
The number that should make you pause is 22%. That is the proportion of engineering leaders and developers who scored in the critical burnout range when LeadDev surveyed 617 practitioners using the Maslach Burnout Inventory for their 2025 Engineering Leadership Report. A further 24% came in at moderate. Put those two together and nearly half the field is in the amber or red zone at any given moment. In UK tech, Harvey Nash’s 2025 Digital Leadership Report puts a different number on the same problem: 44% of tech workers plan to leave their current role in the near term. That is not a recruitment trend. It is the statistical footprint of an industry consuming itself. If you have been carrying that low-grade sense of running hot for the past six months and blaming yourself for it, the data suggests you are not unusual. You are just being quiet about something a very large number of your peers are also experiencing.
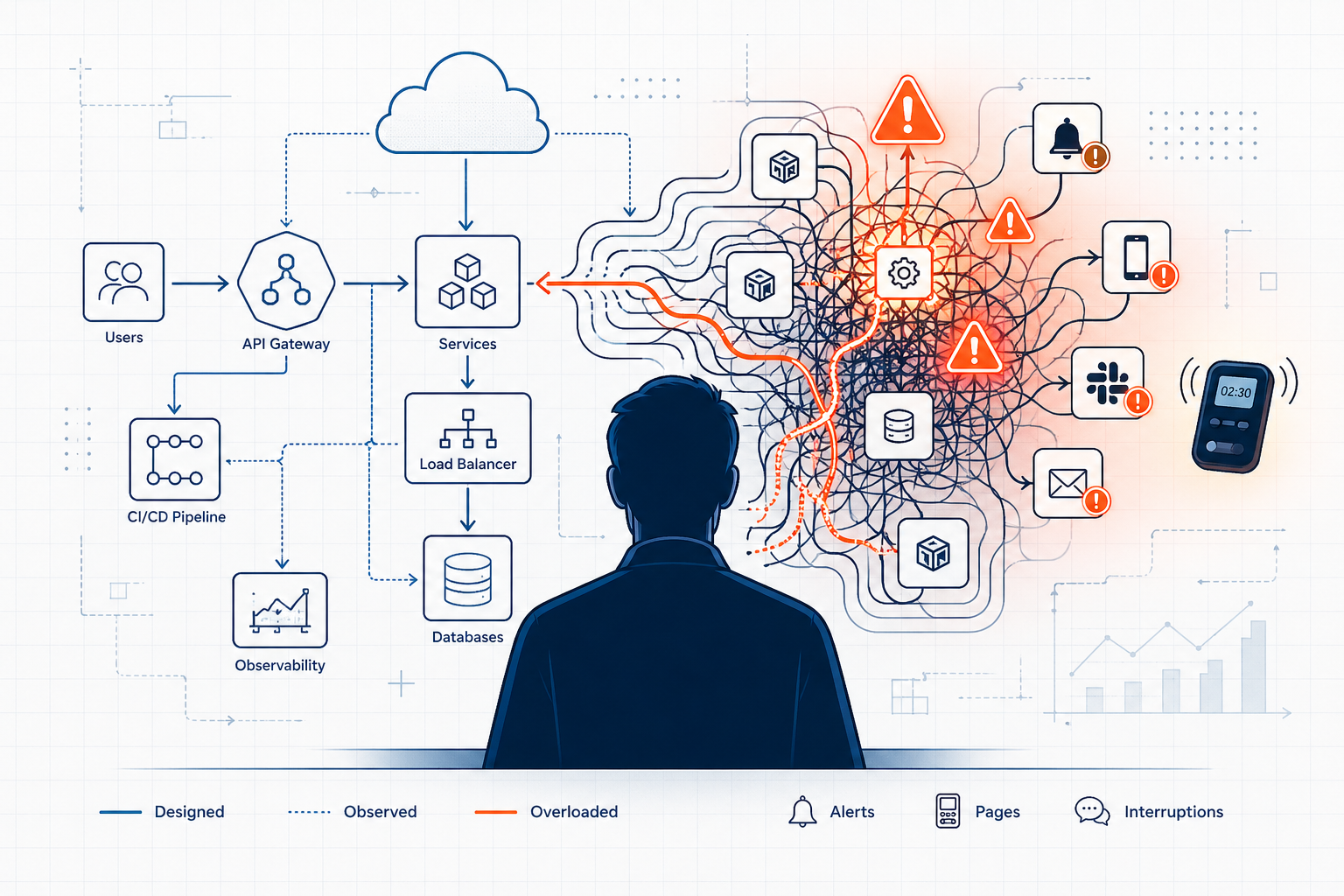
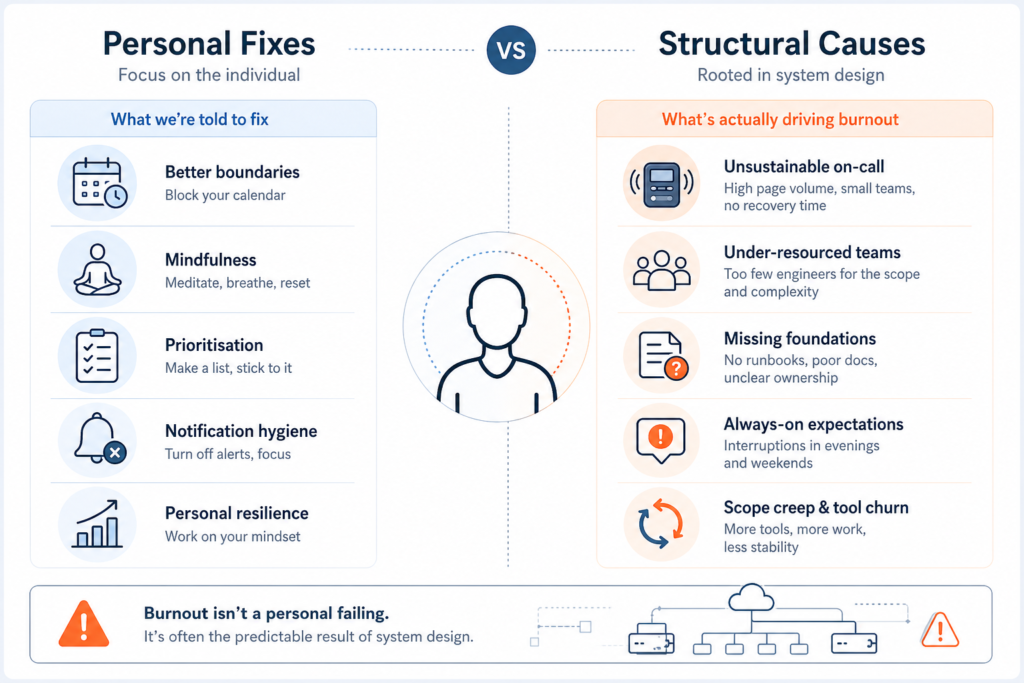
The standard response to burnout discourse in tech circles is to treat it as a personal failure of resilience, prioritisation, or self-awareness. “You should set better boundaries.” “Have you tried blocking your calendar?” “Have you thought about mindfulness?” This framing is wrong, and for senior cloud engineers it is particularly damaging, because it places the corrective action on the individual while leaving the structural conditions completely unchanged. You can meditate every morning and still be on a three-person on-call rota covering a system with seventeen services, fielding pages at 02:30 UK time for a US product team that launched without runbooks. The problem in that scenario is not your inner state. It is the rota design, the team size, the absence of documentation standards, and the implicit expectation that your professionalism means absorbing whatever the system cannot contain. None of those are fixed by a productivity app.
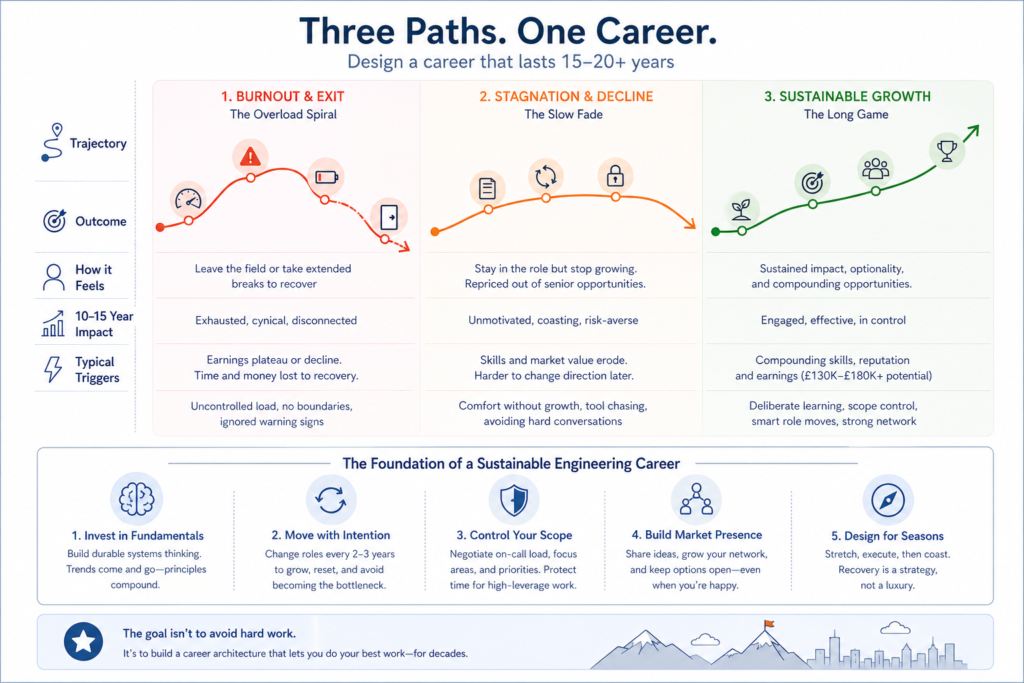
This post argues that burnout in cloud engineering and platform roles is primarily a structural problem, that the structural fixes are largely within your negotiating power as a senior IC, and that understanding the career longevity picture should change how seriously you treat this in your next quarter planning cycle. Engineers who get this right early sustain £90K-£150K+ careers across fifteen to twenty years. Engineers who do not tend to either leave the field entirely or drift into a kind of disengaged tenure in which they are nominally present and increasingly ineffective. Neither outcome is good. The structural intervention is cheaper and more reliable than the recovery.
Why This Discipline Breaks People Differently
Burnout is well-documented in the general literature, with the Maslach three-dimensional model (emotional exhaustion, cynicism, and reduced personal efficacy) classified by the WHO in 2019 as an occupational phenomenon. Cloud engineering produces all three, but it does so through mechanisms that are specific to the discipline and that do not appear in generic workplace wellbeing guidance.
The primary structural variable is on-call rota design, and the primary source for what good looks like is the Google SRE Book. The guidance there is unusually precise. On-call should consume no more than 25% of an SRE’s working time. No shift should experience more than two paging events, each requiring active response, in a twelve-hour window. The minimum viable team for a single-site rotation is eight people. Anything below these thresholds produces what the SRE Book calls “operational overload,” and it compounds. The Catchpoint 2025 SRE Report found median operational toil rising from 25% to 30% of SRE time for the first time in five years, and 46% of respondents reporting more than five active-response incidents in the last thirty days. Most UK platform teams at scale-ups, and many in regulated industries where teams contracted after the 2022 wave of layoffs, are running well below the eight-person threshold and well above the two-incidents-per-shift ceiling. They are not managing a sustainable operating model. They are managing a slow emergency.
The always-on tooling problem compounds this. A PagerDuty notification on your phone, a Slack green dot that the team reads as “available,” a standing expectation that you will look at the alert that comes in at 21:15 on a Tuesday: none of these are neutral. PagerDuty’s own 2021 State of Digital Operations data found that off-hours interruptions between 18:00 and 22:00 rose 9% year on year, and that there was a statistically significant correlation between off-hours paging frequency and user attrition from the platform. Translated without the vendor hedging: engineers who are regularly paged outside hours leave their jobs at a higher rate. The mechanism is exactly what you would expect. Cognitive recovery requires sustained uninterrupted time. A 30-minute page at 21:30 does not cost you 30 minutes. It costs you the rest of the evening.
Scope creep in staff and principal roles operates differently from overload at junior levels. Tanya Reilly’s 2019 “Being Glue” essay remains the canonical account of this. The invisible work (onboarding documentation, cross-team coordination, noticing things that dropped, being the institutional memory for systems that pre-date the current team) accumulates on senior individual contributors because nobody else picks it up. Reilly’s warning is specifically about career damage: doing this work without naming it tends to make senior engineers look less productive to performance systems that measure code output, while the work they are actually doing becomes invisible and therefore uncompensated. DORA’s 2024 data adds a distributional dimension: underrepresented respondents reported doing 29% more repetitive work and 24% more burnout than their peers. This is a structural distribution problem, not a concentration of bad luck.
The tooling churn layer sits underneath all of this. DORA’s 2024 report is blunt about the AI adoption cost: a 25% increase in AI tooling adoption correlated with a 7.2% decrease in delivery stability and a 1.5% decrease in throughput. Internal developer platform adoption boosted individual productivity by 8% but correlated with negative 14% change stability and increased burnout from rework. The engineer who has built a career on being the person who figures out the new thing is the one most likely to absorb the cost of every tooling transition invisibly, because that is what they have always been rewarded for doing. According to a February 2025 arXiv study on burnout and instability in software engineering across 411 respondents, emotional exhaustion is the dominant dimension of burnout in the field, rated higher than cynicism or reduced efficacy, and the highest-rated single item is “I feel exhausted at the end of the workday.” The profile maps directly onto the on-call and interrupts load described above.

The Warning Signs High Performers Routinely Miss
The asymmetry that makes burnout particularly dangerous for senior engineers is that the skills which make you effective also make you good at hiding the symptoms. You absorb more load by working harder. The work rewards you for it. Your performance review reflects the output, not the cost. The rebound, when it comes, is sudden and often involves leaving the field entirely.
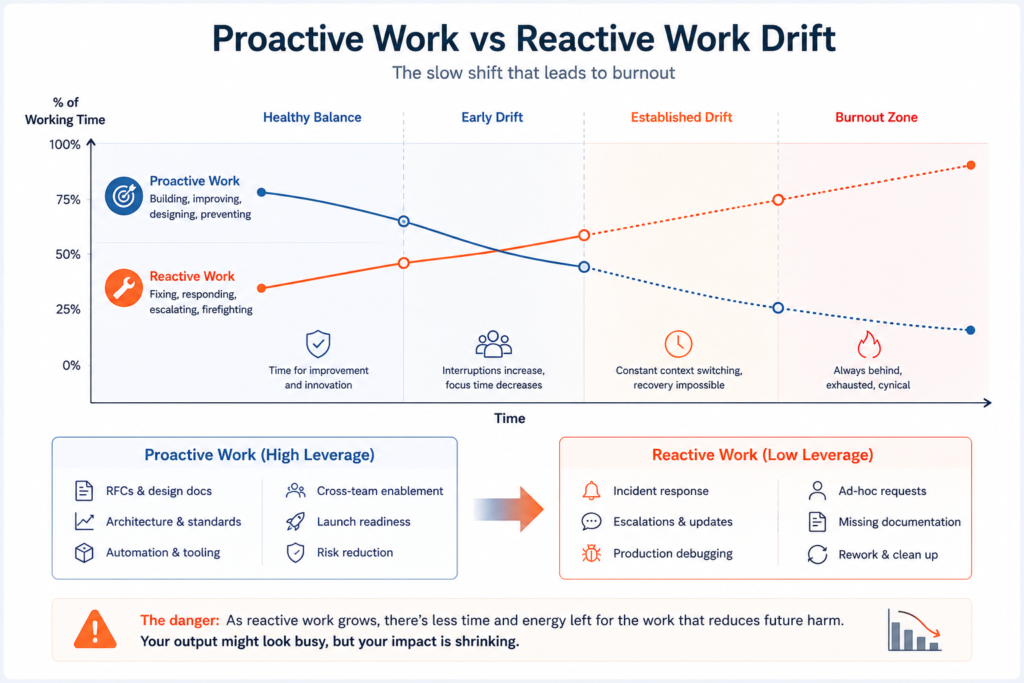
Cynicism tends to arrive before exhaustion becomes visible, and it is worth naming what it actually looks like in practice. You start describing the product management function as “them.” Retrospectives become “theatre.” You stop writing design documents because nobody reads them. You find yourself declining architecture review invitations you would previously have volunteered for. The Google SRE Book makes a distinction that is useful here: proactive work (automation, design consulting, launch coordination, building things that reduce future load) versus reactive work, which is debugging, escalation handling, and incident response. The diagnostic signal for a senior engineer heading towards burnout is the gradual replacement of proactive work with reactive work. When you stop writing RFCs and start only closing tickets, something structural has gone wrong. And because your ticket-close rate goes up, the performance metrics will not catch it.
The decision fatigue manifestation is quieter. The staff engineer who used to push back on scope in sprint planning now approves everything. The tech lead who used to drive architectural standards now defers to whoever spoke last. These are not personality changes. They are the cognitive consequence of a system that has been running near capacity for too long. Gergely Orosz’s framework of stretching, executing, and coasting maps this clearly: stretching is temporarily sustainable, executing is the default, and coasting is healthy as a defined season but dangerous as a permanent state. The warning is specific: “Without a way to relax and get back to normal, mental and physical exhaustion and anxiety can lead to burnout. Even if it’s not burnout, your motivation and output can drop over time, despite you working more than before.”
Senior engineers are structurally at higher risk than junior colleagues, not lower. They hold single-point-of-failure knowledge that routes pages to them disproportionately. They absorb the invisible glue work. Their tenure means that toil has had more years to accumulate. And they have the competence to compensate right up until the point where they cannot. This is the pattern Will Larson describes on career exits: the engineers who describe feeling “reborn” are almost always those who took sabbaticals of six months or longer. The ones who “just pushed through” report a different experience. A related pattern appears at the edges of cloud learning fatigue: the cumulative weight of staying current across a rapidly shifting tooling landscape does not disappear at senior level, it just changes shape from exam pressure to architectural decision overload.
The UK Context in 2026
The UK is a distinct jurisdiction for this conversation, and the received wisdom from US engineering blogs does not transfer cleanly.
The right-to-disconnect proposal that Labour included in its July 2024 manifesto (a Code of Practice modelled on Ireland’s WRC framework) was dropped from the Employment Rights Bill in October 2024, shelved as a Code in March 2025, and formally confirmed as not proceeding via tabled amendments in March 2026. The Employment Rights Act 2025, which came into force on 18 December 2025, contains no switch-off provision. Compare that with France (2017), Ireland (2021), Portugal (2021, with fines up to approximately £8,300 per infraction), Belgium (2022), and Australia (2024). The UK is an outlier among peer economies on this question, and no change is expected in the current parliamentary term.
What does exist, and what most senior engineers have either opted out of or forgotten about, is the Working Time Regulations 1998. The 48-hour weekly average can be opted out of with a simple written agreement, and most engineers in senior roles have signed one. But the daily rest entitlement (11 consecutive hours in every 24) and weekly rest (24 consecutive hours in every seven days) cannot be opted out of by individual agreement. More significantly, post-Brexit UK law retains European Court of Justice case law, including the 2021 rulings in DJ v Radiotelevizija Slovenija and RJ v Stadt Offenbach am Main. These cases established that stand-by time counts as working time in its entirety where response-time requirements and call-out frequency very significantly affect a worker’s ability to manage their free time. A 15-to-30-minute pager response requirement with frequent activations in the evening meets that threshold in most interpretations. That has downstream implications for 48-hour averaging and daily rest compliance that most UK tech employers are not tracking.
The official UK stress data is superficially reassuring and should be read carefully. HSE’s 2024/25 Annual Statistics record 964,000 workers with work-related stress, depression, or anxiety, representing 52% of all work-related ill health. But the Information and Communication sector self-reports below the UK average for work-related stress. This almost certainly reflects selection effects in who remains in the sector at survey time, the salary premium that compensates for load, and higher average autonomy rather than a demonstrably lower stress environment. CIPD’s 2025 Health and Wellbeing at Work report is more useful: only 42% of UK employees report being able to switch off from work when they need to, 23% feel exhausted often or always, and sickness absence has risen to a decade-high 9.4 days per employee. Mental Health UK’s 2025 Burnout Report found 34% of UK adults experience high or extreme stress always or often. The Harvey Nash 44% planning-to-leave figure is probably the most actionable number for this audience, because it captures engineers who have already made a decision even if they have not yet moved.
The Fixes That Are Actually Within Your Power
None of the following is about calendar hygiene or notification settings. These are structural changes that require a conversation, data, and in some cases a direct negotiation.
The most impactful single intervention is fixing the on-call rota, and the most effective way to do it is with the numbers from the SRE Book rather than a subjective complaint about load. The anchor points are: Google’s 50% engineering-work floor and 25% on-call ceiling, the two-paging-events-per-12-hour-shift ceiling, the eight-person single-site minimum, and the 12-hour maximum shift length. These are published, evidence-backed, and widely cited. If your rota breaches any of them, the corrective action is not personal resilience. It is a combination of hiring, shifting operational ownership back to the development team that owns the service, or reducing service scope. Building a 21-day trailing pager-load dashboard (incidents per engineer per week, time-to-resolution, off-hours activation rate) and making it visible in weekly engineering reviews is the fastest way to make the problem legible to people who can do something about it.
Scope needs to be negotiated explicitly and in writing. A one-page role description that breaks down your expected time allocation across IC work, architecture and design, mentoring, operational support, and cross-team coordination creates a shared reference point for subsequent conversations. The tactic Tanya Reilly describes (tracking and publishing your glue-work contribution alongside your code contribution in quarterly reviews) converts invisible load into a negotiable resource. The complementary skill is the ability to decline work that is not yours without damaging relationships. If you cannot do that yet, you have not yet reached the seniority your job title claims, and that gap is worth addressing.
For deep work protection, the useful framing is Paul Graham’s maker versus manager schedule distinction: meetings fragment maker time in a way they do not fragment manager time, and most powerful people in an organisation operate on the manager’s schedule. The practical response is calendar architecture: blocking half-days as committed maker time, clustering 1:1s in late afternoon, and negotiating a team-level meeting-free day that is respected rather than slowly eroded. These are moves that require organisational permission, not just personal discipline.
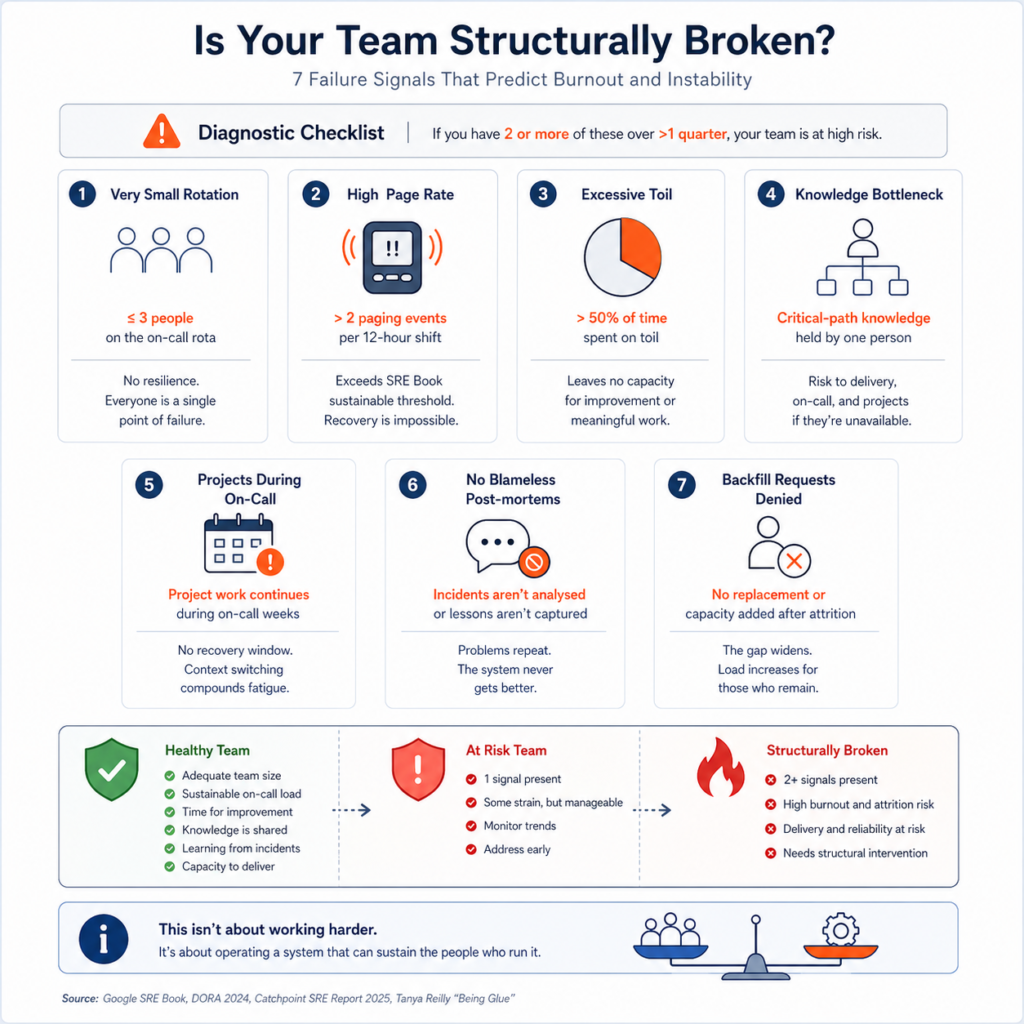
The hardest call is recognising when a team is structurally broken in a way that individual effort cannot fix. The diagnostic checklist is short: a rotation of three people or fewer, sustained page rates above two per shift, toil above 50% of total engineering time, critical-path knowledge held by one person, project work continuing during on-call weeks, no blameless post-mortems, and backfill requests denied after attrition. Any two of these in combination over more than one quarter represents a structural failure. It will not improve because you are more disciplined. Engineers who navigate this well often benefit from the same decision-making framework described in under-pressure high-stakes situations: clear criteria, assessed calmly, before the emotional cost of staying becomes the reason not to leave.
What Long Careers Look Like
The career longevity question is one this industry avoids, partly because it is young and partly because acknowledging that most engineers do not sustain high performance past their mid-forties is uncomfortable. Stack Overflow’s 2024 Developer Survey shows the cohort shifting: 39% of respondents are now 35 or older, up from 31% in 2022, and 38% have been coding for fifteen or more years. The long career is no longer exceptional. The question is what shape it takes.
The burnout-and-exit pattern is the most visible failure mode. Engineers who have absorbed overload past the point of recovery tend to need extended breaks measured in months, not weeks. Gergely Orosz documents this in his writing on Big Tech exits: the people who describe the experience as truly restorative are nearly always those who took six months or longer away from the field. For anyone considering what that looks like financially and strategically, the sabbatical strategy analysis is worth reading in full: the return on a planned break at £90K-£120K is materially better than the return on a reactive one at £65K-£80K after your reputation has been affected by a difficult departure.
The stagnation pattern is quieter and arguably more damaging to long-term earnings potential. Engineers who stop being proactive contributors but retain their titles tend to drift into legacy maintenance roles, lose currency with current tooling, and find themselves repriced out of the senior market in their mid-to-late forties. The difference in lifetime earnings between a sustained staff/principal career (£130K-£180K across fifteen years at the upper end) and a stagnation-to-exit trajectory (£90K-£100K declining in real terms) is material enough to be taken seriously in your current quarter planning.
The engineers who sustain long careers tend to share a small set of recognisable practices. They move roles every two to three years, partly for compensation step-changes and partly to avoid becoming the single-point-of-failure bottleneck who cannot leave without everything breaking. They invest their learning capacity in durable fundamentals (network architecture, systems design, distributed systems theory) rather than chasing every framework cycle. They treat on-call load and scope as negotiable rather than fixed, and they do so with data rather than complaints. And they maintain a professional identity that is not entirely fused with their current employer, which means a market-facing presence, a network that generates options, and a clear sense of what they will and will not accept.
Next Steps
The useful next action after reading this is not motivational. It is a short audit that takes about fifteen minutes and tells you something concrete.
Pull your last 30 days of paging data and calculate incidents per engineer per week. Compare it against Google’s two-per-shift ceiling: if your team is above it, you have a rota problem that can be quantified and taken to your manager this quarter. Write down the actual split of your working time across the last month: IC work, operational response, meetings, coordination, mentoring, and administration. If the IC and proactive-architecture proportion is below 50%, you have a scope problem and the first step is naming it explicitly in your next 1:1. Check your calendar for the last four weeks and count the number of uninterrupted half-days you had for maker work. If the answer is fewer than four across the month, you have a scheduling problem that is solvable with a direct conversation rather than passive calendar management.
None of these take more than a quarter to change if you have data, a clear ask, and a manager who is capable of hearing it. If none of the above changes after a direct conversation backed by evidence, that is also information, and it is the kind of information that should factor into a role decision before the cost of staying becomes too high to recover from quickly.
Useful Links
- Google SRE Book: Being On-Call: the primary reference for on-call load thresholds and rota design
- Google SRE Workbook: On-Call: practical implementation guidance for sustainable rota structures
- Tanya Reilly: Being Glue: the canonical account of invisible senior IC work and its career implications
- Charity Majors: On Call Shouldn’t Suck: a manager-facing but engineer-readable treatment of sustainable on-call design
- DORA 2024 State of DevOps Report: includes 2024 findings on burnout, AI adoption, and platform engineering
- Catchpoint SRE Report 2025: toil and incident load data for the SRE community
- Mental Health UK Burnout Report 2025: UK-specific burnout prevalence data with generational breakdown
- CIPD Health and Wellbeing at Work 2025: UK workforce well being data including switch-off rates and absence figures
- Acas: Working Time Regulations: practical guide to UK working time rights including rest entitlements
- Gergely Orosz: Stretching, Executing, Coasting: the pace framework for long-term sustainable engineering performance






