Most enterprise data lakes are ungoverned by design. Research from Gartner estimates that through 2025, 80% of organisations that have invested in data lakes will fail to realise the expected business value, with poor governance and access control cited as the leading cause. The problem is not the data. It is the permissions model sitting on top of it. Organisations build out S3 data lakes at scale, then try to govern them with a patchwork of bucket policies, IAM roles, and manually maintained ACLs. The result is a system where data access is inconsistent, compliance is unprovable, and the overhead of managing permissions across teams grows faster than the data itself.
The default approach: bucket-level IAM policies applied by data engineering teams on request creates three compounding failures at enterprise scale. Access takes weeks to provision, blocking analysts and slowing product decisions. Audit trails are incomplete or non-existent, making regulatory reporting a manual exercise that consumes weeks of engineering time. And permissions drift: roles accumulate access over time, data assets are rarely deprovisioned correctly, and the security posture of the lake deteriorates quietly while no individual team notices. According to IBM’s Cost of a Data Breach Report 2024, the global average cost of a data breach reached $4.88 million and cloud access misconfiguration is consistently identified as one of the leading technical causes across all breach categories.
AWS Lake Formation addresses this directly by placing a centralised governance layer over S3, Glue, Athena, Redshift Spectrum, and EMR. Rather than managing permissions on each service independently, Lake Formation becomes the single control plane through which all data access is granted, audited, and revoked. Volkswagen Group’s data platform team reported cutting permission provisioning time by 70% after implementing Lake Formation as their central governance layer, eliminating the S3 bucket policy sprawl that had accumulated across 40 data producer teams. This guide covers the architecture, the implementation decisions that matter at enterprise scale, and the comparison with Databricks Unity Catalog for organisations evaluating their governance stack.
The Governance Gap in Enterprise Data Lakes
The evolution from raw S3 storage to a governed data lake follows a predictable pattern. Phase one is ingestion: teams dump data into S3 in whatever format is convenient, organised by team or source system. Phase two is discovery: Glue crawlers map the schema, Athena enables ad-hoc queries, and the lake starts delivering value. Phase three is the governance crisis: data from different sensitivity classifications ends up in the same physical locations, multiple teams need different views of the same datasets, and regulatory requirements demand proof of who accessed what and when.
At this point, most organisations reach for IAM. The instinct is understandable, IAM is what AWS engineers know, and it works well for infrastructure access control. It does not work well for data access control at scale. IAM policies operate at the resource level (S3 bucket or prefix) rather than the data level (table, column, or row). A single S3 prefix might contain five Glue tables with different sensitivity classifications, and there is no clean mechanism to grant access to three of those tables without also granting access to the underlying S3 objects for all five. This limitation forces teams into increasingly complex folder structures that exist purely to mirror the access control requirements, which is both brittle and expensive to maintain.
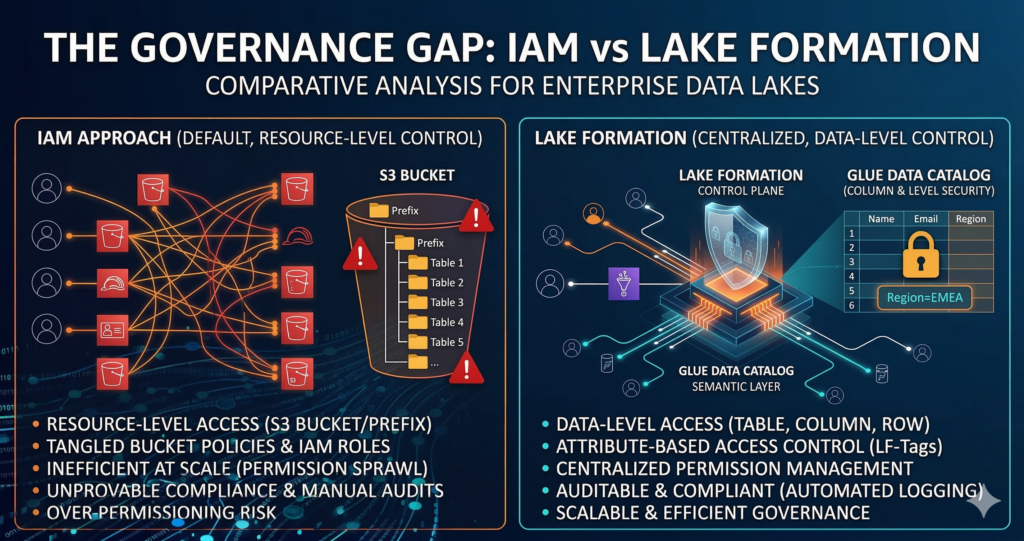
Lake Formation introduces the concept of data permissions that sit above the storage layer. The Glue Data Catalog becomes the semantic layer through which Lake Formation manages access, and permissions are granted at the database, table, column, or row filter level. The underlying S3 objects remain inaccessible to consumers without going through the Lake Formation permission model, which means the access control policy travels with the data asset rather than being tied to a specific storage path.
Lake Formation Architecture: Core Components
The Data Catalog as the Permission Boundary
Lake Formation’s governance model depends on the AWS Glue Data Catalog as its semantic layer. Every database and table registered in the Data Catalog becomes a Lake Formation resource, and Lake Formation acts as the gatekeeper for all access to those resources. When an analyst runs a query in Athena, Athena does not request S3 access directly from IAM, it requests table access from Lake Formation, which validates the permission and provides temporary, scoped credentials for the specific S3 locations backing the requested data.
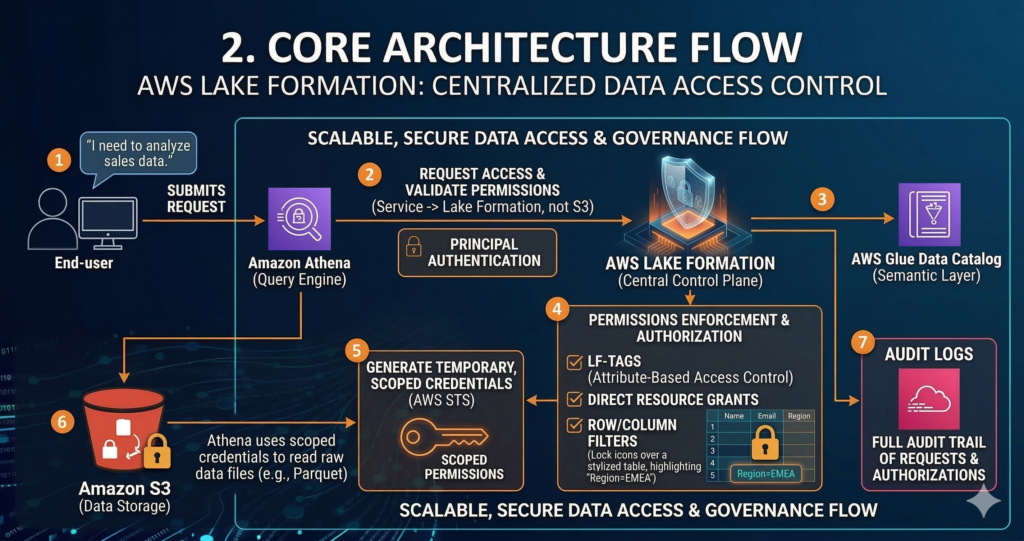
This architecture has an important implication that many teams miss during initial implementation: services must be configured to use Lake Formation permissions rather than S3 IAM permissions. If your Athena workgroup still has an S3 read policy attached to the underlying IAM role, users can bypass Lake Formation entirely and query the raw S3 data directly. Correct Lake Formation implementation requires revoking the IAMAllowedPrincipals grants that AWS adds by default and ensuring that service-level S3 access is removed from all consumer IAM roles. This is the single most common misconfiguration seen in enterprise Lake Formation deployments.
LF-Tags: Attribute-Based Access Control at Scale
Row-level and column-level security in Lake Formation can be managed through two mechanisms: direct resource grants (granting a specific principal access to a specific table or column) and LF-Tag-based access control (TBAC). For enterprises with more than a handful of data producers and consumers, direct resource grants do not scale. Every new table requires a new grant, and every new user or role requires grants across all relevant tables.
LF-Tags solve this by attaching metadata attributes to data assets and granting permissions based on tag values rather than specific resources. A classification tag with values of public, internal, confidential, and restricted applied at the database or table level, combined with a domain tag covering areas like finance, hr, and product, allows a single permission policy to govern access across thousands of data assets. When a new table is created and tagged appropriately, permissions propagate automatically without requiring manual grants to every consumer.
The implementation pattern for enterprise tagging typically involves three to five tag keys covering data sensitivity, data domain, data residency (important for GDPR compliance), and data product lifecycle. Keeping the tag vocabulary small is deliberate – tag sprawl creates the same management overhead that LF-Tags are designed to eliminate. The AWS Control Tower enterprise governance framework should inform your tagging taxonomy, since consistent tag values across infrastructure and data assets simplify compliance reporting significantly.
Column-Level Security and Row Filters
Lake Formation supports column-level security natively, allowing specific columns to be hidden from principals who lack the appropriate permissions while leaving the rest of the table accessible. This capability is particularly valuable for datasets that mix sensitive and non-sensitive fields. A customer table might expose transaction counts and geographic region to analysts while hiding names, email addresses, and payment information behind a separate column permission grant.
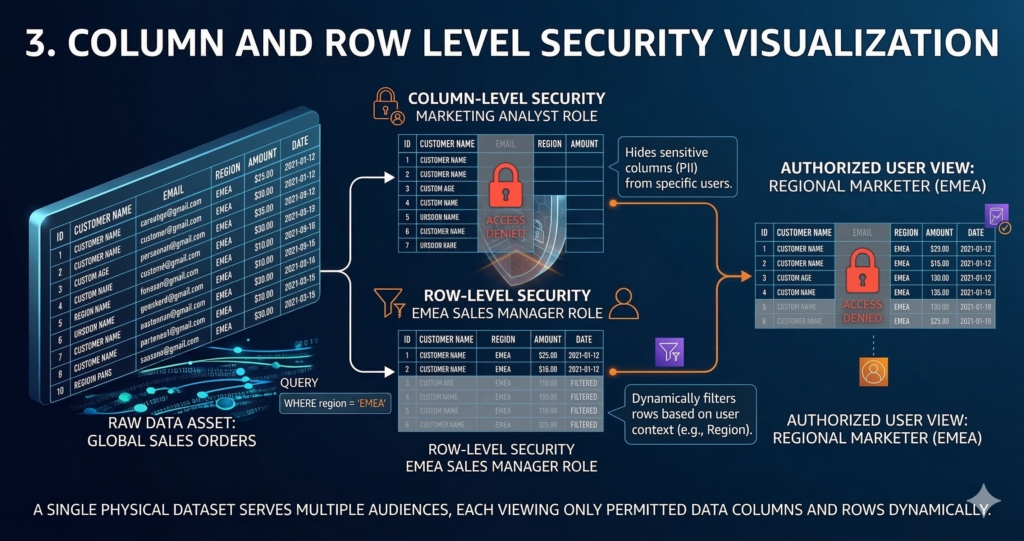
Row filters extend this further, allowing Lake Formation to restrict the rows a principal can see based on a filter expression. A regional sales team might have access to the global orders table, but their Lake Formation row filter restricts results to orders where region = 'EMEA'. The filter is applied before query execution, meaning it is enforced at the service layer rather than relying on the consumer to add the correct WHERE clause. Row filters are defined as expressions attached to the table resource and applied transparently to all queries from principals with that filter grant.
The combination of column-level security and row filters allows a single physical data asset to serve multiple audiences with different access requirements, eliminating the need to maintain separate denormalised copies of datasets for different teams, a significant cost reduction for enterprises running large Redshift Spectrum or Athena workloads. This principle connects directly to the unit economics framework covered in our cloud unit economics guide: reducing data duplication driven by access control requirements is one of the least-discussed but most impactful cost levers in large data platforms.
Cross-Account Data Sharing with RAM Integration
Enterprise data lakes rarely live in a single AWS account. The AWS Control Tower multi-account model separates data by domain, environment, or sensitivity classification across multiple accounts, and Lake Formation handles cross-account access through AWS Resource Access Manager integration.
A data producer account registers its Glue Data Catalog resources with Lake Formation and grants cross-account permissions to specific principals or AWS organisations. The consumer account accepts the RAM share and can then query the shared data through Athena or Redshift Spectrum as if it were local, while the producer account retains full control over the permission grants and can revoke access without coordination with the consumer team. Audit logs from both accounts capture the full chain of access, which is the provenance model that GDPR, SOC 2, and financial services regulators require.
The architecture for a well-governed multi-account data lake typically involves a dedicated governance account running the central Lake Formation configuration, data domain accounts owning their respective S3 data and Glue catalog resources, and consumer accounts querying across domains through cross-account RAM shares. This separation ensures that no single team can escalate their own data permissions, which is a common audit finding in organisations that manage data governance at the account level through IAM.
Lake Formation vs. Databricks Unity Catalog
For organisations evaluating their data governance architecture, Databricks Unity Catalog is the primary alternative to Lake Formation. The two products share similar goals: centralised governance, column-level security, audit logging, and cross-environment data sharing – but differ significantly in architecture and ecosystem fit.
| Capability | Lake Formation | Unity Catalog |
|---|---|---|
| Native AWS integration | Deep (S3, Glue, Athena, Redshift, EMR) | Via external location / Delta Sharing |
| Non-AWS compute support | Limited | Broad (cross-cloud via open source connectors) |
| Column-level security | GA | GA |
| Row-level security | GA (row filters) | GA |
| Attribute-based access control | GA (LF-Tags) | GA (tags, as of Unity Catalog 2024) |
| Cross-account/cloud sharing | Via RAM (AWS) | Delta Sharing (open protocol) |
| Cost | Included in Glue/Athena pricing | Requires Databricks workspace |
| Open table format support | Iceberg, Delta, Hudi (via Glue) | Delta Lake native; Iceberg via UniForm |
Lake Formation’s primary advantage is depth of integration with the AWS-native analytics stack. If your compute layer is Athena, Redshift Spectrum, or EMR, Lake Formation governs access across all three services through a single permission model with no additional licensing cost. The governance is transparent to consumers, they query Athena as normal and Lake Formation enforces permissions without requiring any changes to query tooling or BI connectivity.
Unity Catalog’s primary advantage is portability. A governance policy defined in Unity Catalog can follow data across Azure, GCP, and AWS environments within a single Databricks footprint, and the Delta Sharing protocol allows external tools to consume governed data without requiring Databricks compute. With Unity Catalog now open-sourced, enforcement is broadening to support external runtimes including open-source Spark, Trino, and Presto, though full enforcement outside Databricks runtime typically requires specific open-source connectors rather than working natively. For organisations running a mixed Databricks and open-source Spark estate, Unity Catalog provides more consistent policy enforcement across the full compute landscape than Lake Formation can offer.
The practical decision point is compute footprint. Organisations running primarily AWS-native analytics with Athena, Glue, and Redshift are best served by Lake Formation. Organisations with an established Databricks investment should evaluate Unity Catalog seriously, particularly if they run workloads across multiple clouds or require the Delta Sharing protocol for external data consumers.
Enterprise Case Studies
MOIA (Volkswagen Group) – Mobility Technology
Scale: 20 data teams with individual access requirements; gigabytes of data processed daily from vehicle IoT devices, app interactions, and backend systems; ride-pooling operations across Hamburg and Hanover with 48 average monthly releases.
Challenge: GDPR compliance required granular, role-specific data access across continuously evolving ML model schemas. Each time data engineers redesigned table structures in the Glue Data Catalog, permissions needed to be reassigned manually, an approach that introduced human error and was incompatible with MOIA’s pace of innovation. Without automation, multiple dedicated developers would be required purely for permission administration.
Solution: Automated Lake Formation governance pipeline built on CodePipeline and CloudFormation, updating permissions across all tables including newly created ones on an hourly cycle. Fine-grained column and table access enforced through Lake Formation for 20 distinct data teams covering data analysts, data scientists, and data engineers, each with role-specific access scopes aligned to GDPR requirements.
Measurable Outcomes:
- 1,000 hours of manual permission management work eliminated annually
- 48 average monthly releases supported with governance propagating automatically to new tables and schemas
- GDPR audit trail fully automated through Lake Formation, replacing manual documentation of records of processing activities
- Permission updates to new tables within one hour of schema change, with no manual intervention required
Gilead Sciences – Pharmaceutical
Scale: Global pharmaceutical company with data mesh spanning six core business domains – Pharmaceutical Development and Manufacturing, Commercial, Medical Affairs, HR, Finance, and Business Conduct Compliance – plus external data products through the Gilead Data Marketplace.
Challenge: A fragmented data landscape with monolithic platform approaches that did not scale to enterprise-wide analytics needs. Top-down governance created bottlenecks, data copies across domains increased costs and reduced trust in data, and the organisation lacked the self-serve access model needed to support a data-driven culture across all business functions.
Solution: Data mesh architecture with Lake Formation as the centralised federated governance control plane, enforcing fine-grained access policies across all data domains without centralising data movement. The Gilead-DnA platform provides self-serve data product registration, automated access approval workflows, and data quality scorecards. External data acquisition through AWS Data Exchange is integrated into the same governance model, with Lake Formation managing access to third-party data products alongside internally produced datasets.
Measurable Outcomes:
- Enterprise search application (Morpheus) built on the governed data lake reduced search times by approximately 50%
- Data governance framework operating across six business domains with federated ownership, replacing a central bottleneck model
- Automated compliance tracking through data product scorecards, monitoring quality, classification, and access policy coverage for every published data product
Cost Analysis and ROI
Lake Formation itself carries no direct service charge, permissions management, audit logging, and the Data Catalog integration are included in the existing Glue and Athena pricing. This makes the cost comparison with alternatives primarily a question of operational overhead and the downstream cost of governance failure rather than a direct licensing comparison.
The operational cost reduction from centralised governance is measurable. Data engineering teams at enterprise scale typically spend 15-25% of their capacity on access management. Provisioning permissions, handling access requests, maintaining documentation of who has access to what, and responding to audit queries. Lake Formation with a mature LF-Tag taxonomy reduces this to approximately 5-8% of capacity once the initial taxonomy is established, freeing senior engineers for higher-value data product work.
Cross-account data sharing via RAM eliminates the need for data duplication between accounts, which is the primary cost driver in enterprises that have addressed the governance problem by simply copying data to where it is needed. A typical enterprise data lake at 100TB scale, with data duplicated across three consumer accounts, carries roughly $22,000 per month in unnecessary S3 storage costs plus data transfer fees. Cross-account Lake Formation grants eliminate this pattern entirely.
The compliance cost reduction is harder to quantify but is often the strongest business case for governance investment. A SOC 2 Type II audit that requires evidence of data access controls can take 6-8 weeks of engineering and compliance team time to prepare manually. With Lake Formation audit logs feeding into a structured compliance dashboard, the same evidence package can be generated in hours. For organisations in financial services or healthcare facing annual regulatory cycles, this alone often justifies the implementation investment within the first year.
When evaluating against FinOps principles for managing total cost of ownership, the Lake Formation business case should include storage cost reduction from eliminating duplicated datasets, engineering time recovered from access management, reduced compliance preparation overhead, and risk reduction quantified against the average cost of a data breach.
Decision Framework
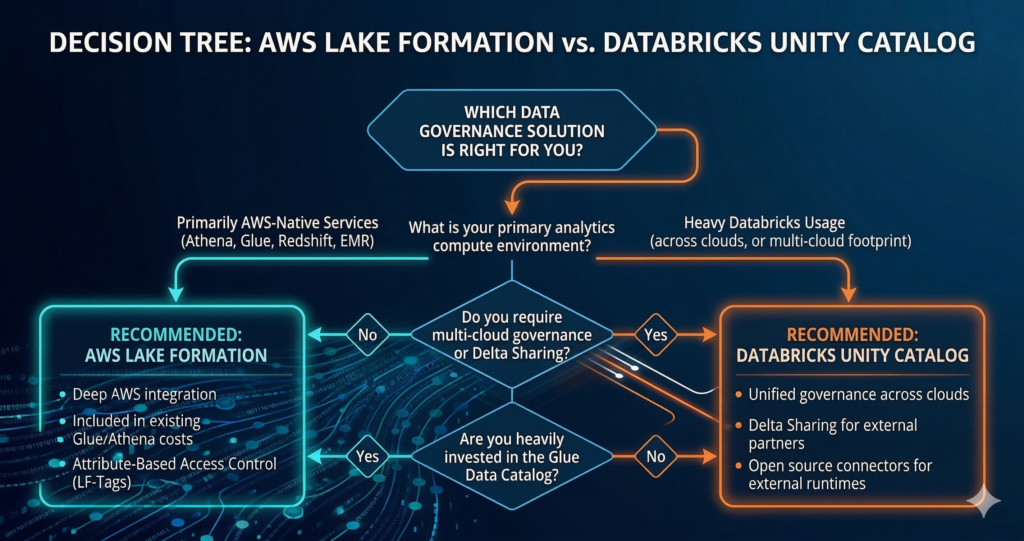
Lake Formation is the right choice when your primary analytics compute runs on AWS-native services. If Athena is your primary query engine, Redshift or Redshift Spectrum handles your warehouse workloads, and Glue manages your ETL, Lake Formation governs all three through a single permission model with no additional licensing overhead. The integration depth with these services is unmatched by any third-party governance tool.
Reconsider Lake Formation as your primary governance layer when your compute estate extends beyond AWS. If significant workloads run on Databricks across multiple clouds, or if you need to share governed data with external partners using open protocols, Unity Catalog’s cross-platform governance and Delta Sharing capabilities make it the stronger fit. This is not an either/or decision for all organisations, some enterprises run Lake Formation for AWS-native workloads and Unity Catalog for Databricks workloads, accepting the complexity of two governance planes in exchange for best-in-class enforcement on each compute layer.
Consider your existing Glue Data Catalog investment carefully. Lake Formation requires the Glue Data Catalog as its semantic layer. If your organisation has already invested in cataloguing data assets, documenting schemas, and maintaining lineage within Glue, Lake Formation builds directly on that investment. If your catalog is maintained in a third-party tool like Collibra or Alation, you will need to evaluate the synchronisation approach between your business catalog and the Glue technical catalog before Lake Formation can govern access effectively.
Implementation Roadmap
Phase 1: Foundation (Months 1-3)
The most important first step is auditing the current permission state before making any changes. Document every IAM role and policy that grants direct S3 access to data lake prefixes, every Glue crawler and ETL job service role, and every analytics service workgroup configuration. This audit almost always reveals over-provisioned access roles with read/write access to entire buckets that are only used for specific table queries.
Enable Lake Formation on the target accounts and register S3 locations with the Lake Formation service role. Configure the Glue Data Catalog to use Lake Formation permissions, but do not yet revoke IAMAllowedPrincipals grants. This parallel mode allows you to test Lake Formation permission grants against real consumer patterns without breaking existing access. Establish your LF-Tag taxonomy during this phase, engaging data domain owners to agree on the tag vocabulary before any tags are applied to production assets.
Phase 2: Governance Rollout (Months 4-9)
Begin applying LF-Tags to Data Catalog resources systematically, starting with new data assets where you control the access control posture from day one. Convert access requests from direct S3 grants to Lake Formation grants for new consumers, validating the provisioning workflow before cutting over existing consumers. Implement cross-account RAM shares for the highest-demand cross-team data assets where permission coordination is currently a bottleneck.
Revoke IAMAllowedPrincipals grants on a database-by-database basis once all consumers for that database have been migrated to Lake Formation grants. Maintain a rollback procedure, the ability to re-enable IAM-based access for a specific database until you have validated that Lake Formation is correctly enforcing all required permissions. Connect Lake Formation audit logs to your SIEM or compliance dashboard during this phase.
Phase 3: Maturity (Months 10-18)
Implement row-level security for datasets requiring principal-scoped data access. Build self-service access request workflows that allow data consumers to request LF-Tag-based permissions through an internal portal, with approval routing to data domain owners rather than the central data engineering team. Establish quarterly access reviews where domain owners certify active consumers and revoke stale grants. Integrate Lake Formation permissions with your identity provider to automate grant provisioning and revocation based on HR system changes.
Future Directions
Lake Formation’s roadmap is moving toward tighter integration with the AWS analytics ecosystem as data mesh architectures become the dominant enterprise pattern. The concept of federated governance where individual data domain teams own their Glue catalogs and publish governed datasets to a central discovery layer maps directly to Lake Formation’s cross-account sharing model and is likely to see continued investment from AWS as the data mesh pattern matures.
The introduction of Apache Iceberg as a first-class table format in the AWS ecosystem adds governance complexity that Lake Formation is positioned to address. Iceberg tables stored in S3 can be registered as Lake Formation resources and governed with the same column-level and row-level controls as Glue-catalogued tables, but the integration between Lake Formation and open table format metadata management is still maturing. Organisations adopting Iceberg at scale should evaluate Lake Formation’s current Iceberg support against their specific query engine requirements before committing to it as the governance layer.
AI and ML workload governance is an emerging requirement that Lake Formation is beginning to address through integration with AWS SageMaker. As training datasets and feature stores become regulated assets in financial services and healthcare, the ability to apply column-level security and row filters to ML input data and to audit which models were trained on which data – will become a regulatory requirement rather than a best practice.
Strategic Recommendations
For organisations building their first governed data lake on AWS, Lake Formation should be the default governance choice. The cost model is straightforward, the integration with Athena and Glue is production-grade, and the LF-Tag model scales from small teams to enterprise-wide deployments without requiring architectural rework. The critical success factor is establishing the tag taxonomy before applying it to data assets at scale , retrofitting a taxonomy to a large existing catalog is significantly more expensive than designing it correctly upfront.
For organisations with an existing Databricks investment considering a governance consolidation, evaluate Unity Catalog against Lake Formation honestly by mapping your actual compute estate. If 70% or more of your analytics queries run on AWS-native services, Lake Formation provides better coverage at lower cost. If your Databricks usage is substantial and spans multiple clouds, Unity Catalog’s cross-platform enforcement justifies the additional complexity.
The most common mistake in Lake Formation implementations is treating it as a permissions migration project rather than a governance programme. The technical implementation – registering resources, configuring tags, migrating grants – takes weeks. Building the organisational practices around access request workflows, domain ownership, and quarterly access reviews takes months. Both are necessary for Lake Formation to deliver its value. Teams that deploy the technology without the process end up with a more complex version of the IAM problem they started with.
Useful Links
- AWS Lake Formation Developer Guide
- Lake Formation LF-Tag Based Access Control
- Cross-Account Data Sharing with Lake Formation and RAM
- AWS Glue Data Catalog Documentation
- MOIA: Automated GDPR-Compliant Data Lake with Lake Formation (AWS Big Data Blog)
- Gilead Sciences: Journey from Migration to Innovation on AWS (re:Invent 2022 PDF)
- Databricks Unity Catalog Documentation
- IBM Cost of a Data Breach Report 2024
- AWS Lake Formation Best Practices for Column-Level Security
- Delta Sharing Protocol Documentation