Cloud-mature organisations learn this slowly. The IaC pipeline runs cleanly, the resource exists, the deployment succeeds, and everyone moves on to the next sprint. What does not move with them is the operational context: who knows how this service behaves under load, who gets paged when it fails, who is accountable for what it costs next month. Those questions do not answer themselves, and the assumption that deployment creates ownership is one of the more persistent sources of operational debt in engineering organisations that have been doing cloud for several years.
This is not a beginner mistake. It becomes visible precisely when teams have matured enough to have automated deployments, platform abstractions, and self-service infrastructure. The faster and smoother the deployment process, the easier it is to skip the conversation about what happens after the pipeline runs green.
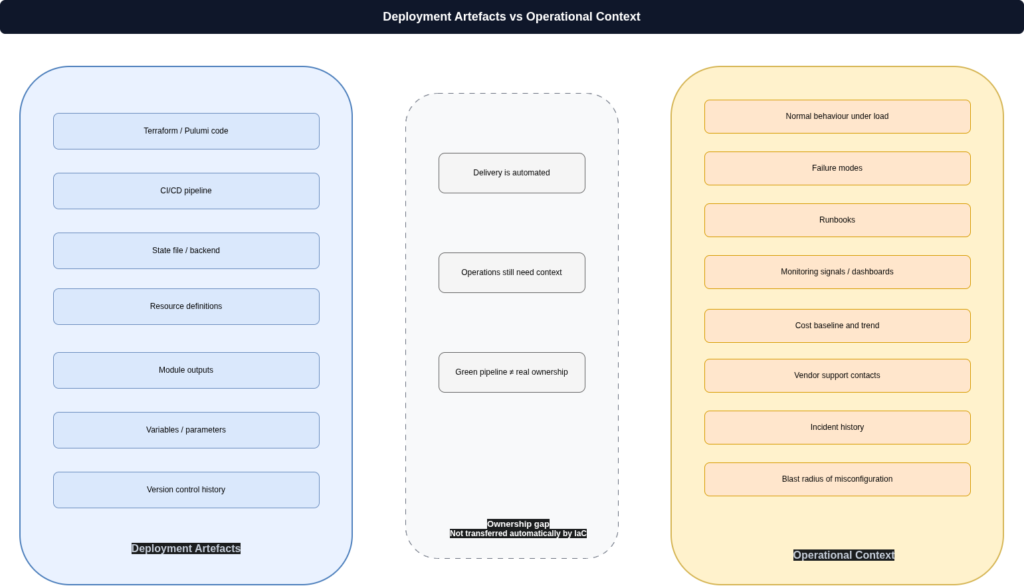
The IaC pipeline does not transfer operational context
When a team uses Terraform or Pulumi to provision a service, the code that created it lives in source control, the state is somewhere managed, and the pipeline ran green. None of that tells anyone how the service fails, what normal looks like in CloudWatch or Azure Monitor, what the expected cost trajectory is, or what the blast radius of a misconfiguration might be. Those things require human context that does not travel with a pull request. Terraform CI/CD automation is valuable for consistency and repeatability, but it is infrastructure delivery, not operational ownership. Conflating the two means the platform team ends up as first responder to incidents on services they created but do not operate, because nobody else has enough context to act.
“You build it, you run it” is frequently declared and rarely implemented
Most engineering organisations have made some version of this statement. Product teams own services. Platform teams own the infrastructure layer. The model sounds right. In practice, the operational context required to actually run a service in production is almost never transferred alongside the deployment tooling. Teams inherit a Terraform module and a pipeline. They do not inherit the incident history, the known failure modes, the vendor support contacts, or the reasoning behind architectural decisions that are no longer obvious from the code. The result is teams that are nominally accountable for a service they do not fully understand. When something goes wrong, they start from a worse position than the team who built it, and the organisation pays the cost of that gap.
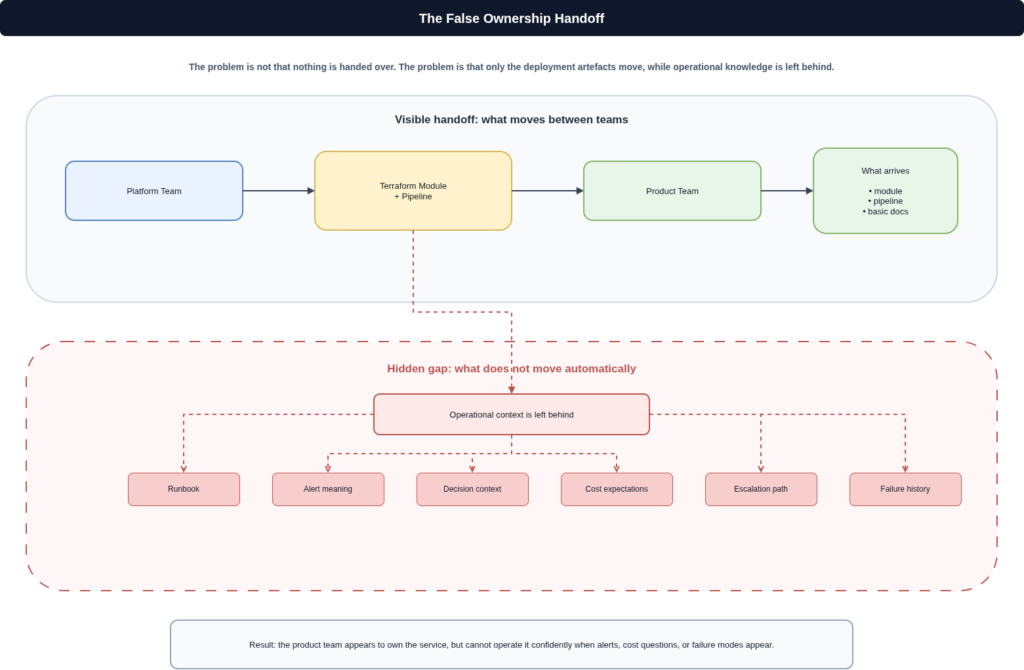
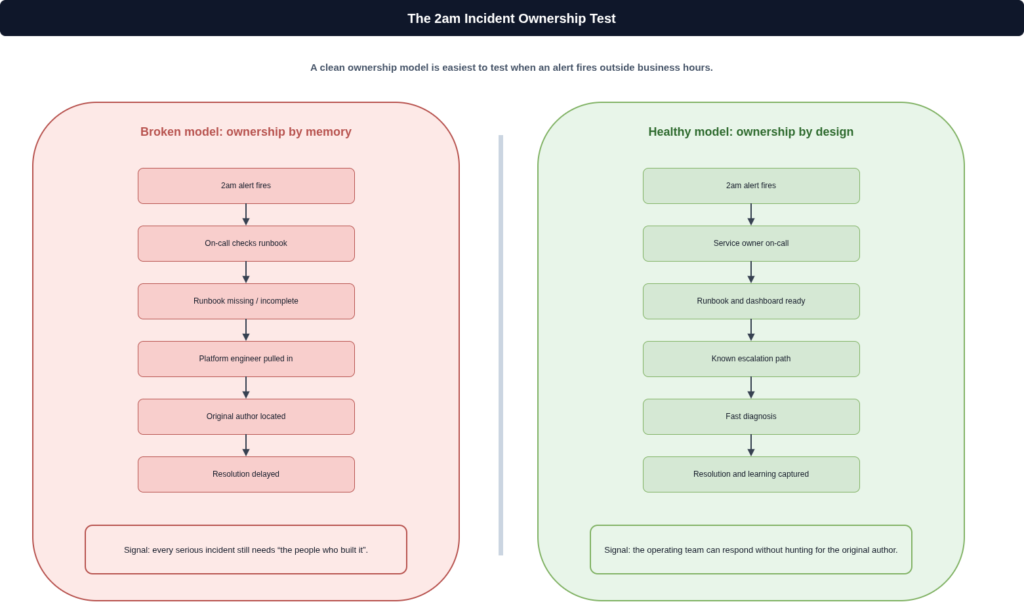
Incidents reveal the real ownership model
The clearest test of whether ownership is real is what happens at 2am when something breaks. In organisations where deployment and ownership have been confused, the person paged is frequently whoever last touched the infrastructure code, not whoever operates the service. That is not an on-call strategy; it is the absence of one. Incidents pull back the coverage and show you what was actually documented, what runbooks exist, and who actually understands the system. If the answer to every incident that crosses a platform boundary is “let us get the people who built it on a call,” the ownership model is not working. This applies regardless of whether your infrastructure is single-cloud or spread across platforms: the Terraform Multi-Cloud Module Design post covers how module structure affects cross-team boundaries, but the design question and the operational accountability question are separate problems, and treating them as one resolves neither.
Cost accountability is the most reliable signal
If the team that deployed a service is not the team responsible for its monthly bill, the ownership model is incomplete. Cloud unit economics requires someone to be accountable for the cost of running a workload. That accountability cannot sit with a platform team that does not control the usage pattern of the service. When cost ownership and operational ownership are misaligned, the result is neither team having the full picture. Platform teams optimise for infrastructure efficiency without understanding the workload behaviour. Product teams optimise for throughput without understanding the cost consequences. The numbers in your billing dashboard start to look like someone else’s problem, and nobody acts on them with enough authority to make a difference.
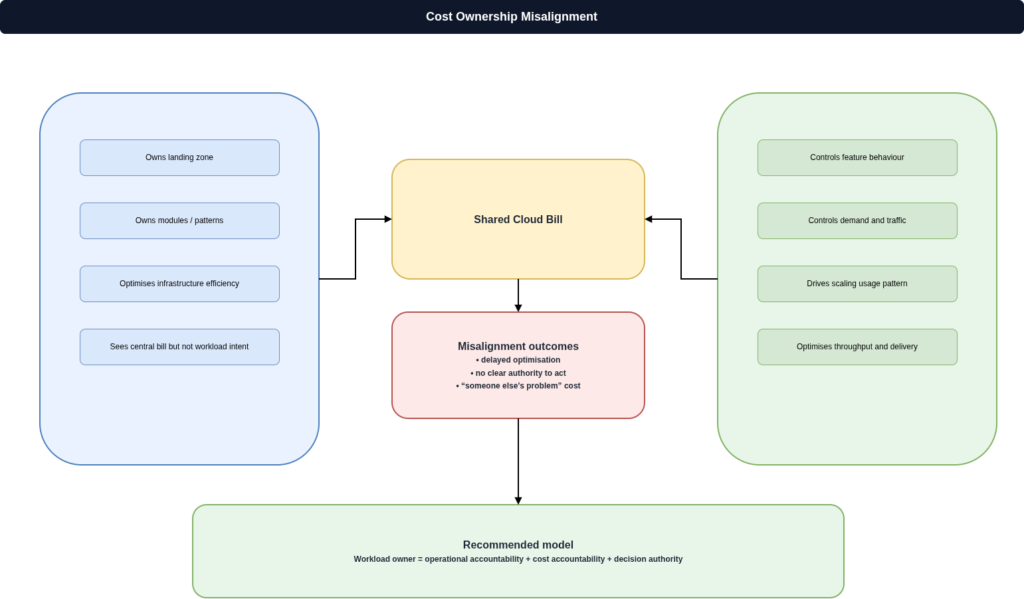
The ownership gap does not close by itself
For every cloud service in production, three things should be explicitly named: who is operationally accountable, who holds the cost accountability, and who has the knowledge to respond to an incident without needing to locate the original author of the code. These are not always the same team, and they are not automatically inherited from the deployment pipeline. If your organisation cannot answer those questions for a material number of production services, the gap between deployment and ownership is already costing you in incident response time, in cost optimisation that nobody can action, and in operational knowledge that walks out the door when engineers leave.
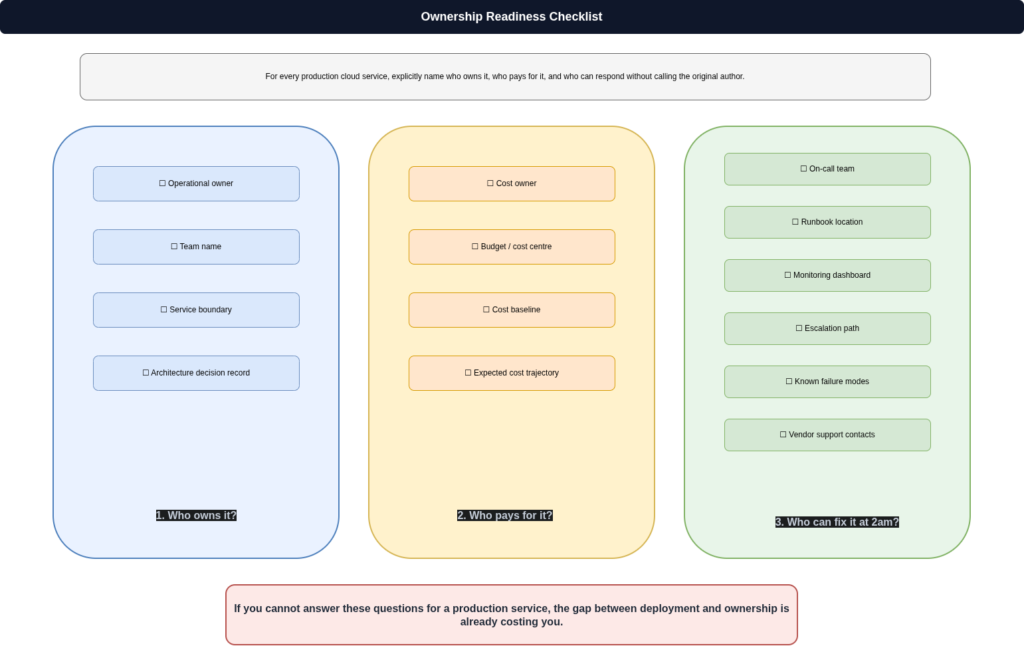
The deployment pipeline is the part that is easiest to automate. Ownership is the harder problem, and it does not get solved by making deployments faster.