once and shared rather than configured per team. Use standalone VPCs instead when complete isolation is mandated by regulation, or when a single-team, single-project deployment makes shared infrastructure unnecessary overhead.
See the GCP Landing Zone Setup guide for how Shared VPC fits into the broader GCP landing zone design, including folder structure, org policies, and the IAM hierarchy that supports it.
Network Connectivity Center: Replacing the Peering Mesh
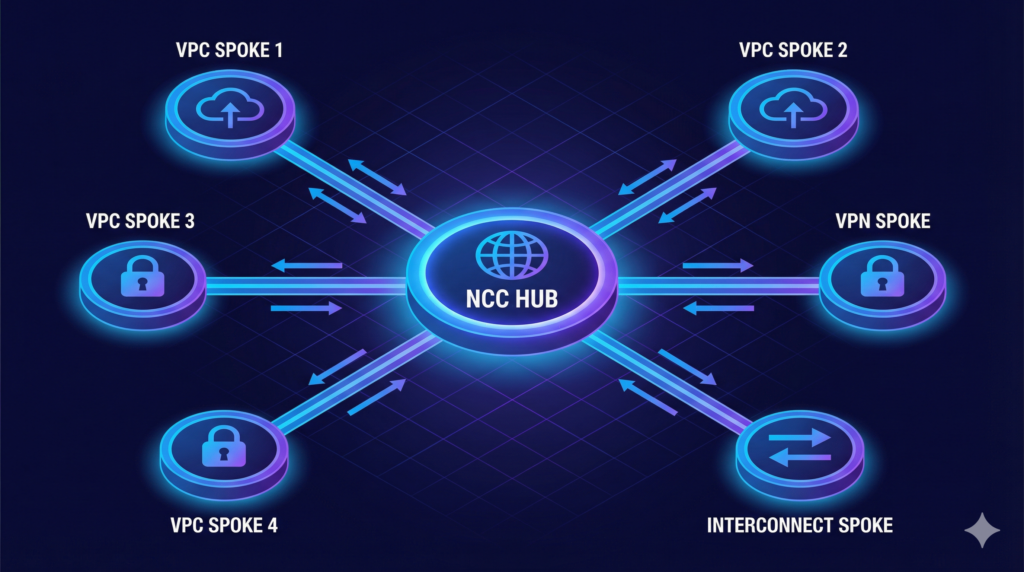
Network Connectivity Center is GCP’s hub-and-spoke orchestration framework, built around a single global hub to which multiple spokes connect, enabling transitive connectivity and centralised route management without the combinatorial peering problem. The hub is a single global resource. There are no regional hub instances to deploy and interconnect. This design reflects GCP’s global VPC model, and it is one of the places where NCC’s architecture is meaningfully simpler than its AWS and Azure counterparts.
NCC supports five spoke types. VPC spokes connect VPC networks to the hub for route exchange, supporting up to 250 VPCs per hub. Hybrid spokes represent on-premises connectivity via Cloud Interconnect VLAN attachments, HA VPN tunnels, or router appliance instances (third-party Network Virtual Appliances such as Cisco Catalyst 8000V). Producer VPC spokes make managed services consumed via Private Services Access, such as Cloud SQL, transitively reachable across the hub. NCC Gateway spokes enable third-party Security Service Edge insertion for traffic inspection, currently in Preview. VPC spokes, hybrid spokes, and producer VPC spokes are all generally available.
When creating a hub, the architect must select an immutable preset topology. Mesh gives full spoke-to-spoke connectivity, meaning every spoke can reach every other spoke. Star creates centre and edge groups: centre spokes communicate with everything, edge spokes communicate only with centre spokes. This topology enables network segmentation at the hub level, with shared services living in the centre group and isolated application environments in edge groups. The immutability of this choice deserves emphasis: the topology cannot be changed after the hub is created. Choosing mesh when star is appropriate, or vice versa, means deleting and recreating the hub. Plan this decision before deploying.
The site-to-site data transfer feature, available on hybrid spokes, is one of NCC’s most commercially significant capabilities. When enabled, dynamic routes learned from one hybrid spoke (for example, a Dedicated Interconnect VLAN attachment in the London Slough facility) are re-advertised to all other hybrid spokes on the same hub (for example, a VPN tunnel connecting a data centre in Manchester). This turns Google’s global fibre network into an enterprise WAN backbone, replacing full-mesh VPN topologies with a single hub. All hybrid spokes using site-to-site data transfer must be within the same VPC network and currently support IPv4 only. Per-GiB charges apply. Route exchange between VPC spokes and hybrid spokes reached GA in January 2025, meaning on-premises networks connected via hybrid spokes can now reach VPC spokes automatically.
AWS Transit Gateway is the most commonly cited comparator, and the architectural differences are worth understanding precisely. AWS TGW is a regional service: a separate TGW is required per region, with inter-region peering configured explicitly between them. NCC’s single global hub covers all regions without additional configuration. For organisations running workloads across multiple regions, this eliminates a meaningful category of management overhead.
The trade-off is routing granularity. AWS TGW supports multiple independent route tables per hub, with fine-grained association and propagation controls that approximate VRF-lite in the cloud. NCC uses preset topologies with export filters, but there is no per-spoke custom route table equivalent. For organisations that need complex route leaking, multiple routing domains, or detailed traffic segmentation between specific spoke pairs, TGW offers more surgical control. Azure Virtual WAN’s Routing Intent feature, combined with Azure Firewall Manager, provides similar granularity on the Azure side. NCC’s security insertion capability via Gateway spokes remains in Preview; teams that require third-party firewall inspection in the data path today will find AWS and Azure more mature options for that specific requirement.
The comparison to Azure Virtual WAN is instructive for teams evaluating GCP as a second cloud. Where Virtual WAN deploys managed router infrastructure per region with automatic hub-to-hub meshing, NCC requires no regional deployment at all. The simplicity advantage is real, but it comes with the trade-off of less granular routing control. Neither is objectively superior; the right choice depends on whether routing complexity or management simplicity is the bigger concern for a given organisation.
Private Service Connect: Service-Oriented Access Without Network Exposure
Private Service Connect is GCP’s model for private connectivity to specific services rather than entire networks. Rather than peering two VPCs and exposing every subnet’s routes, PSC lets a producer expose a single service through a service attachment, and a consumer access that service through an internal IP address that exists within their own VPC. All traffic stays on Google’s network. No internet routing. No IP address coordination between producer and consumer.
The producer/consumer model works as follows. A service producer deploys their application behind an internal load balancer and creates a service attachment that makes it available for PSC access. The producer controls access through accept and reject lists, configurable by project, VPC network, or (since November 2025, in Preview) individual PSC endpoint. A consumer creates either a PSC endpoint or a PSC backend to access the service.
A PSC endpoint is a forwarding rule that maps an internal IP address of the consumer’s choosing to the producer’s service. Traffic to that IP routes directly to the producer. NAT on the producer side means consumer and producer VPCs can have fully overlapping CIDRs without any address coordination. A PSC backend places a consumer-side load balancer in front of the PSC connection, which enables Cloud Armor DDoS protection, custom TLS certificates, URL-based routing, cross-region failover, and centralised logging on the consumer side. This capability has no equivalent in AWS PrivateLink or Azure Private Link, where consumers cannot insert their own load balancing and security controls between the endpoint and the service.
PSC serves three access patterns. PSC for Google APIs lets consumers create endpoints with their own internal IP addresses for accessing services such as BigQuery, Cloud Storage, and Spanner, replacing the need for Private Google Access with more precise routing control. PSC for published services covers the producer/consumer pattern described above, used both for Google’s own managed services (GKE, Apigee, Cloud Composer, Cloud SQL via PSC endpoints) and for customers exposing their own services across project or organisational boundaries. PSC interfaces flip the direction entirely: they allow producers to initiate connections into consumer VPCs, which is essential for managed services that need to pull data from a customer environment. Dynamic PSC interfaces, which can be added or removed from a running VM without restart, reached GA in early 2026.
For architects familiar with Azure Private Link and Private Endpoints, the PSC model will feel recognisable but with several meaningful differences. PSC supports cross-region access via a global access flag and cross-region internal Application Load Balancers, whereas AWS PrivateLink is strictly same-region only. PSC backends give consumers load-balancing control that neither PrivateLink nor Azure Private Link offer. PSC interfaces enable producer-initiated connections, whereas both AWS and Azure private connectivity services are consumer-initiated only.
The trade-offs run in the other direction as well. AWS PrivateLink supports VPC endpoint policies that provide IAM-based resource-level restrictions on what actions can be performed through an endpoint; PSC has no direct equivalent, relying on VPC Service Controls for perimeter-based enforcement instead. DNS handling requires more explicit configuration on GCP: AWS automatically creates Route 53 records for PrivateLink endpoints, while PSC requires manual Cloud DNS private zone configuration. The 20-minute TCP idle timeout on PSC connections is not configurable. Teams running long-lived database connections through PSC endpoints need application-level keepalives or connection pool settings that respect this limit, a detail that catches teams by surprise.
One operational consideration specific to producing services via PSC: the NAT subnet. Producers must create dedicated subnets with purpose=PRIVATE_SERVICE_CONNECT, sized at a minimum of /24, with at least one IP available per 63 consumer connections. Undersized NAT subnets cause connection failures at scale. This is not a limitation that maps to anything in PrivateLink or Azure Private Link, so AWS and Azure architects who have not read the GCP-specific documentation tend to miss it.
PSC propagation through NCC reached GA in February 2025. This means a PSC endpoint created in one VPC spoke automatically becomes accessible from all other VPC spokes on the same hub, eliminating per-VPC endpoint duplication across large environments. Combined with NCC’s hybrid spoke support, PSC endpoints are also reachable from on-premises networks connected via Interconnect or VPN.
How the Three Services Compose
In a well-designed GCP enterprise network, each service occupies a distinct layer. Shared VPC provides the foundational network plane: typically one Shared VPC per environment (production, non-production, data, and so on), managed by a central platform team in host projects, with application teams operating as service projects. NCC acts as the connectivity layer linking these Shared VPCs, connecting on-premises networks via hybrid spokes, and enabling transitive routing between environments where required. PSC provides the service access layer: consuming Google APIs privately, exposing platform services to other parts of the organisation without VPC peering, and enabling cross-organisation service access for multi-tenant SaaS scenarios.
Google’s official landing zone network guidance offers four design options that progress in sophistication. Option 1 (a Shared VPC per environment) is the standard starting point and sufficient for most organisations beginning their GCP journey. Option 2 adds NCC for cross-VPC and hybrid connectivity with centralised inspection appliances. Option 3 uses NCC VPC spokes for transitive routing without appliances. Option 4 builds a PSC consumer/producer model for service-oriented architectures where teams publish and consume internal services independently. The maturity progression follows naturally: Shared VPC first for governance, NCC when multi-VPC or hybrid connectivity becomes necessary, PSC when service-level access control or cross-organisation connectivity is required.
For teams comparing this to Azure’s approach, the Azure Networking Architecture post covering hub-spoke versus Virtual WAN versus Azure Virtual Network Manager shows the equivalent decision space on the Azure side. The broad structure is similar (a network plane, a connectivity layer, and a service access layer) but the implementation mechanics differ substantially, and carrying the Azure implementation mindset into GCP design is a reliable way to create unnecessary complexity.
Cost Considerations
NCC’s cost model has several components that do not appear in Shared VPC or standalone VPC designs. Standard cross-region traffic within a VPC costs the same with or without NCC; what NCC adds is the site-to-site data transfer charge for hybrid spoke traffic using Google’s backbone as a WAN. This per-GiB charge applies when traffic transits between hybrid spokes, and it is additional to the Interconnect or VPN tunnel costs already incurred. For organisations replacing full-mesh VPN topologies with NCC, the operational savings in reduced tunnel count and management overhead frequently offset the data transfer cost, but this requires modelling against actual traffic volumes before committing.
Shared VPC itself has no direct service charge. Costs arise from the network resources deployed in the host project (subnets, VPN gateways, Interconnect VLAN attachments, NAT gateways), which would exist regardless of whether Shared VPC or standalone VPCs were used. The centralisation benefit is that a single Interconnect connection can serve all service projects rather than requiring per-project hybrid connectivity.
PSC endpoint costs are per-endpoint per hour, plus per-GiB data processing charges. For organisations consuming a small number of Google managed services, the cost is minimal. For large platforms consuming many services across many projects, and prior to PSC propagation through NCC being available, the cost of maintaining per-VPC endpoints for each service could accumulate. PSC propagation, where one endpoint in a common services VPC serves all VPC spokes on the same NCC hub, reduces this significantly and is now the recommended architecture for multi-project environments.
The hidden cost category that catches most teams is egress. Cross-region traffic within a GCP VPC travels over Google’s internal network without internet routing, but it is not free. Architects arriving from Azure, where VNet-to-VNet peering traffic is billed at the same rates regardless of the networking topology, will find GCP’s per-GiB cross-region charges similar. The key difference is that GCP’s global VPC means you never need to pay for a transit service just to route between regions; the network is already global.
Decision Framework
The trigger for adopting each service is distinct, and the order in which they are adopted reflects natural organisational maturity. Shared VPC is the right choice whenever multiple teams need a shared network managed centrally; the practical threshold is roughly five or more projects that need to communicate with each other or with on-premises systems. Without Shared VPC, each project must manage its own network configuration independently, and any shared connectivity (Interconnect, VPN, NAT) must be duplicated per project.
NCC becomes necessary when Shared VPC alone is not enough to solve the connectivity requirement. The specific triggers are: needing to connect more than a handful of Shared VPCs with transitive reachability, needing to share on-premises hybrid connectivity across multiple VPCs, needing to propagate PSC endpoints across a large multi-VPC environment, or needing to replace a full-mesh VPN topology connecting branch offices or data centres. If the requirement is purely connecting a handful of projects within a single Shared VPC, NCC adds no value; the single VPC already handles it.
PSC is the right service when the requirement is service-level access rather than network-level access. The practical triggers: consuming Google managed services (BigQuery, Cloud SQL, Spanner) without internet-routable traffic, exposing an internal platform service to other teams or organisations without creating peering relationships, enabling multi-tenant SaaS architectures where tenants should not share network space, or accessing services across organisations where Shared VPC cannot be used.
When evaluating whether to use PSC or VPC peering for a given connectivity requirement: if the requirement is accessing a specific service endpoint, PSC. If the requirement is full bidirectional network reachability between two VPCs, VPC peering or NCC VPC spokes. If the VPCs have overlapping CIDRs (which makes peering impossible), PSC is the only practical option.
Implementation Roadmap
The most reliable approach to GCP enterprise networking is to establish the foundation before connecting workloads, rather than retrofitting network architecture around already-deployed resources.
Phase 1: Foundation (Months 1-3)
The first phase establishes the host project structure and Shared VPC configuration. This involves deciding on the number of Shared VPCs (typically one per broad environment category) and designing the subnet CIDR scheme with headroom for future service projects. Critically, this is the time to switch all VPCs from auto-mode to custom-mode and delete the default VPC from every project. Auto-mode VPCs cannot peer with other auto-mode VPCs and use fixed CIDR ranges that create conflicts at scale. Hierarchical firewall policies should be written at the organisation level before any project teams begin deploying workloads; establishing the baseline security posture is far easier before workloads exist than after. Hybrid connectivity via Cloud Interconnect or HA VPN should be configured in the host project so that all service projects inherit it automatically.
Phase 2: Connectivity Expansion (Months 4-9)
Once Shared VPC is operational across all environments, the second phase introduces NCC for cross-environment and hybrid connectivity. The hub topology decision (mesh or star) should be made here based on whether full spoke-to-spoke reachability is required or whether environment segmentation is preferred. VPC spokes for each Shared VPC are added to the hub, replacing any existing VPC peering relationships between environments. Hybrid spokes are configured to replace full-mesh VPN topologies where they exist. PSC endpoints for Google managed services are centralised in a common services VPC and propagated across the hub via NCC PSC propagation.
Phase 3: Service Mesh Maturity (Months 10-18)
The third phase extends the architecture to cover inter-team and cross-organisation service publishing via PSC. Platform engineering teams publish internal services as PSC services, enabling application teams to consume them without peering relationships or shared network space. For UK-regulated workloads with data residency requirements, VPC Service Controls perimeters are configured around sensitive data services in europe-west2, with org policy constraints restricting resource creation to approved regions. Hierarchical firewall policies are reviewed and refined based on six to nine months of operational data from Firewall Insights.
Looking Ahead
GCP’s networking roadmap points towards increased security insertion capability in the data path. NCC Gateway spokes, currently in Preview, are the mechanism for inserting third-party Security Service Edge and SSE appliances into spoke traffic without architectural redesign, a capability that AWS and Azure have offered for longer. When this capability reaches GA, it will close one of the most significant gaps between NCC and AWS Transit Gateway for organisations with third-party inspection requirements.
PSC’s producer-initiated connection model via PSC interfaces is expanding into more managed service categories. The pattern of managed services using PSC interfaces to access customer data, rather than requiring customers to expose data over the internet or configure complex private connectivity, will become the standard deployment model for regulated-data analytics workloads. This direction aligns with the data sovereignty requirements that UK and EU enterprises face under UK GDPR and NIS2.
The convergence of NCC and Cloud NGFW is worth watching. Cloud Next Generation Firewall Enterprise, with its zone-based firewall endpoints and packet intercept technology, can inspect traffic without requiring route re-architecture. Combined with NCC’s centralised connectivity model, this points towards a future where enterprise-grade L7 inspection is available across the full NCC topology without needing third-party appliances. For organisations currently designing their GCP network foundation, building on NCC from the outset means this capability can be adopted without architectural rework when it reaches maturity.
For multi-cloud environments combining GCP with AWS and Azure, the architecture pattern described in Mastering Multi-Cloud Strategy with Google Anthos provides the workload connectivity layer that sits on top of the GCP networking foundation covered here.
Strategic Recommendations
For architects evaluating GCP networking for the first time: start with the mental model reset. The global VPC is not a quirk or a limitation; it is a deliberate design choice that eliminates entire categories of cross-region plumbing work. Teams that internalize this early design far more scalable architectures than those who spend months trying to replicate per-region patterns.
Adopt Shared VPC before your first service project deploys workloads. Retrofitting it after the fact is possible but painful: it requires migrating VM network interfaces, re-creating GKE node pools, and coordinating downtime across teams. The sequence of foundation before workloads is the most common piece of advice from teams who have completed GCP enterprise network design and the most commonly ignored by teams in a hurry to show progress.
Plan the NCC topology before creating the hub. The mesh-versus-star decision is permanent. Most enterprises with more than two or three Shared VPCs benefit from a star topology where shared services (inspection appliances, PSC common services, hybrid connectivity) live in the centre group, and workload environments sit in edge groups with spoke-to-spoke traffic flowing through the centre.
For UK-specific deployments: europe-west2 (London) provides three zones and full service coverage including GPU instances, with Dedicated Interconnect available at Equinix Slough (LD5). A 99.99% Interconnect SLA requires connections in two metropolitan areas, typically London plus a European metro. There is currently no second UK region, which means any DR design that requires UK-only data residency must achieve resilience through multi-zone deployment within europe-west2 rather than multi-region failover. Clarify with your compliance and legal teams whether this is acceptable under your specific regulatory framework before committing to a DR architecture.
The three services are not competing options; they are complementary layers. Shared VPC for network ownership. NCC for connectivity orchestration. PSC for service access. Understanding where each one applies, and in what sequence to adopt them, is the core of sound GCP enterprise network architecture.
Useful Links
- Google Cloud VPC documentation
- Shared VPC overview and provisioning guide
- Network Connectivity Center overview
- NCC preset connectivity topologies (mesh and star)
- Private Service Connect overview
- PSC propagation through NCC
- Best practices and reference architectures for VPC design
- Implement your Google Cloud landing zone network design
- Hierarchical firewall policies
- Resiliency with Network Connectivity Center (Google Cloud Blog, September 2025)