Riot Games cut $10 million from its annual infrastructure bill by moving from a self-managed Mesosphere environment to Amazon EKS with Karpenter. That figure makes headlines, and rightly so. What gets less attention is that a comparable savings opportunity is sitting quietly in the billing accounts of enterprises right now, hidden inside a single CUR line item that most FinOps reviews never surface: AmazonEKS-Hours:extendedSupport. When a Kubernetes cluster drifts past its 14-month standard support window, AWS begins billing at $0.60 per cluster per hour rather than $0.10. For a fleet of 36 clusters, that shift represents roughly £120,000 or more per year in avoidable spend (at recent exchange rates), with zero operational benefit in return. EKS is an excellent platform. But it rewards architects who understand its cost structure as precisely as its compute architecture.
Most enterprise EKS deployments share a predictable set of mistakes. They default to managed node groups without deploying Karpenter, leaving provisioning 2-4 minutes slower than necessary and cost optimisation 20-40% short of what is achievable on the same infrastructure. They treat Fargate as a cost-saving mechanism rather than an isolation tool, running steady-state services on it when well-packed EC2-backed nodes with Karpenter, Spot and Savings Plans would deliver better economics. They still manage cluster authentication via the aws-auth ConfigMap that AWS has deprecated in favour of Access Entries. And they allow Kubernetes version drift to accumulate because upgrade testing is unpleasant, not realising that every cluster missing the 14-month standard support window silently enters the 6x pricing tier.
This post covers the EKS architecture decisions that determine production outcomes at enterprise scale: the four compute models and the specific conditions under which each one is correct, the VPC CNI networking choices that determine whether IP exhaustion arrives at 1,000 pods or 10,000, the identity and access management changes that reduce operational debt across large fleets, and the Karpenter architecture that delivered 5% fleet-wide cost savings at Salesforce across more than 1,000 clusters. The implementation roadmap runs to 18 months. The cost section ranks optimisation levers by ROI, because not every team should start with Karpenter and Spot.
The Four Compute Models: Getting the Default Right
Amazon EKS now offers four distinct compute models, and the correct default for greenfield deployments shifted with the December 2024 GA release of EKS Auto Mode.
Managed node groups remain the backbone of most enterprise EKS estates. AWS provisions and manages EC2 instances via Auto Scaling Groups, handles AMI updates, and orchestrates rolling node upgrades through a four-phase process: new launch template, updated ASG configuration, new nodes with AZ rebalancing (up to 2x the replacement capacity per AZ during transition), then cordoning, draining and terminating the old nodes. Upgrades respect Pod Disruption Budgets by default, which is a safeguard and, for teams with misconfigured PDBs that block all evictions, the most common source of upgrade deadlocks. The 2024-vintage minimal update strategy and the force flag give architects an explicit override when disruption tolerance allows it.
Spot capacity integrates natively with managed node groups. Setting capacityType: SPOT activates the price-capacity-optimized allocation strategy, and configuring multiple instance types of equivalent vCPU and memory shape within each group diversifies interruption risk across Spot pools. Graviton instance types warrant serious attention here: AWS publishes 20-40% price-performance improvement for ARM-compatible workloads, and Datadog’s 2024 container research shows Arm-based instance adoption in managed Kubernetes environments more than doubled over the year, from 2.6% to 7.1% of workloads. That is still a small share, which means the cost arbitrage is largely still available to teams willing to qualify their containers for ARM.
AWS Fargate for EKS is the most consistently misused compute model in enterprise estates. The design intent is sound: each Fargate pod runs in a dedicated microVM, providing genuine kernel-level isolation without requiring dedicated hosts. Fargate is best treated as an isolation and operational-simplicity model first, not a default cost-optimisation model. It can be cost-effective for bursty, short-lived or low-duty-cycle workloads where EC2 idle capacity would dominate the bill. For steady-state services with predictable utilisation, well-packed EC2-backed nodes using Karpenter, Spot and Savings Plans usually provide better economics. The cost crossover is workload-specific and depends on pod shape, bin-packing efficiency, Spot availability and sidecar overhead.
The limitations that matter at enterprise scale are well-documented and stable. Fargate does not support DaemonSets, privileged containers, GPU workloads, or EBS persistent volumes. hostNetwork and hostPort configurations are also unsupported. Each Fargate pod receives its own ENI in your VPC, which delivers excellent security group isolation but creates a 1:1 ratio between pods and IP addresses. A 1,000-pod Fargate deployment consumes 1,000 VPC IPs, a consideration that bites teams who have not planned their secondary CIDR ranges. If your monitoring stack relies on DaemonSets, your stateful workloads require EBS, or your security posture requires privileged init containers, Fargate is not viable as your primary compute model regardless of the isolation appeal.
Self-managed node groups have a narrower but non-negotiable use case: custom AMIs hardened beyond what AWS’s managed offerings expose, specific kernel module or sysctl requirements (the vm.max_map_count setting for Elasticsearch is a common driver that Fargate cannot accommodate), GPU workloads requiring particular NVIDIA driver or CUDA toolkit versions, and HPC configurations with EFA, NUMA pinning, or hugepages tuning. Bottlerocket OS is the right choice for self-managed nodes in most enterprise contexts: immutable root filesystem, no default shell, image-based atomic updates, and a materially smaller attack surface than Amazon Linux. The trade-off is debuggability, since Bottlerocket does not permit arbitrary package installation, which requires SRE teams to adjust how they approach node-level investigation.
EKS Auto Mode reframes the greenfield decision. Released as GA in December 2024, it is a broader AWS-managed operating model that includes Karpenter-based compute provisioning alongside managed networking, load balancing, storage integration and core add-ons. AWS takes responsibility for node provisioning, patching and scaling, as well as the operational overhead of managing VPC CNI, CoreDNS, kube-proxy and the Pod Identity Agent. For organisations without a dedicated platform engineering function, or for those that want Karpenter-class cost optimisation without the operational investment of running these components themselves, Auto Mode is now the correct starting point. The constraint is configurability: Auto Mode’s managed NodePools cover standard x86 and Graviton instance families with sensible defaults, but if you need custom NodeClass configurations, specific launch templates, or workload placement logic that Auto Mode does not expose, the self-hosted Karpenter path offers more control.
Networking: IP Exhaustion, Private Endpoints and Load Balancing
The VPC CNI plugin gives every pod a real VPC IP address, which eliminates overlay network complexity and provides the port-level visibility that security teams want in security group rules. It also means that dense pod packing will exhaust your primary subnet IP space faster than any VPC design review anticipates.
The solution space for IP exhaustion has three tiers. Prefix delegation, enabled via ENABLE_PREFIX_DELEGATION=true on the VPC CNI add-on, assigns /28 IPv4 prefixes (16 IPs per block) to ENI secondary slots rather than individual secondary IPs. An m5.large, which previously supported around 29 pods, reaches 110 with prefix delegation active. The change requires new nodes, so existing nodes must be drained and replaced to benefit. For environments where even prefix delegation is insufficient at scale, custom networking with secondary VPC CIDR blocks provides the most headroom: add a secondary range from the 100.64.0.0/10 CG-NAT space, which does not conflict with typical corporate RFC 1918 ranges, create per-AZ ENIConfig custom resources, and enable AWS_VPC_K8S_CNI_CUSTOM_NETWORK_CFG=true. The cleanest resolution for greenfield clusters is IPv6 from day one, which removes the exhaustion problem entirely. All three approaches require planning before first workload deployment; retrofitting is operationally disruptive.
Cluster API server endpoint posture is the second-highest-impact networking decision and the most commonly deferred. Datadog’s 2024 cloud security research found roughly half of EKS clusters expose the API server to the public internet. The correct enterprise posture is private endpoint only, with kubectl access via AWS Systems Manager Session Manager or a bastion host in the management VPC. The productivity impact is minimal; the risk reduction in the event of credential compromise is significant, and this is the single change with the most favourable security-to-effort ratio available in most EKS estates today.
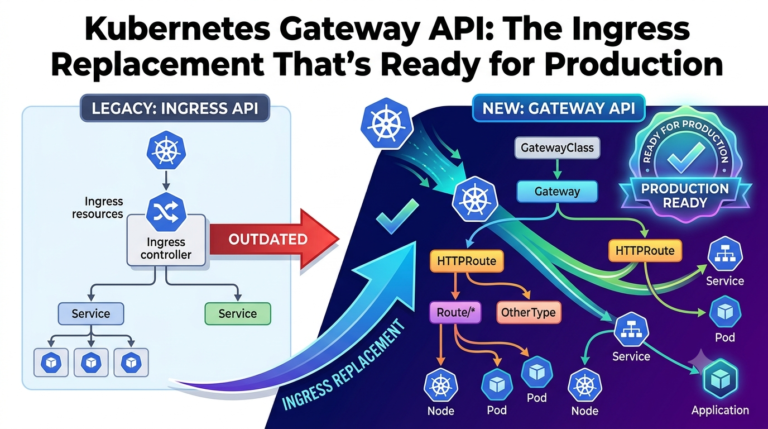
The AWS Load Balancer Controller is the production standard for both Application Load Balancer ingress and Network Load Balancer services. The legacy in-tree cloud provider is in maintenance-only mode and creates Classic Load Balancers, which are not the right answer for workloads started in the last five years. The current LBC supports the Kubernetes Gateway API alongside the older Ingress resource; for greenfield clusters, the Gateway API is the forward-looking choice. Use ALB for HTTP/HTTPS workloads requiring host and path routing, WAF integration, or shared listeners via IngressGroup annotations. Use NLB for raw TCP/UDP traffic, static IP requirements, or protocols that cannot terminate at L7.
Network policy has consolidated around three realistic options. Native VPC CNI network policy (GA since 2023) handles standard Kubernetes NetworkPolicy with L3/L4 enforcement and no additional operational overhead. Calico adds GlobalNetworkPolicy and tiered policies on top of iptables, which is familiar to network engineers from traditional infrastructure backgrounds and maps cleanly to existing compliance frameworks. Cilium’s eBPF data plane provides L7 enforcement, identity-based segmentation, observability via Hubble, and an optional sidecar-less service mesh. For new clusters on current kernel versions where traffic observability and L7 policy matter, Cilium is increasingly the choice. The practical starting point for most teams is native VPC CNI network policy; adopt Cilium when you have specific L7 or observability requirements that justify the operational step-up.
Security Architecture: Identity and Access in 2026
The two most consequential security architecture changes in EKS over the past 18 months are EKS Pod Identity and EKS Access Entries, and both should be in production for any cluster provisioned from 2024 onwards.
Pod Identity (released at re:Invent 2023) replaces the per-cluster OIDC provider approach of IAM Roles for Service Accounts for the workloads it supports. Under the original IRSA model, each cluster requires its own OIDC identity provider registered in IAM, and each IAM trust policy references that cluster’s specific OIDC issuer URL. At fleet scale this creates two operational problems: the IAM OIDC provider quota becomes a ceiling for cluster count, and IAM trust policies can exceed their size limit when the same role is shared across many clusters. Pod Identity resolves both by moving credential injection to an in-cluster agent (the Pod Identity Agent add-on), managing associations via the EKS API, and removing the per-cluster OIDC dependency. It also enables IAM role session tags, which matter for attribute-based access control scenarios. For workloads running on Linux EC2-backed EKS nodes, Pod Identity is now the preferred approach. It is not currently available for Fargate pods, Windows pods, EKS Anywhere, Outposts, or non-EKS Kubernetes clusters, so IRSA remains necessary wherever those environments apply.
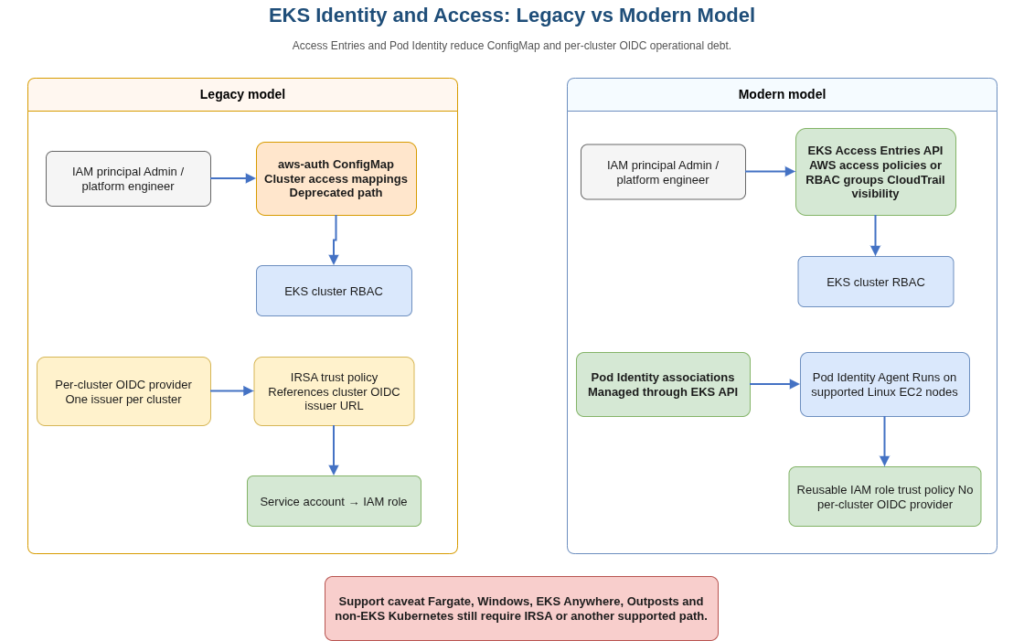
Access Entries replace the aws-auth ConfigMap for cluster access management. The ConfigMap approach carried a well-known failure mode: misconfiguration or accidental deletion could make the cluster inaccessible to all IAM principals except the original cluster creator. Access Entries are managed entirely through the EKS API, appear in CloudTrail audit logs, and support both pre-defined AWS access policies (AmazonEKSClusterAdminPolicy, AmazonEKSAdminPolicy, AmazonEKSViewPolicy) and custom RBAC group mappings. The migration path is to set authentication mode to API_AND_CONFIG_MAP, which gives Access Entry definitions precedence while maintaining ConfigMap compatibility during the transition, then move to API-only mode once all principals are migrated. The aws-auth ConfigMap is deprecated and no longer the recommended access-management path; new clusters should use the Access Entries API from day one.
For secrets management, External Secrets Operator has become the production default for enterprise estates managing multiple backends. Its ExternalSecret and SecretStore CRDs are GitOps-friendly, rotation is handled in the controller, and multi-backend support (Secrets Manager, Parameter Store, Vault, Azure Key Vault in multi-cloud estates) avoids lock-in to a single secrets backend. The AWS Secrets Manager CSI driver approach works well for simpler single-backend estates. Sealed Secrets is viable for small teams but creates key management fragility across multi-cluster environments.
On admission control, Kyverno has gained significant ground on OPA Gatekeeper for EKS-centric environments. Its YAML-native policy syntax is more accessible to engineers who write Kubernetes manifests day-to-day, it handles mutating and generating policies alongside validation, and its test tooling integrates cleanly with standard CI pipelines. Gatekeeper retains advantages where Rego policies need to run consistently across multiple systems (OPA in CI, in API gateways, in service meshes). Neither is the wrong choice; the practical guidance is to default to Kyverno for EKS-focused estates and Gatekeeper where cross-system policy consistency is a specific requirement.
Real-World Case Studies
Riot Games (gaming, 180 million-plus monthly active users) migrated from Mesosphere DC/OS to Amazon EKS in 2021, adopting Karpenter for node lifecycle management. The migration delivered $10 million in annual infrastructure cost savings alongside automatic horizontal scaling that was previously unavailable to individual game teams. The architecture change also enabled game modes that require ephemeral, high-scale infrastructure provisioned and terminated on a per-event basis – something the prior platform could not support economically.
Source: aws.amazon.com/solutions/case-studies/riot-games-case-study/
Securonix (cybersecurity, SIEM platform for Fortune 500 customers) runs more than 10,000 Apache Spark jobs on EKS, processing terabytes of security event data per day across a multi-tenant architecture. Moving to a Karpenter-managed cluster with mixed Spot and On-Demand capacity tiered by workload SLA delivered 30% cost savings and a 50% reduction in job failure recovery times, while maintaining 99.99% availability. The combination of Spot for batch and On-Demand for latency-sensitive processing, managed by Karpenter’s bin-packing and consolidation logic, is the architecture pattern driving those outcomes.
Source: aws.amazon.com/solutions/case-studies/securonix-case-study/
Salesforce operates more than 1,000 EKS clusters serving thousands of internal product teams. Migrating that fleet from Cluster Autoscaler to Karpenter, documented in detail on the AWS Architecture Blog, delivered 5% cost savings in FY26 with 5-10% additional reduction projected for FY27. The migration also reduced node provisioning time from minutes to under 60 seconds, eliminated the Auto Scaling Group sprawl that came from maintaining one ASG per instance type per AZ, and gave product teams self-service scaling without requiring platform team involvement for each new workload profile.
Grover (consumer device subscriptions, 1.2 million-plus devices, operations across eight countries) reached 80% Spot capacity in production with Karpenter, a 25-percentage-point increase over what Cluster Autoscaler delivered on the same infrastructure. The architecture uses separate Karpenter NodePool definitions for application, data, monitoring and GPU workloads, with KEDA-driven autoscaling layered on top for queue-driven scaling. Black Friday and promotional demand peaks now self-manage within the Karpenter-Spot architecture without manual pre-scaling intervention.
Cost Architecture: Where the Money Actually Goes
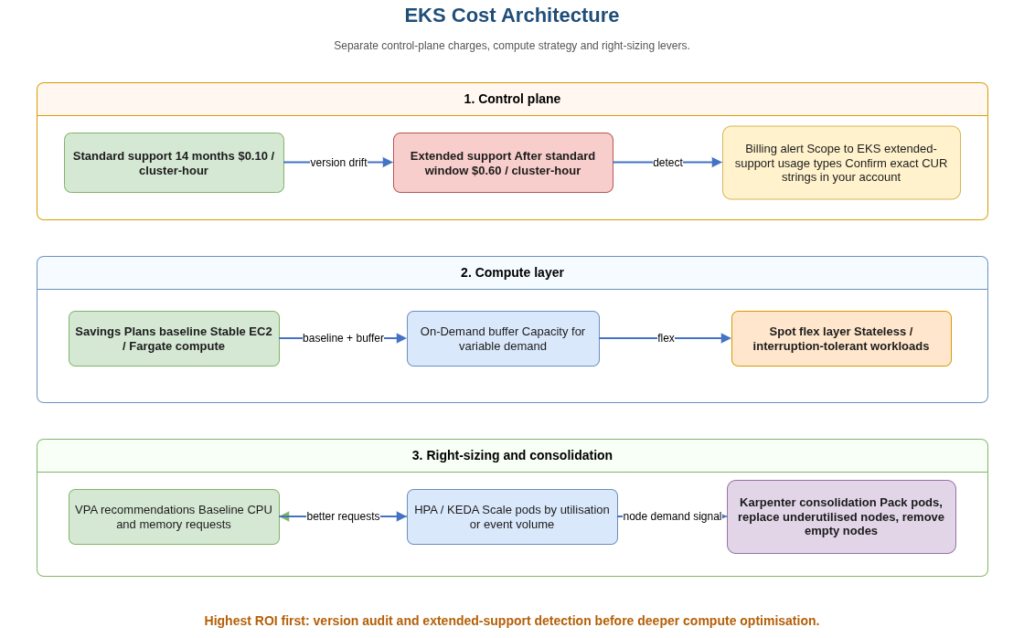
EKS cost has three distinct tiers that architecture reviews should address separately: control-plane fees, compute selection, and right-sizing. Most FinOps conversations start at the compute layer and never reach the other two.
The control-plane fee is $0.10 per cluster per hour within the 14-month standard support window. Extended support raises that to $0.60 per cluster per hour, a factor of six with no operational change. AWS surfaces the distinction via separate line items in Cost and Usage Reports. For teams whose FinOps practice focuses on compute and data transfer spend, the control-plane fee is typically invisible until a quarterly anomaly review reveals an unexpected jump. The practical response is a quarterly Kubernetes version audit as a standing process, with an automated billing alert scoped to EKS extended-support usage types, and a cluster upgradePolicy set to STANDARD so clusters auto-upgrade at end of standard support rather than silently entering the extended tier. One important default to be aware of: AWS sets the upgrade policy to EXTENDED for both new and existing clusters unless explicitly specified otherwise. Teams cannot assume they are protected by default – the STANDARD setting must be configured intentionally. Verify the exact extended-support usage-type strings in your own Cost and Usage Report or Billing Data Exports before building automated alerts around them, as AWS may adjust these identifiers over time.
On compute, Karpenter is now the production-grade node lifecycle manager for EKS. It bypasses Auto Scaling Groups entirely and calls the EC2 Fleet API directly, which removes the per-ASG-per-instance-type constraint that forced Cluster Autoscaler deployments into ASG sprawl. A single Karpenter NodePool with a requirements block specifying multiple compatible instance families covers the full node provisioning surface, mixing c7g, m7g, c7a and m7a instances as Spot availability dictates. Karpenter also runs a continuous consolidation loop that identifies underutilised nodes and either moves their pods to better-packed replacements or terminates empty nodes. Datadog’s container research shows over 65% of Kubernetes workloads use less than half of their requested CPU and memory, which means consolidation headroom is typically material rather than marginal.
The right-sizing layer completes the cost architecture. Vertical Pod Autoscaler in Off (recommendation-only) mode provides CPU and memory usage baselines that inform initial resource request configuration. Running VPA and HPA together in Auto mode creates well-documented interaction problems where VPA restarts pods that HPA is simultaneously trying to scale horizontally; recommendation-only VPA avoids this while still surfacing the data. KEDA, the event-driven autoscaler, is increasingly the correct scaling primitive for workloads driven by queue depth, Kafka consumer lag, or AWS-native event sources such as SQS, Kinesis or MSK. It pairs cleanly with Karpenter: KEDA scales pods based on event volume, Karpenter provisions or removes nodes to match. This combination is what Grover used to reach 80% Spot in production, as documented in their AWS case study. The spot instance architecture patterns covered in our multi-cloud post apply directly here, including the interruption handling and workload classification approach that makes high Spot percentages viable in production.
For Savings Plans coverage, Compute Savings Plans can cover EC2 capacity used by managed node groups and self-managed nodes, and they also apply to AWS Fargate usage including EKS on Fargate. They do not cover EKS control-plane fees, EBS volumes, load balancers, NAT Gateway, data transfer, or other non-compute charges. The recommended approach is to cover a conservative portion of stable baseline compute with 1-year Compute Savings Plans, leaving headroom for Spot, demand spikes and architecture changes.
Compute Model Decision Framework
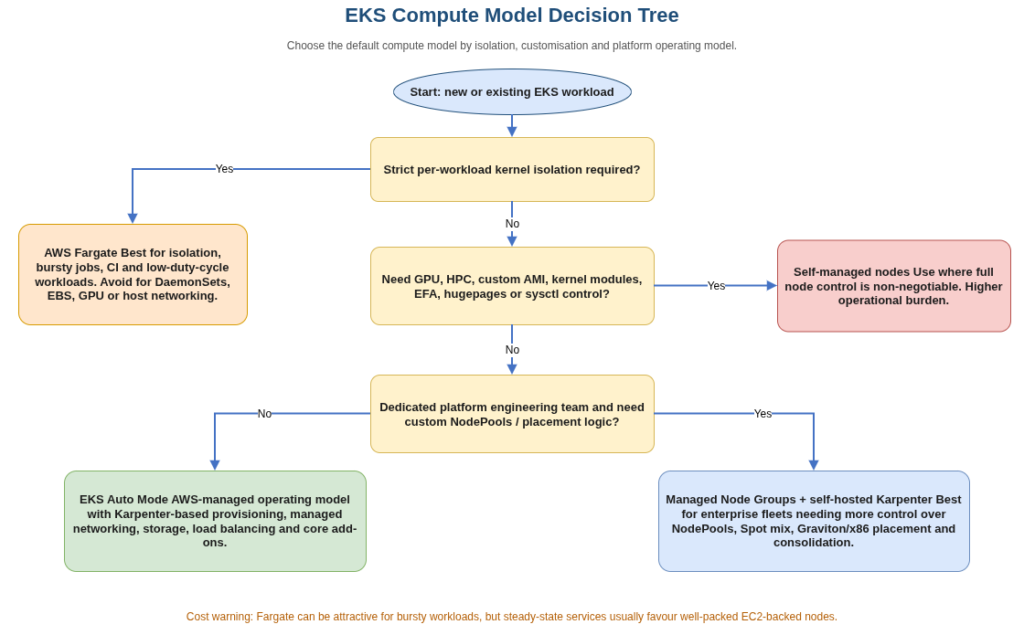
The decision between the four compute models is now more nuanced than the three-way choice that preceded Auto Mode.
Auto Mode is correct for new EKS clusters at organisations without a dedicated platform engineering team, for situations where Karpenter’s operational overhead (managing NodePool and EC2NodeClass CRDs, monitoring the Spot interruption queue, tuning consolidation policies) is not justified by fleet size, and for teams that want AWS to manage node patching and OS updates without self-managing Bottlerocket update operators. The configurability ceiling is the main constraint.
Managed node groups with self-hosted Karpenter is correct for enterprise fleets where flexibility to customise NodePools, mix instance families precisely, and tune consolidation behaviour outweighs the operational investment; for multi-cluster environments where the platform team manages a consistent Karpenter configuration across all clusters; and for estates with both Graviton and x86 workloads that benefit from deliberate placement logic.
Fargate is correct for workloads with strict tenant isolation requirements where per-workload kernel separation is non-negotiable; for bursty or event-driven jobs where idle EC2 capacity would dominate cost; for CI workloads with high demand variation and moderate per-pod resource needs; and for regulated environments where pod-to-pod network isolation at the VM boundary is a compliance requirement rather than a best practice.
Self-managed nodes are correct for GPU workloads with specific driver or CUDA versions; for HPC jobs requiring EFA, hugepages, or specific NUMA configurations; for workloads requiring kernel modules or sysctl settings outside what Amazon Linux 2023 or Bottlerocket expose; and for custom AMI requirements driven by security hardening standards beyond what AWS’s managed AMI families accommodate.
| Dimension | Auto Mode | MNG + Karpenter | Fargate | Self-Managed |
|---|---|---|---|---|
| Node management overhead | AWS | Low (platform team) | AWS | High (team) |
| Provisioning speed | Under 60s | Under 60s | On-demand | 2-5 minutes |
| Spot support | Yes | Yes | No | Yes |
| GPU support | Yes | Yes | No | Yes |
| DaemonSets | Yes | Yes | No | Yes |
| Kernel customisation | No | Limited | No | Full |
| Per-pod VM isolation | No | No | Yes | No |
| EBS persistent volumes | Yes | Yes | No | Yes |
| Cost profile (steady-state) | Optimised | Optimised | Premium (+30-50%) | Optimised |
Implementation Roadmap
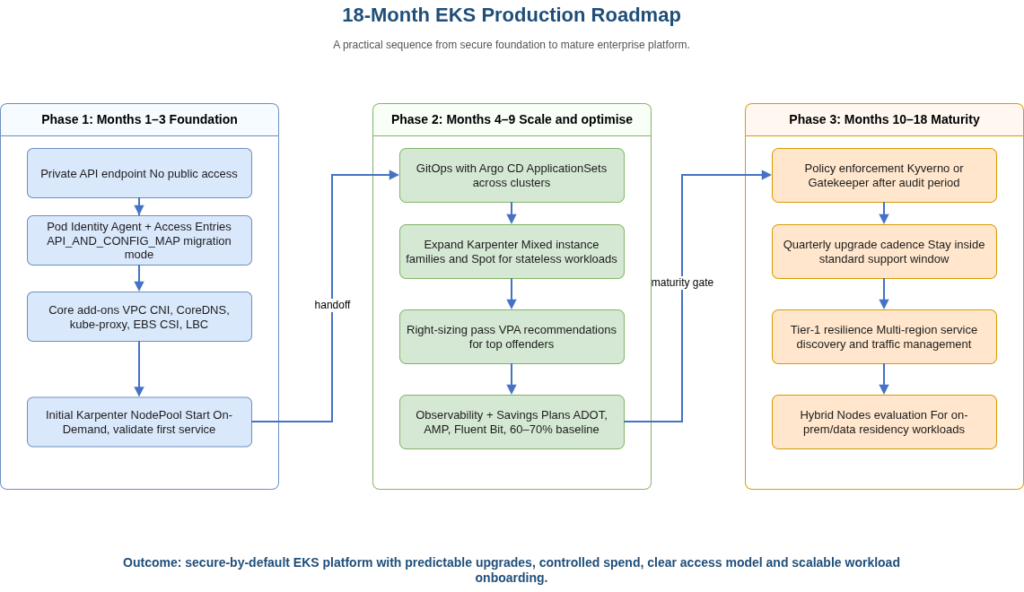
Phase 1 (Months 1-3): Foundation.
The networking decisions made during Phase 1 are expensive to change later. Size VPC subnets with prefix delegation in mind before first deployment, targeting at least 3x the maximum expected pod count in available IPs across your three workload subnets per AZ. Enable the private API endpoint with no public access from day one, and activate audit and authenticator control-plane log streams immediately.
Provision the EKS cluster with authentication mode API_AND_CONFIG_MAP and install the Pod Identity Agent add-on alongside core managed add-ons: VPC CNI with prefix delegation enabled, CoreDNS, kube-proxy, EBS CSI driver, and the AWS Load Balancer Controller. Configure one managed node group on Bottlerocket for system workloads (CoreDNS, monitoring agents, Karpenter itself). Deploy Karpenter with a single NodePool for application compute, starting with On-Demand, then layer Spot once you have validated workload interruption tolerance. Migrate one low-risk stateless service end-to-end as an operational learning vehicle before moving production workloads. The AWS Control Tower multi-account governance patterns discussed here provide the account structure and permission boundary foundations that EKS platform teams build on top of.
Phase 2 (Months 4-9): Scale and optimise.
Establish GitOps as the primary deployment mechanism with Argo CD in a hub-and-spoke configuration, using ApplicationSets to template cluster-scoped resources across environments. Expand Karpenter to cover the full application tier; introduce Spot with mixed instance family NodePools and target 50%+ Spot utilisation on stateless workloads.
Run the first right-sizing pass using VPA in recommendation mode. The results typically reveal enough over-provisioned workloads to justify immediate re-requests for the top 20% of offenders. Introduce KEDA for any workloads with event-driven scaling requirements. Deploy the observability stack: ADOT Collector feeding Amazon Managed Service for Prometheus, Fluent Bit routing logs to CloudWatch Logs, and OpenTelemetry instrumentation for distributed tracing. Purchase 1-year Compute Savings Plans at 60-70% of the established On-Demand baseline once usage patterns have stabilised.
Phase 3 (Months 10-18): Maturity.
Roll out Kyverno or Gatekeeper policies in audit mode for 30 days, then enforce. Core policies should cover image source allow-lists, mandatory resource limits and requests (required for scheduler quality and VPA accuracy), no latest tags in production namespaces, and Pod Security Standards enforcement at the namespace level.
Establish a quarterly Kubernetes upgrade cadence that keeps every cluster inside the 14-month standard support window; automate the audit via a CUR alert on the extendedSupport line item. For tier-1 workloads with active-active multi-region requirements, cross-cluster service discovery and traffic management become relevant here, alongside the multi-region architecture patterns covered in our enterprise scale post. EKS Hybrid Nodes is also worth evaluating at this stage for any workloads with data residency requirements that need compute on-premises but do not require a fully on-premises control plane.
What Comes Next for EKS
AWS’s announcement of 100,000-node EKS cluster support in 2025, driven by AI and ML fleet requirements (with Anthropic’s training infrastructure cited as a reference deployment), signals where the platform ceiling is moving. The architectural patterns that support AI workloads at that scale, including EFA-backed networking, FSx for Lustre storage, and Karpenter NodePools tuned for Trainium and P5 instance families, are becoming relevant to a broader set of enterprises as GPU workloads move from research into production operations.
EKS Hybrid Nodes, also GA from December 2024, addresses a long-standing gap for organisations with on-premises compute requirements. Where EKS Anywhere requires the control plane to run on-premises too, Hybrid Nodes lets you maintain an AWS-managed control plane while running worker nodes in your data centre, connected over Direct Connect or VPN. For UK enterprises with data residency constraints that permit compute on-premises but do not require a fully self-managed control plane, Hybrid Nodes is materially simpler to operate than EKS Anywhere.
The multi-cluster GitOps story has also improved meaningfully. The Amazon EKS Capability for Argo CD, which runs a managed Argo CD hub in an AWS-managed account with IAM Identity Centre integration and Access Entries-based cross-cluster authentication, removes the operational overhead of running and upgrading Argo CD yourself. For teams that have deferred multi-cluster GitOps because of the complexity of self-hosted Argo CD, this is worth re-evaluating. The Terraform and OpenTofu patterns covered in our IaC migration guide apply directly to the cluster factory approach that feeds this GitOps architecture.
Strategic Recommendations
The highest-ROI action for most existing EKS estates is not Karpenter, not Graviton, and not Spot. It is a version audit. Run a Cost and Usage Report query against the AmazonEKS-Hours:extendedSupport line item today. If any clusters appear, calculate the cost delta versus standard support and make upgrading those clusters the immediate priority. The engineering effort is predictable and bounded; the savings begin with the next billing cycle.
For estates ready to invest in compute optimisation, the correct sequence is Karpenter first (provisioning speed and multi-instance-family Spot), then Compute Savings Plans to lock in baseline discounts, then a Graviton migration pass on compatible workloads, then VPA-guided right-sizing for the remaining waste. Doing right-sizing before Karpenter often creates churn when Karpenter consolidation subsequently changes the bin-packing that right-sizing decisions were based on.
The security baseline that most enterprise EKS estates should close in the next quarter: private API endpoint, Access Entries migration in progress, Pod Identity deployed for all new workloads, and audit log streaming active. None require significant engineering investment relative to the risk reduction they deliver.
Useful Links
- AWS EKS Best Practices Guide
- Riot Games EKS Case Study – $10M Cost Reduction
- Securonix EKS Case Study – 30% Cost Savings
- Salesforce: Migrating 1,000 EKS Clusters from Cluster Autoscaler to Karpenter
- Grover: 80% Spot in Production with Karpenter on EKS
- EKS Pod Identity: AWS Blog Announcement
- EKS Extended Support Pricing: AWS Official Blog
- Karpenter Documentation
- Amazon EKS Pricing
- Datadog State of Containers and Serverless Report