Multi-cloud adoption reached 89% among enterprises in 2024, yet Gartner predicts 50% of these implementations will fail to deliver expected results by 2029. The disconnect between adoption and success reveals an uncomfortable truth: multi-cloud is frequently a solution searching for a problem. Despite pervasive vendor marketing positioning multi-cloud as the inevitable evolution of cloud maturity, the architectural complexity, operational overhead, and hidden costs outweigh promised benefits for most organizations.
Consider the data: organizations pursuing multi-cloud without specific business justification face 25-50% higher operational costs, require minimum teams of 3-5 specialized engineers, and paradoxically often reduce rather than enhance resilience. The complexity tax compounds exponentially: each additional cloud provider doesn’t simply add linear overhead but creates multiplicative integration challenges across identity management, networking, monitoring, and data consistency.
The counterexamples expose the multi-cloud myth. Netflix achieved 99.99% availability serving 280 million subscribers entirely on AWS. Spotify deliberately evaluated and rejected multi-cloud in 2015, achieving 60% infrastructure cost reduction by committing deeply to GCP. These aren’t outliers. They’re demonstrations that robust single-cloud architectures with proper disaster recovery patterns deliver superior business outcomes than distributed complexity across providers.
This analysis provides platform architects and engineering leaders with a practical decision framework: when multi-cloud genuinely solves business problems versus when it creates operational burden without corresponding value. The path forward for most organizations isn’t multi-cloud sophistication but single-cloud excellence.
The Evolution of Multi-Cloud: From Promise to Reality
The multi-cloud narrative evolved from legitimate enterprise requirements into vendor-driven dogma. Early adopters pursued multi-cloud for valid reasons: post-merger infrastructure consolidation, geographic regulatory requirements beyond single-provider coverage, or genuine best-of-breed requirements where specific provider capabilities delivered competitive advantage. These organizations accepted complexity costs because business value exceeded operational burden.
The market shifted dramatically around 2018-2020. Multi-cloud transformed from specialized architecture pattern into default assumption. Vendor marketing positioned single-cloud as naive, multi-cloud as mature. Cloud vendor lock-in concerns dominated architecture discussions despite limited evidence that switching costs justified the prevention measures organizations implemented.
Research from CIO Dive shows 67% of enterprises now operate multi-cloud environments, yet BCG’s survey of 250+ CTOs reveals 95% operate below the efficiency frontier, they have multi-cloud by accident through shadow IT and acquisitions rather than by deliberate strategy. Accidental multi-cloud creates cost and complexity without governance frameworks or tooling to manage it effectively. The result: organizations bear operational burden without reaping theoretical benefits.
The mature perspective recognizes multi-cloud as an architectural option with specific applicability, not an inevitable destination. Organizations at genuine cloud maturity Level 5 (only 5% of enterprises) can evaluate multi-cloud rationally. The remaining 84% at entry-level maturity should focus on single-cloud operational excellence before multiplying their complexity surface.
The Multi-Cloud Complexity Tax
Multi-cloud architectural complexity doesn’t scale linearly, it compounds exponentially. Consider identity and access management alone: AWS exposes over 15,000 IAM actions, Azure nearly 19,000, and GCP exceeds 10,000. Your platform team must now maintain expertise across 44,000 unique permissions, each with fundamentally different permission models and inheritance patterns. Research from the Cloud Security Alliance found that 60% of organizations cite IAM complexity as a major operational hurdle, with 51% struggling with accumulated technical debt from managing disparate identity systems.
The networking layer presents similarly multiplicative complexity. AWS VPCs operate with regional scope and explicit routing tables, Azure VNets use hub-and-spoke topologies with different subnet behaviors, and GCP’s global VPC model allows cross-region connectivity without gateways. You’re not just managing three sets of firewall rules, you’re maintaining Infrastructure as Code for three entirely distinct networking configurations simultaneously. Organizations report that cross-cloud communication introduces 40-60% latency increases, while data egress fees between clouds add 25% or more to total infrastructure spend.
Monitoring and observability costs extend beyond software licensing. AWS CloudWatch, Azure Monitor, and GCP Operations Suite aren’t designed for cross-platform observability. Your teams face fundamental data silos where metrics, logs, and traces are collected inconsistently. Engineers must navigate multiple systems to diagnose issues, dramatically increasing Mean Time to Resolution. Uber’s architecture famously scaled to over 1,000 microservices, engineers called it the “Death Star” due to tangled dependencies. Multiply that complexity by three different cloud platforms.
The hidden multiplier is tool proliferation. A production-grade multi-cloud deployment requires: three Infrastructure as Code providers, three native monitoring stacks or expensive unified third-party tools, three IAM systems, three secret management solutions, CSPM tools covering all providers, service mesh across Kubernetes clusters, multi-cloud CI/CD orchestration, unified observability platforms, networking tools and VPN contracts per provider, and data replication solutions for every database type. Industry data shows 63% of multi-cloud organizations rely on at least five separate tools, with 83% manually consolidating data because automated integration remains complex.
For a modest 100-pod deployment with service mesh, operational costs run $2,200-4,400 monthly when accounting for both compute and engineering time. The learning curve for each new cloud service spans 2-4 weeks, service mesh maintenance consumes 5-10 hours monthly, and you face 10-50% CPU overhead plus latency from the mesh itself. Scale this across hundreds of services and three providers, and you understand why 58% of enterprises cite lack of multi-cloud skills as their biggest barrier.
The FinOps implications extend beyond infrastructure spend. Multi-cloud requires sophisticated cost allocation across heterogeneous billing systems, unified tagging strategies that map to each provider’s distinct metadata models, and continuous rightsizing across different instance families and pricing models. Organizations report spending 7.5-27% of total cloud bills on data egress alone: the “multi-cloud tax” for moving data between providers that wouldn’t exist in single-cloud architectures.
Multi-Cloud Reduces Resilience Through Complexity
The most pernicious myth is that multi-cloud inherently provides better disaster recovery. Adrian Cockcroft, former Netflix cloud architect who built one of the world’s most resilient streaming platforms, states directly: “Multicloud for failover adds complexity and likely reduces resilience instead of enhancing it.” This isn’t theory: it’s empirical observation from someone who architected reliability serving hundreds of millions of users.
The resilience paradox emerges from complexity itself becoming a risk factor. Research shows 75% of enterprises lack full visibility into application deployments across multi-cloud environments. When you cannot comprehensively monitor your infrastructure, you cannot effectively secure or maintain it. Alert fatigue from disconnected monitoring tools, information overload from multiple cloud consoles, and delayed incident response from context switching between different provider paradigms, these operational realities degrade reliability rather than strengthening it.
True failover between clouds represents a massive engineering challenge. You need full portability of your application stack, requiring either lowest-common-denominator implementations (sacrificing competitive advantage) or parallel service implementations (doubling engineering burden). Your databases must replicate across clouds with consistency guarantees, ACID properties are non-trivial when data replicates across providers with different network latencies and APIs. You’ll implement two-phase commit protocols, handle conflict resolution, and accept that manual intervention frequently becomes necessary.
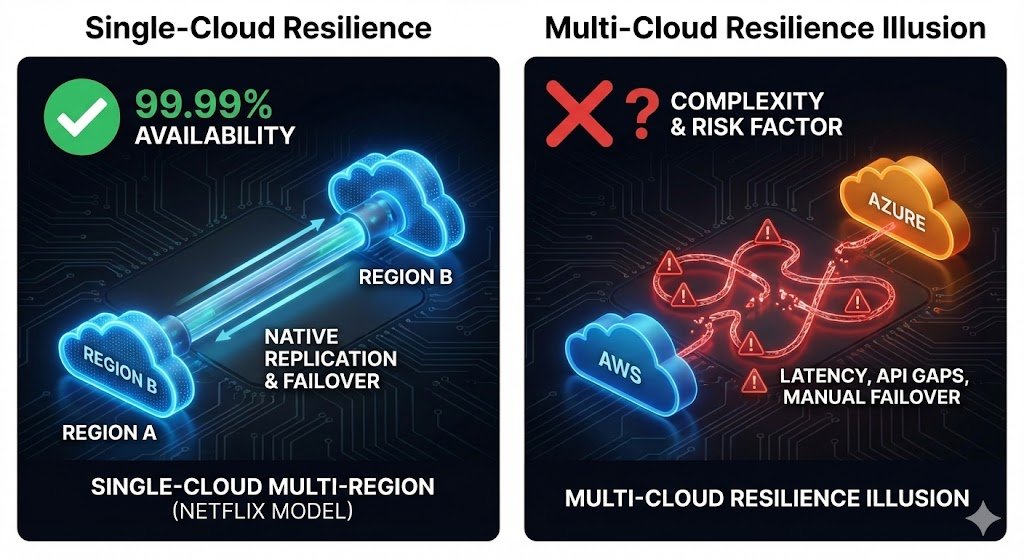
Netflix provides the counterexample that exposes the multi-cloud resilience myth. They operate entirely on AWS, deploying across multiple regions. Their Chaos Engineering practice, the famous Simian Army including Chaos Monkey that randomly terminates instances and Chaos Kong that simulates entire AWS region failures, demonstrates you achieve world-class resilience through architectural excellence within one cloud. They maintain 99.99% availability serving over 280 million subscribers with billions of daily plays, using multi-region architecture with active/passive failover between AWS regions.
Spotify’s Chief Architect Niklas Gustavsson evaluated multi-cloud in 2015 and rejected it, writing: “Working with multiple providers is great for minimizing lock-in effects, but means you need to invest in abstractions across multiple providers. This was something we wanted to avoid because it can prevent you from ‘moving up the stack’ and getting a greater return on your investment.” They chose deep partnership with GCP instead. The result: they migrated 1,200 microservices and 100+ petabytes, now process over one billion events daily, and achieved 60% infrastructure cost reduction while closing all on-premise data centres.
The False Promise of Cloud-Agnostic Abstractions
The industry learned this lesson with Java Enterprise Edition. The pitch was identical: build your application as an EAR file and run it portably on JBoss, WebSphere, or WebLogic. The promise was “build once, run everywhere.” The reality became “build once, debug everywhere.” The abstraction layer couldn’t hide genuinely different implementations underneath.
Cloud-agnostic abstractions face identical challenges. Yes, you can move OCI-compliant Docker containers between Kubernetes environments, that’s one tiny piece of system architecture. What about the managed database with provider-specific replication? The object storage with different consistency guarantees? The identity system with fundamentally different permission models? The networking layer where GCP uses global VPCs while AWS implements regional VPCs?
ThoughtWorks explicitly labels “Generic Cloud Usage” as HOLD in their Technology Radar, an anti-pattern to avoid. Organizations limiting themselves to features common across all providers miss unique benefits while making massive investments in home-grown abstraction layers that are too complex to build and too costly to maintain. Engineering effort diverted to maintaining abstractions prevents teams from leveraging capabilities that could deliver competitive advantage.
Consider what “cloud-agnostic” actually means: you’re self-managing services that cloud providers offer fully managed. Instead of AWS RDS with automated backups, multi-AZ failover, and point-in-time recovery, you’re deploying PostgreSQL yourself in containers, implementing your own replication, managing patching, handling backup verification. Your engineers maintain databases instead of building product features. You’ve recreated a custom datacenter in the cloud, sacrificing the operational leverage that made cloud adoption valuable.
Multi-Cloud vs Single-Cloud: Decision Framework
Gregor Hohpe, author of “The Software Architect Elevator” and former Google and AWS architect, provides the most sophisticated framework using financial options theory. Multi-cloud represents an option with calculable value based on switching cost (the strike price), timeframe until you might switch, volatility of your requirements, and your discount rate reflecting organizational velocity. Lock-in equals switching costs multiplied by likelihood of needing to switch, you control both levers.
The crucial insight: fast-moving digital organizations are LESS likely to adopt multi-cloud because today’s complexity cost is very high while future payoff remains uncertain. Organizations with high velocity can rewrite applications faster than they can maintain complex abstraction layers. Business leaders evaluating cloud strategy should understand that rather than spending 18 months implementing multi-cloud frameworks, investing in organizational velocity reduces switching costs when they actually matter.
When Multi-Cloud Makes Business Sense
Multi-cloud may be justified for specific scenarios with quantifiable business value:
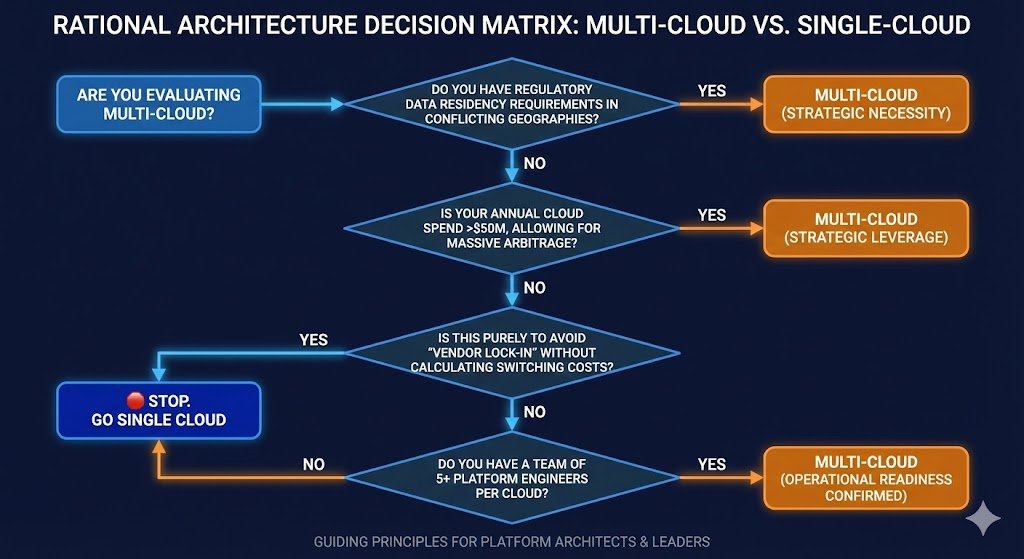
Post-Merger Integration: Inherited platforms from acquisitions create accidental multi-cloud. Rational approach: maintain separation temporarily while migrating to standardized platform over 12-24 months. Permanent multi-cloud from M&A typically signals inability to make architectural decisions rather than deliberate strategy.
Regulatory Geographic Requirements: Rare scenarios where data residency regulations require specific geographic presence beyond single provider’s coverage. European organizations requiring data sovereignty in Switzerland and Brazil simultaneously might justify multi-cloud. Verify this genuinely requires multiple providers rather than multi-region within one cloud.
Strategic Business Decisions: Retailers avoiding AWS due to Amazon’s competitive presence in their market. Valid strategic choice with clear business reasoning. Accept the complexity costs as strategic investment rather than disguising it as technical necessity.
Legitimate Best-of-Breed Requirements: Specific provider capabilities delivering measurable competitive advantage that exceeds complexity costs. Quantify the value differential: if GCP’s BigQuery provides $500K annually in productivity gains over alternatives, and multi-cloud overhead costs $200K annually, net $300K justifies the complexity. Most organizations cannot articulate this calculation.
When Single-Cloud is the Rational Choice
Multi-cloud is almost certainly premature when:
Fear-Based Lock-in Avoidance: Primary motivation is avoiding vendor lock-in without calculating actual switching costs or comparing them to multi-cloud operational burden. Organizations spend $2M annually on multi-cloud complexity to avoid hypothetical $1M migration that may never occur.
Assumed Resilience Benefits: Belief that multi-cloud inherently provides better disaster recovery without evidence. Netflix and Spotify prove world-class reliability doesn’t require multiple cloud providers.
Expected Cost Optimization: Expectation of better pricing through provider competition without modeling the 25-50% complexity tax, data egress costs, and engineering overhead that eliminate theoretical savings.
Low Organizational Maturity: Operating at cloud maturity Level 0-2 with manual deployment processes, ad-hoc security, and limited automation. Adding multi-cloud complexity to immature operations creates compounding chaos.
Low Deployment Velocity: Teams deploying on 3-6 month cycles indicate organizational velocity too slow to maintain multi-cloud infrastructure. Friction compounds when change is already slow.
Insufficient Platform Engineering: Lack of dedicated platform team with capability to build and maintain abstraction tooling, unified observability, and cross-cloud governance frameworks.
Organizational Readiness Assessment
The maturity prerequisites for successful multi-cloud deserve honest evaluation:
Engineering Capability: Minimum 3-5 skilled DevOps engineers with genuine multi-platform expertise (not resume buzzwords but production experience operating at scale across providers). Market reality: these engineers command £120K-£180K salaries and remain scarce.
FinOps Maturity: Established practices with automated cost monitoring, allocation, and showback across providers. Tools like CloudHealth or vendor-specific solutions configured and actively used. Without FinOps foundation, multi-cloud costs spiral invisible until massive bills arrive.
Security Posture: Level 3 or higher cloud security maturity with automated controls, real-time threat detection, comprehensive visibility, and unified identity management. Research shows over one-third of organizations lack adequate IAM monitoring in single-cloud environments (catastrophic when multiplied across providers).
Observability Infrastructure: Unified monitoring and logging already deployed and working effectively. If you cannot comprehensively monitor single-cloud infrastructure, multi-cloud observability becomes impossible. Expect $50K-$200K annually for enterprise observability platforms.
Governance Frameworks: Standardized policies, compliance controls, and approval workflows that can extend across heterogeneous environments. Regulatory compliance (SOC 2, ISO 27001, PCI-DSS) verified across all providers.
Cultural Prerequisites: Organizational embrace of Infrastructure as Code, DevOps practices, and managed services. Teams comfortable with automation and continuous deployment. Cultural resistance to cloud-native patterns predicts multi-cloud disaster.
Single-Cloud Disaster Recovery That Actually Works
AWS offers four disaster recovery strategies within a single provider. Backup and restore uses cross-region data replication with Infrastructure as Code for rapid redeployment (lowest cost with higher RTO/RPO). Pilot light maintains core infrastructure in secondary region ready for quick activation. Warm standby runs full environment at reduced capacity for near-immediate failover. Multi-site active/active serves traffic from multiple regions simultaneously for near-zero RTO.
Each AWS region contains three or more physically isolated availability zones, separate datacenters with redundant power and networking. AWS managed services automatically failover between AZs. EKS spans Kubernetes control planes across AZs and replaces unhealthy nodes automatically. RDS Multi-AZ deployments provide automatic failover to standby replicas. DynamoDB replicates across AZs by default with 99.999% availability SLA.
For higher resilience requirements, multi-region within single cloud delivers the redundancy you need. Netflix maintains primary and secondary AWS regions with full capacity, implementing circuit breaker and bulkhead patterns through microservices to isolate failures. Their 2,000+ independent services limit blast radius so problems remain localized rather than cascading. This is the gold standard: less than 0.01% downtime serving hundreds of millions globally, built entirely on one provider.
The vendor negotiation argument for multi-cloud misunderstands procurement leverage. Cloud providers compete aggressively for enterprise customers, AWS, Azure, and GCP all offer Private Pricing Agreements for significant commitments, volume discounts, and enterprise support with dedicated technical account managers. Your leverage comes from volume, commitment, and strategic partnership, not from maintaining parallel infrastructure.
The Cloud Repatriation Signal: When Organizations Choose Simplicity
The counter-trend to watch is cloud repatriation, companies moving from cloud back to on-premises or from multi-cloud to single-cloud, deliberately choosing reduced complexity over theoretical flexibility. These decisions reveal sophisticated economic calculations about when ownership economics outweigh rental costs at scale. Understanding the hidden costs of cloud operations helps contextualize these choices.
37signals provides detailed financial transparency: they spent $3.2 million annually on AWS in 2022. After workloads became predictable, they no longer needed cloud elasticity premium.
They invested $600,000-700,000 in Dell servers and $1.5 million in Pure Storage arrays. First-year savings reached $1 million. Second-year savings exceeded $2 million total. Hardware costs were recouped within first year. Monthly cloud spend dropped from $180,000 to under $80,000, 60% reduction. CTO David Heinemeier Hansson notes: “There were no hidden dragons of additional workloads that required us to balloon the team.”
Dropbox’s reverse migration saved $75 million over two years. First year delivered $39.5 million savings, year two added $35.1 million. They moved 500 petabytes to three custom data centers with custom network backbone built by ~30 people initially. Storage was core to their business so infrastructure became competitive advantage rather than outsourced commodity. They maintain ~10% of workloads on AWS for geographic distribution where they lack datacenters.
These aren’t anti-cloud manifestos, they’re sophisticated economic calculations about when ownership economics outweigh rental costs at scale. They share common characteristics: massive predictable scale where ownership delivers better unit economics, storage or compute-heavy workloads rather than requiring extensive managed services, long-term stable requirements, and engineering teams capable of managing infrastructure efficiently.
Strategic Recommendations
Start with Gartner’s prediction: 50% of multi-cloud implementations won’t deliver expected results by 2029. Ask whether your organization has specific business justification beyond fear of lock-in. Calculate switching costs honestly (not theoretical “we might need to move someday” but actual effort with timelines and resource estimates). Compare those to the real expenses of multi-cloud: minimum $2,200-4,400 monthly per 100-pod deployment, 25-50% higher operational costs, 7.5-27% of cloud bills from data egress, and engineering time diverted from product development.
Assess organizational velocity and maturity realistically. If your teams deploy quarterly with manual processes, adding multi-cloud complexity will slow you further. You need automated deployment pipelines, Infrastructure as Code for everything, comprehensive monitoring, chaos engineering practice, and FinOps capability before multi-cloud makes sense. Organizations at low maturity should focus on single-cloud excellence.
For disaster recovery, default to multi-region single-cloud architecture. Deploy across availability zones for datacenter failure protection, implement multi-region active/passive for regional disasters, and consider multi-region active/active only when you need near-zero RTO for complete provider outages (extremely rare). Practice chaos engineering to verify resilience mechanisms work. These practices deliver resilience without multi-cloud operational burden.
For vendor leverage, focus on contract terms rather than parallel infrastructure. Negotiate data portability clauses, include benchmark pricing provisions, require exit assistance, avoid early exit penalties, establish strong SLAs with clear remediation, and build deep partnership with strategic account managers. The relationship approach often delivers more value than procurement warfare.
Where you accept lock-in strategically, make it count. Use advanced provider-specific services that deliver competitive advantage rather than restricting yourself to lowest-common-denominator capabilities. Spotify explicitly made this choice to “move up the stack” and leverage GCP’s BigQuery, Dataflow, and Pub/Sub. Accept tactical lock-in where benefits clearly exceed costs, but maintain comprehensive dependency inventory and calculate switching costs concretely.
Choosing Architectural Simplicity Over Theoretical Flexibility
The default question in platform architecture should be “what specific problem does this complexity solve?” rather than “how can we avoid theoretical future risk?” Multi-cloud rarely addresses concrete problems. It usually targets hypothetical scenarios while creating immediate operational burden. Gregor Hohpe’s law applies: “Excessive complexity is nature’s punishment for organizations unable to make decisions.”
The path forward for most organizations is single-cloud excellence: deep expertise in chosen provider’s services, multi-region architecture for resilience, strategic use of managed services to move up the stack, chaos engineering to verify recovery mechanisms, strong vendor relationships with favourable contract terms, automated everything through Infrastructure as Code and CI/CD, comprehensive monitoring and incident response, and regular reassessment of assumptions against business objectives.
Netflix and Spotify demonstrate that world-class reliability, global scale, and operational excellence don’t require multi-cloud. They achieved those outcomes through architectural discipline, engineering rigor, and deliberate decisions about where to accept dependencies. Your organization can follow similar patterns: understand actual requirements clearly, assess capabilities honestly, calculate costs comprehensively including opportunity costs, make deliberate choices about trade-offs, and relentlessly simplify where complexity serves no purpose.
Multi-cloud should be a last resort, not a first instinct. Prove you can operate single-cloud excellently before multiplying your operational surface area. Most organizations discover that robust single-cloud architecture with proper disaster recovery provides everything they need without the complexity tax. Save multi-cloud for scenarios with clear business value that justifies the burden, and document that justification with specific metrics. Your future engineering team will thank you for choosing simplicity over theoretical flexibility.
Useful Links
Industry Research & Analysis
- Gartner: Multicloud Strategy Definition – Authoritative definition and strategic context
- Gregor Hohpe: Multi-Cloud Decision Model – Financial options theory framework for evaluating multi-cloud
Technical Implementation & Patterns
- AWS: Disaster Recovery Options in the Cloud – Single-cloud resilience patterns
- AWS: Multi-Cloud Anti-Patterns – Common misconceptions and failure modes
- InfoQ: Building Multi-Cloud Event-Driven Architectures – Technical challenges in distributed systems
Real-World Case Studies
- Netflix: Completing the Cloud Migration – Single-cloud at massive scale
- Spotify Engineering: Journey to the Cloud – Deliberate rejection of multi-cloud
- 37signals: Our Cloud Spend in 2022 – Cloud repatriation economics
Security & Governance
- Cloud Security Alliance: IAM Priorities for 2025 – Identity management complexity across clouds