Multi-cloud architectures combining GCP with existing AWS or Azure environments deliver measurable business value, but only when implemented with clear strategic intent. Enterprises adopting this approach report 20-40% cost reductions through vendor negotiation leverage, while accessing best-of-breed capabilities like GCP’s BigQuery for analytics or Vertex AI for machine learning. However, the complexity premium is real: multi-cloud operations typically increase total cost of ownership by 38% and require 15-25 person platform teams for enterprise-scale deployments. This comprehensive guide examines when and how to integrate GCP into existing AWS/Azure environments, drawing on production implementations from PayPal, Target, and other global enterprises processing petabyte-scale workloads across multiple clouds.
The business case for multi-cloud has solidified dramatically since 2024. 89% of enterprises now operate multi-cloud environments, driven not by theoretical vendor independence but by concrete regulatory requirements, post-merger integrations, and access to differentiated capabilities. Financial services firms face data sovereignty mandates requiring specific providers in particular regions. Retailers need elastic capacity for seasonal peaks without maintaining year-round overcapacity. Technology companies pursue GCP’s AI/ML superiority whilst retaining AWS infrastructure investments. The question has shifted from “should we adopt multi-cloud?” to “which workloads justify the operational complexity?”
This guide provides production-ready architecture patterns, real cost analysis with specific egress pricing, vendor-neutral technology comparisons, and a phased implementation roadmap spanning 12-24 months. Whether you’re a platform architect evaluating GCP integration or a technical leader justifying multi-cloud investments to executive stakeholders, this analysis delivers the concrete data points and decision frameworks required for strategic multi-cloud decisions.
The multi-cloud reality: market drivers and business context
The global public cloud services market reached $723.4 billion in 2025, growing 21.5% year-over-year, with multi-cloud adoption now the enterprise standard rather than exception. Yet this ubiquity masks significant variation in implementation maturity and business outcomes. Research from Flexera’s 2024 State of the Cloud Report reveals that whilst 89% of organisations use multiple clouds, only 8% achieve high cloud maturity, and Gartner projects that over 50% of organisations will fail to realise expected multi-cloud benefits by 2029 due to poor strategic planning and inadequate FinOps practices.
The primary drivers for adding GCP to existing AWS or Azure environments cluster into six categories, ranked by frequency in enterprise implementations. Vendor lock-in avoidance leads with 86% of organisations planning multi-cloud explicitly for this reason, seeking negotiating leverage that delivers 20-40% discounts through competitive tension. Best-of-breed service selection follows closely. AWS provides the broadest service catalogue and mature ecosystem, Azure offers deep Microsoft integration and hybrid capabilities, whilst GCP excels in data analytics (BigQuery processes queries 54% faster than competitors) and AI/ML workloads through Vertex AI and native TensorFlow integration. PayPal’s multi-cloud connectivity fabric reduced latency by 24% compared to public CDN paths by intelligently routing traffic across cloud providers.
Regulatory compliance and data sovereignty requirements have emerged as non-negotiable drivers, with 43% of organisations citing compliance as their top reason for multi-cloud adoption. Financial services firm Form3 implemented a three-cloud architecture (AWS, Azure, GCP) specifically to satisfy UK financial regulators requiring demonstrated cloud portability and resilience. Their CockroachDB deployment spanning all three clouds functions as a single logical database whilst meeting regulatory requirements for avoiding single-vendor dependency. Similarly, multinational retailers like Target leverage multi-cloud to address regional data residency requirements whilst maintaining unified guest data platforms.
The financial opportunity is substantial but requires disciplined execution. McKinsey research indicates Fortune 500 financial institutions could capture $80 billion in EBITDA by 2030 through cloud transformation, with multi-cloud strategies enabling negotiation leverage and workload optimisation. However, the complexity premium is real: organisations implementing multi-cloud without mature FinOps practices see 30-40% staffing increases, 3x longer incident resolution times, and 15-25% higher operational costs. The economics work only when measurable benefits exceed these complexity costs, typically requiring annual cloud spend exceeding $5 million and dedicated platform teams of 15-25 engineers.
Architectural patterns for cross-cloud integration
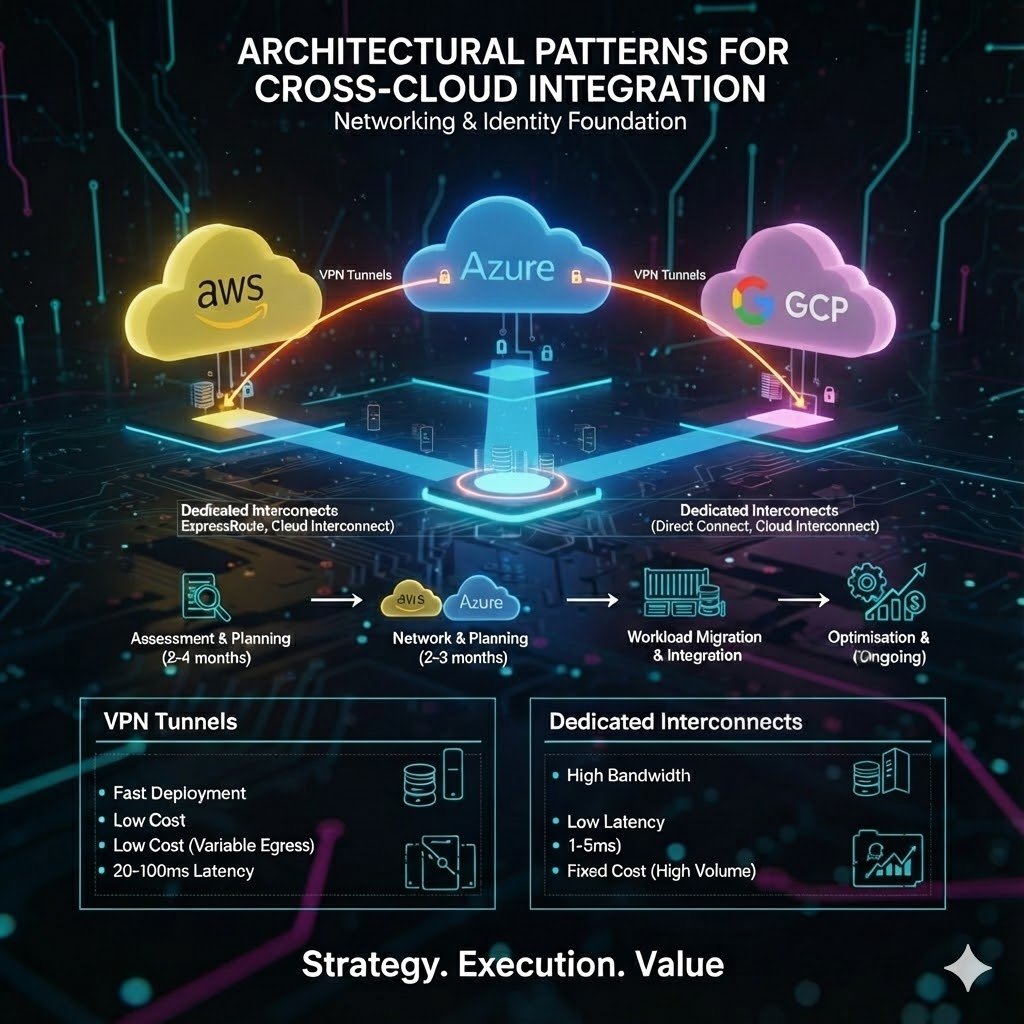
Multi-cloud network connectivity forms the foundation upon which all integration patterns depend, with enterprises choosing from three primary approaches based on bandwidth requirements, latency sensitivity, and budget constraints. VPN-based connectivity provides the fastest deployment path, establishing IPsec tunnels between clouds in days rather than weeks, supporting aggregate bandwidth up to 3 Gbps through ECMP tunnelling, and costing approximately $0.05 per hour for gateway fees plus standard egress rates. AWS Site-to-Site VPN, Azure VPN Gateway, and GCP HA VPN all support BGP routing for dynamic path selection, though performance remains variable with 20-100ms latency depending on internet routing paths. This approach suits development environments, disaster recovery standby configurations, and workloads transferring less than 1 TB monthly where fixed costs outweigh variable egress charges.
Dedicated interconnects (AWS Direct Connect, Azure ExpressRoute, and GCP Cloud Interconnect) deliver predictable performance with 1-5ms latency, throughput scaling to 100 Gbps per circuit, and SLAs ranging from 99.9% to 99.99% depending on redundancy configuration. The cost structure shifts dramatically: $1,643 per month for a 10 Gbps AWS Direct Connect circuit plus $0.02 per GB egress (a 78% reduction from internet egress rates), making dedicated connectivity cost-effective for workloads transferring more than 5-10 TB monthly. Azure ExpressRoute pricing runs higher at $5,000 monthly for 10 Gbps standard tier but includes redundant circuits by default. Google’s Cross-Cloud Interconnect offers managed connectivity to AWS and Azure at premium pricing ($4,088 monthly for 10 Gbps versus $1,699 for dedicated interconnect) but eliminates colocation requirements and provides unified SLAs across cloud boundaries.
Identity and access management integration presents the most complex architectural challenge, with 63% of security leaders identifying cross-cloud identity management as their top IAM concern. The solution architecture centres on federated identity through a centralised identity provider (Azure Active Directory, Okta, or AWS IAM Identity Center), implementing SAML 2.0 federation to all cloud platforms. Each cloud provider maintains distinct IAM models: AWS uses JSON-based policies with explicit allow/deny statements, Azure implements hierarchical RBAC with management groups and subscriptions, whilst GCP employs IAM bindings with inheritance through resource hierarchies. Successful implementations abstract these differences through policy-as-code frameworks like Open Policy Agent (OPA) or Terraform Sentinel, defining cloud-agnostic policies that compile to provider-specific configurations.
Workload Identity Federation represents the modern approach for service-to-service authentication, eliminating long-lived credentials in favour of short-lived tokens. GCP’s implementation allows AWS workloads to exchange IAM role tokens for GCP access tokens through Security Token Service (STS), enabling seamless cross-cloud service communication without storing credentials. This pattern proves essential for CI/CD pipelines, containerised workloads, and serverless functions requiring temporary access to resources in multiple clouds, reducing credential sprawl whilst improving security posture through automatic token expiration.
Data integration patterns range from real-time replication to scheduled batch transfers, with architecture selection driven by freshness requirements, volume, and acceptable latency. BigQuery Omni provides the most seamless multi-cloud analytics experience, running Google’s Dremel query engine on managed Kubernetes clusters within AWS or Azure regions. This architectural approach keeps raw data in its native cloud (S3 or Azure Blob), processes queries in-region to avoid egress charges, and returns only query results to GCP. The 60 GB per transfer limit for cross-cloud joins suits analytical workloads whilst Storage Transfer Service handles bulk data movement without size constraints. Twitter’s migration of 100+ petabytes from their European Hadoop clusters to GCP BigQuery demonstrates production viability, with query times dropping from hours to 1-2 minutes whilst eliminating data centre management overhead.
Service mesh integration through Istio or Linkerd enables sophisticated traffic management, security, and observability across heterogeneous Kubernetes clusters. PayPal’s Meridian connectivity fabric implements custom routing using HAProxy as the core component, connecting business units across AWS, GCP, Azure, and on-premises infrastructure through persistent HTTP/2 connections. Their architecture routes traffic based on domain names and URI paths, implements RFC 5785 IP ranges to solve overlapping address space challenges from acquisitions, and achieved 24% latency reduction compared to public CDN routing. The platform processes 1,000 payments per second during peak events whilst managing 3,500+ applications across their multi-cloud environment, demonstrating that thoughtfully designed integration layers can simplify rather than complicate operational complexity.
GCP service integration with AWS and Azure equivalents
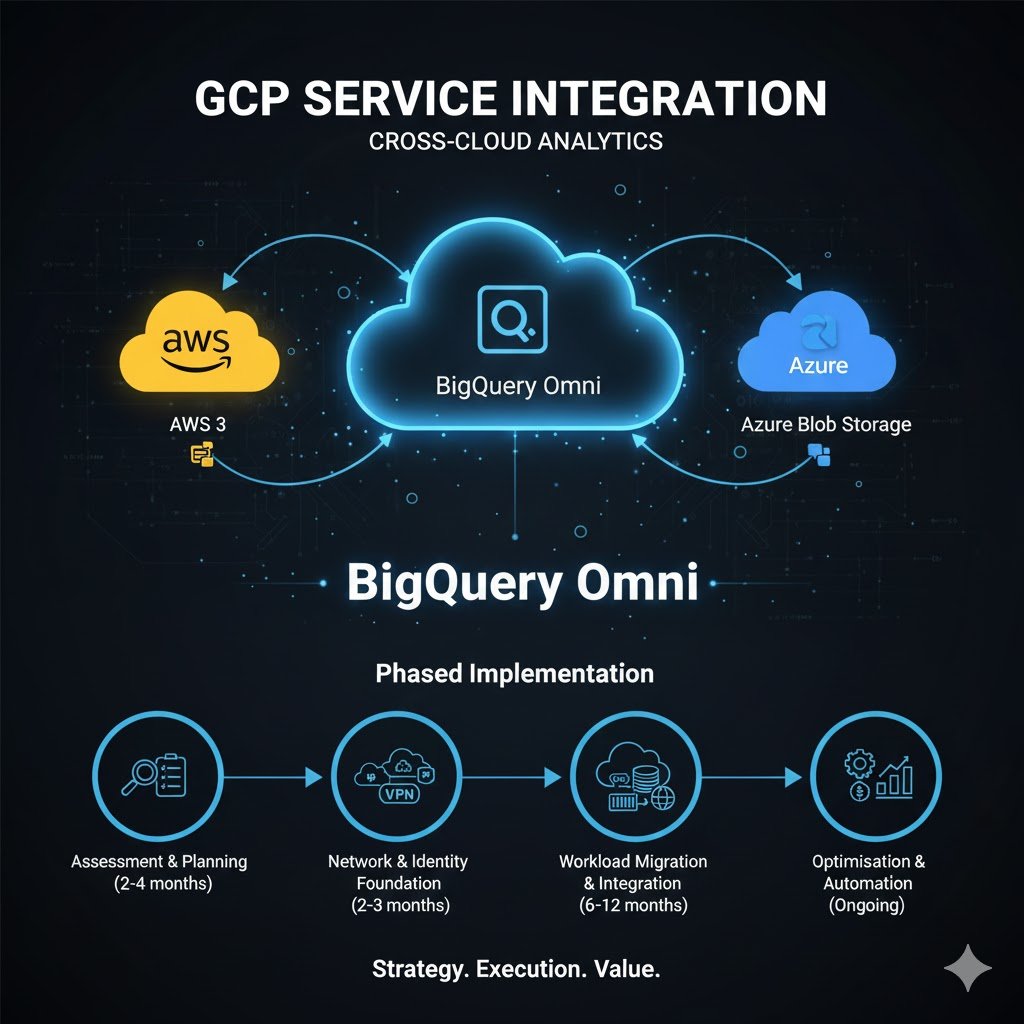
BigQuery’s cross-cloud analytics capabilities represent Google’s most compelling multi-cloud value proposition, with no egress fees for raw data stored in AWS S3 or Azure Blob Storage. The BigQuery Omni architecture deploys Anthos-managed Kubernetes clusters running the Dremel query engine in six AWS regions (us-east-1, us-west-2, eu-west-1, eu-central-1, ap-northeast-2, ap-southeast-2) and Azure’s eastus2 region, processing queries in-region before returning results. A media company case study demonstrates the economic model: storing 60 TB of video assets in S3 whilst querying through BigQuery Omni for analytics, with results aggregated to Azure storage for long-term archival, achieving 40% cost reduction compared to single-cloud architectures whilst maintaining data freshness under one hour.
The integration requires creating BigLake tables with AWS IAM role or Azure Active Directory authentication, establishing connection objects that BigQuery Omni uses to access external data. Cross-cloud materialised views provide continuous incremental replication with automatic refresh intervals from 30 minutes to 7 days, supporting filtering and transformation logic. Johnson & Johnson reported significantly faster performance than competing applications, running multi-user parallel queries without performance degradation across their multi-cloud data estate. The 60 GB per cross-cloud transfer limit steers architecture towards in-place querying rather than data movement, aligning economic incentives with best practices.
Container orchestration through Anthos Attached Clusters provides unified management of GKE, EKS, and AKS clusters through a single control plane, though the integration requires careful consideration of management plane dependencies and cost structures. Attaching non-GKE clusters to Anthos incurs $8 per vCPU monthly (or $10,000 per 100-vCPU block with subscriptions), charged against the attached cluster capacity rather than GCP infrastructure. This pricing must be weighed against operational efficiency gains from unified GitOps configuration management through Anthos Config Management, consistent policy enforcement via Policy Controller, and cross-cluster service mesh capabilities.
Target Corporation’s homegrown cluster management platform predates mature offerings like Anthos but demonstrates the architectural pattern’s viability. Their Target Application Platform (TAP) manages workloads across 1,926 stores, 48 distribution centres, 3 enterprise data centres, and public cloud deployments on GKE, Azure Container Instances, and AWS, supporting 5,400+ applications with 4,000+ engineers. The platform provides adapters for heterogeneous environments (Linux containers and vSphere VMs in private cloud, Kubernetes in stores and GCP, container instances in Azure), enabling developers to deploy via unified pipelines without understanding underlying infrastructure. Target achieved double the underlying compute utilisation through dynamic capacity allocation between on-premises and public clouds, eliminating the need to maintain 100%+ overcapacity for seasonal retail peaks.
Serverless integration between Cloud Functions, Lambda, and Azure Functions requires bridging disparate event models rather than relying on non-existent native cross-cloud triggers. Production patterns favour HTTP/webhook integration through API gateways, message queue bridges using Apache Kafka or managed services (Pub/Sub, SNS/SQS, Service Bus), and storage event chains where S3 events trigger Lambda functions that publish to Pub/Sub for consumption by Cloud Functions. Cold start characteristics vary meaningfully: Lambda averages 100-300ms (eliminated entirely with Provisioned Concurrency), Azure Functions 300-800ms (improved with Premium plans), and Cloud Functions 200-500ms. Execution time limits also differ: Lambda’s 5-minute default (15 minutes with Step Functions), Azure’s unlimited duration with Durable Functions, and Cloud Functions’ 9-minute maximum.
Machine learning model portability across Vertex AI, SageMaker, and Azure ML proves achievable through containerisation and ONNX format conversion, though federated learning remains nascent. The practical pattern trains models where data resides to minimise expensive cross-cloud data transfer, exports models to portable formats, and deploys inference endpoints across clouds via RESTful APIs. BNP Paribas’s implementation on Azure ML achieves 98.7% fraud detection accuracy whilst processing 14 million transactions per second, leveraging confidential computing with federated learning across geographically distributed data. HSBC’s Vertex AI deployment reduced scenario modelling time by 40% whilst running 16,000 parallel simulations for portfolio optimisation exceeding $9 billion, demonstrating the performance advantages of specialised cloud AI platforms when data gravity permits.
Storage integration proves straightforward technically but complex economically, with egress costs dominating TCO calculations. AWS charges $0.09 per GB for the first 10 TB monthly, Azure $0.087 per GB, and GCP $0.12 per GB for internet egress. Google’s Storage Transfer Service automates scheduled replication from S3 or Azure Blob to Cloud Storage, though organisations transferring more than 5-10 TB monthly achieve better economics through private interconnects reducing egress charges by 78%. A financial services case study demonstrates the pattern: production data in Azure Blob, disaster recovery replication to AWS S3 Glacier Deep Archive ($0.00099 per GB monthly), achieving 4-hour RPO whilst paying only $0.004 per GB monthly for archival storage. The 99.999999999% durability guarantee across all three providers eliminates durability concerns, leaving economics and access patterns as primary selection criteria.
Comparing management platforms: Anthos, Outposts, Arc, and alternatives
Google Anthos positions as the most open multi-cloud platform, supporting GKE, AWS EKS, Azure AKS, and conformant Kubernetes clusters through attached cluster registration whilst maintaining Kubernetes as the universal abstraction layer. The pricing model offers flexibility: pay-as-you-go at $8 per vCPU monthly, or subscription pricing at $10,000 per 100-vCPU block (billed in 100-vCPU increments, so 125 vCPUs requires payment for 200). This management-layer cost supplements underlying infrastructure. An Anthos deployment managing 100 vCPUs on AWS EKS incurs approximately $14,750-16,750 monthly including AWS EC2 instances ($2,750), Kubernetes control plane ($500-1,000), storage and networking ($1,500-3,000), and the Anthos management fee ($10,000).
The platform excels for container-first architectures with teams invested in Kubernetes expertise, offering genuinely cloud-agnostic operations through GitOps-based Anthos Config Management, unified service mesh via Istio integration, and consistent security policies through Policy Controller. Vendor lock-in remains minimal. Exit requires only Kubernetes expertise rather than Google-specific knowledge, though the management plane dependency on Google Cloud cannot be eliminated entirely. Gartner named Anthos a Leader in the 2024 Magic Quadrant for Strategic Cloud Platform Services, recognising its maturity and multi-cloud capabilities.
AWS Outposts takes a fundamentally different approach, extending AWS infrastructure and services to customer premises through AWS-managed hardware delivered as 42U racks or 1U/2U servers. The economics prove dramatically different: $246,000 to $900,000 for three-year rack commitments (all upfront pricing), with monthly AWS service charges adding substantial operational costs. RDS instances cost $3.60 hourly, EBS storage $0.15 per GB monthly, plus mandatory AWS Enterprise Support subscriptions. This capital-intensive model suits organisations requiring low-latency on-premises processing whilst maintaining identical AWS APIs and tooling, but eliminates multi-cloud capabilities entirely. Outposts serves only AWS ecosystem extension rather than cross-cloud management.
The value proposition centres on zero infrastructure management burden and perfect consistency with AWS cloud operations, making Outposts compelling for financial services firms requiring sub-10ms latency for trading platforms, manufacturers with factory-floor processing requirements, and healthcare organisations needing on-premises data processing for diagnostic equipment. However, the hardware lock-in and high capital requirements render Outposts unsuitable as a multi-cloud management layer, positioning it instead as a hybrid AWS deployment option competing with on-premises infrastructure investments.
Azure Arc delivers the lowest barrier to entry through its projection model, managing resources across AWS, GCP, on-premises, and edge locations without moving workloads or requiring specific hardware. The basic management tier remains free, including resource inventory, Azure management groups, tagging, Resource Graph search, and RBAC. Microsoft monetises through value-added services: Defender for Servers approximately $15 per server monthly, Azure Monitor based on data ingestion at $2.30 per GB, and Azure Arc-enabled data services using vCore-based pricing similar to native Azure offerings. This freemium model makes Arc the most accessible entry point for multi-cloud management, particularly for Microsoft-centric organisations extending Azure governance to other clouds.
Arc-enabled Kubernetes attaches any CNCF-conformant cluster for centralised management through the Azure Portal, enabling GitOps configuration, Azure Policy enforcement, and Azure Monitor integration without migrating workloads. The architectural pattern suits organisations with existing multi-cloud deployments seeking unified governance rather than infrastructure replacement. However, Arc remains fundamentally a management overlay rather than infrastructure delivery mechanism. It governs existing resources rather than provisioning new capacity, limiting its applicability for greenfield deployments where Anthos or native cloud services provide more comprehensive solutions.
Third-party platforms like HashiCorp Terraform, VMware Tanzu, and Cisco Intersight offer vendor-neutral alternatives with varying maturity and focus areas. Terraform’s infrastructure-as-code approach supports 1,000+ providers including AWS, Azure, and GCP, enabling declarative multi-cloud provisioning through HCL configuration files. The open-source edition remains free whilst HCP Terraform charges $20 per user monthly for the Standard tier, providing state management and policy enforcement through Sentinel. Terraform excels at infrastructure provisioning but provides no runtime management, making it complementary to rather than competitive with platform offerings like Anthos or Arc.
VMware Tanzu delivers comprehensive Kubernetes-based application platform capabilities including Tanzu Kubernetes Grid for multi-cloud distributions, Tanzu Mission Control for centralised cluster management, and developer-friendly abstractions through Tanzu Application Platform. The subscription-based licensing and deep VMware integration make Tanzu natural for organisations with existing VMware investments modernising to containers, though Broadcom’s acquisition creates pricing and strategy uncertainty affecting purchasing decisions. NetApp BlueXP differentiates through first-party storage services on all three major clouds (Cloud Volumes ONTAP, Amazon FSx for NetApp ONTAP, Azure NetApp Files, and Google Cloud NetApp Volumes), providing unified data management for storage-intensive workloads like AI/ML with large datasets and applications requiring consistent data services across hybrid environments.
Production implementations: case studies with metrics
PayPal’s multi-cloud architecture combining GCP, AWS, Azure, and on-premises infrastructure processes $1.6 trillion in annual payment volume across 377 million active accounts operating in 200+ countries. The post-eBay separation in 2015 created overlapping IP address spaces from acquisitions (all using 10.0.0.0/8 RFC 1918 ranges), necessitating innovative networking solutions. Their custom Meridian connectivity fabric implements HAProxy as the core routing component, using RFC 5785 IP range (198.18.0.0/15) to avoid conflicts whilst providing Inner Meridian for private business unit connectivity and Outer Meridian for external SaaS and partner integration. The architecture delivers 24% latency reduction compared to public CDN paths whilst processing 1,000 payments per second during Black Friday/Cyber Monday peaks, demonstrating that thoughtfully designed integration layers can simplify rather than complicate multi-cloud operations.
The measurable outcomes extend beyond performance improvements to operational transformation. Capacity additions that previously required 6 months plus 3-day maintenance windows now deploy same-day through cloud provisioning. PayPal shut down one Salt Lake City data centre by end of 2021, with 20% of core infrastructure migrated to Google Cloud as of 2021 and continuing growth. The self-service model enables application teams to onboard once to the service directory and immediately gain multi-cloud access, whilst persistent HTTP/2 connections between regions provide protocol translation for legacy application modernisation from HTTP/1.1.
Target Corporation’s homegrown Target Application Platform manages 5,400+ applications supporting 1,926 stores, 48 distribution centres, and 350,000 team members, serving 100 million monthly visitors to Target.com and mobile apps. The retailer’s multi-cloud strategy addresses seasonality. Retail demands 100%+ overcapacity during the 6-week Thanksgiving-Christmas peak period through dynamic workload placement across AWS, GCP, Azure, and extensive private cloud. Built before Anthos, Outposts, and Arc matured, TAP implements adapters enabling deployment to heterogeneous environments: Linux containers and vSphere VMs privately, Kubernetes in stores and GCP, container instances in Azure. Target achieved double the underlying compute utilisation whilst maintaining or improving reliability despite growing complexity, with 4,000+ engineers developing on the unified platform.
The architectural philosophy deliberately avoids vendor-specific PaaS offerings to maintain workload portability, leveraging Kubernetes as the abstraction layer where applicable whilst supporting edge deployments in stores and distribution centres for low-latency point-of-sale systems. Target contributes to approximately 300 open-source projects and publishes 24+ projects, demonstrating commitment to vendor-neutral technologies. The real-time service graph tracks critical dependencies across the distributed architecture, enabling faster troubleshooting and proactive issue detection. Most significantly, Target eliminated the need to invest in 100%+ overcapacity for seasonal peaks, achieving substantial capital expenditure savings through cloud bursting whilst maintaining sub-second response times for customer-facing applications.
Twitter’s analytics migration to GCP demonstrates large-scale data platform transformation, moving 100+ petabytes from the largest Hadoop cluster in Europe to cloud-native data processing. The social media platform uses AWS for real-time timeline delivery and user-facing services processing 300+ million active users, whilst GCP handles backend analytics, data warehousing, and machine learning workloads processing 8 million events per second. BigQuery replaced complex Hadoop operations requiring 20,000 daily jobs, with query times dropping from hours to 1-2 minutes for complex analyses. Cloud Dataflow processes large-scale streaming data through Apache Beam, whilst Cloud Pub/Sub provides event streaming replacing on-premises Kafka clusters.
Twitter developed Scio, a Scala API simplifying Dataflow operations, demonstrating the pattern of building cloud-agnostic abstractions atop native services. The architectural separation (AWS for user-facing synchronous workloads, GCP for asynchronous analytics) minimises cross-cloud communication and associated latency challenges whilst leveraging each provider’s strengths. The $1 billion multi-year Google Cloud commitment (reported before AWS partnership announcement) indicates enterprise-scale financial commitments typical of multi-cloud strategies, with $70 million monthly AWS infrastructure costs reported during 2022-2023 reflecting the dual-cloud investment required.
Form3’s fintech payment infrastructure implements simultaneous three-cloud architecture (AWS, GCP, Azure) to satisfy UK financial regulatory requirements for cloud portability and resilience. Their CockroachDB distributed SQL database spans all three clouds, functioning as a single logical database whilst automatically managing data distribution across providers. The Postgres-compatible interface provides developers with familiar SQL semantics despite the underlying multi-cloud complexity, with automatic query routing to correct nodes and regions. Form3’s engineers focus on business features rather than infrastructure management, leveraging managed Kubernetes control planes from each vendor (EKS, GKE, AKS) whilst CockroachDB handles cross-cloud data consistency.
The regulatory compliance driver proves particularly compelling in financial services, where Form3 successfully demonstrated to UK regulators the ability to operate if any single cloud provider became unavailable. The architecture achieves sub-100ms latency for payment processing whilst operating 24/7/365 with high availability requirements typical of financial infrastructure. Initially built on Amazon RDS for PostgreSQL before migrating to CockroachDB demonstrates the evolutionary path many organisations follow, starting single-cloud and expanding to multi-cloud as business requirements dictate rather than adopting multi-cloud prematurely.
The economics of multi-cloud: TCO analysis and hidden costs

Data egress charges between clouds represent the most significant hidden cost in multi-cloud architectures, with pricing structures favouring data at rest over data in motion. AWS charges $0.09 per GB for the first 10 TB monthly of internet egress, declining to $0.05 per GB above 150 TB, whilst Azure charges $0.087 per GB and GCP $0.12 per GB for equivalent volumes. A seemingly modest 10 TB monthly transfer between clouds costs $900-1,200 at standard rates ($10,800-14,400 annually), quickly escalating for data-intensive workloads. An organisation synchronising 100 TB monthly between clouds faces $96,000-144,000 in annual egress charges alone, often exceeding the cost of underlying compute resources processing that data.
Private interconnects dramatically improve economics at scale. AWS Direct Connect reduces egress to $0.02 per GB (a 78% reduction), with 10 Gbps circuits costing $1,643 monthly plus egress. For workloads transferring 10 TB monthly, total cost drops to $1,848 versus $2,543 monthly using VPN connectivity, achieving breakeven around 5-10 TB monthly transfer volumes. Azure ExpressRoute pricing runs higher at $5,000 monthly for 10 Gbps metered plans but includes redundant circuits, whilst Google Cloud Interconnect matches AWS Direct Connect pricing at $1,699 monthly for dedicated 10 Gbps. Cross-Cloud Interconnect (Google’s managed connectivity to AWS and Azure) charges premium pricing at $4,088 monthly for 10 Gbps but eliminates colocation requirements and provides unified Google SLAs.
Multi-cloud management platform costs layer substantial overhead atop infrastructure expenses. Anthos subscription pricing at $10,000 per 100-vCPU block monthly translates to $120,000 annually for modest 100-vCPU deployments, whilst FinOps platforms like Flexera One and CloudHealth typically charge 2-5% of total cloud spend ($20,000-50,000 annually for organisations spending $1 million on cloud infrastructure). Datadog multi-cloud monitoring costs $31 per host monthly versus $15 for single-cloud deployments, a 107% premium reflecting the additional complexity of cross-cloud observability. These tooling costs aggregate quickly: organisations using 5+ separate tools (63% of enterprises) with manual data consolidation (83% of enterprises) frequently exceed $50,000-150,000 in annual tooling overhead for mid-sized deployments.
The staffing premium proves even more substantial than direct technology costs. Single-cloud DevOps engineers command $90,000-120,000 annually in US markets, whilst multi-cloud experts require $120,000-150,000 (a 25-35% premium) reflecting scarcity and breadth of required expertise. Cloud architects with multi-cloud experience range $140,000-180,000, and FinOps practitioners $100,000-140,000. Team size requirements increase proportionally: small organisations require 2-3 full-time equivalents for multi-cloud versus 1-2 for single-cloud (50% increase), medium enterprises 5-8 versus 3-5 (60% increase), and large organisations 15-20 versus 8-12 (67% increase). Training investments add $5,000-10,000 annually per engineer for certifications and skills development across multiple platforms.
Forrester Total Economic Impact studies quantify achievable ROI under optimal conditions. Microsoft Azure Arc delivered 304% ROI over three years with less than 6-month payback periods, achieving 30% IT operations productivity gains, 10% licensing savings on Windows Server and SQL Server, 15% reduction in third-party tool costs, and 50% security breach risk reduction. However, these results required mature FinOps practices and dedicated platform teams. Only 8% of organisations achieve “high cloud maturity” according to HashiCorp’s State of Cloud Strategy Survey conducted by Forrester with 1,200 respondents. Organisations lacking this maturity see substantially different outcomes, with 50%+ failing to realise expected multi-cloud benefits by 2029 according to Gartner projections.
The hidden operational complexity manifests in incident response metrics. Single-cloud outages average 4 hours mean time to resolution (MTTR), whilst multi-cloud incidents require 12 hours average (3x longer) due to cross-cloud coordination challenges where AWS support blames Azure, Azure blames GCP, and engineering teams manually correlate logs and metrics across disparate observability platforms. Context switching between cloud consoles and tools costs 15-25% of developer productivity, translating to $30,000-50,000 annually per engineer in lost output. Security tooling costs triple: single-cloud security runs $20,000-40,000 annually whilst multi-cloud platforms like Prisma Cloud or Wiz demand $60,000-120,000 for equivalent coverage.
The total cost comparison reveals the true multi-cloud premium. A hypothetical single-cloud deployment costing $100,000 annually in infrastructure with 3-person platform team ($450,000 in staffing) and $10,000 in tooling totals $560,000 annually. The equivalent multi-cloud deployment costs $105,000 infrastructure (+5% complexity overhead), $25,000-50,000 egress charges, 4-5 person team ($600,000), $50,000 tooling, and $20,000 training, totalling $775,000 annually. The 38% TCO increase requires offsetting benefits: 20%+ cost reductions through vendor competition, 30%+ performance improvements justifying premium, or non-negotiable regulatory requirements mandating specific providers.
Phased implementation: from assessment to optimisation
Multi-cloud integration requires deliberate phased execution spanning 12-24 months for enterprise-scale implementations, with Phase 1 assessment and planning consuming 2-4 months establishing the foundation for technical success. Business case development must quantify expected benefits with specificity (30% cost reduction through vendor negotiation leverage, 50% performance improvement for analytics workloads through BigQuery, mandatory compliance requirements for specific regulatory frameworks) rather than theoretical vendor independence claims. Infrastructure inventory and dependency mapping identify application relationships, technical debt, licensing constraints, and performance requirements guiding migration wave planning. The 6 Rs framework (rehost, replatform, refactor, repurchase, retire, retain) classifies workloads by appropriate migration strategy, with most organisations discovering 20-30% of applications can be retired and 40-50% rehosted with minimal modifications.
Wave planning groups applications by dependencies, criticality, and complexity, prioritising non-production environments followed by low-dependency applications before tackling business-critical systems. Target’s implementation explicitly started with development and test workloads, validating the Target Application Platform’s capabilities before migrating customer-facing production systems. This approach builds organisational confidence whilst enabling platform teams to refine processes and tooling with limited blast radius. Risk assessment must honestly evaluate organisational readiness: organisations spending less than $1 million annually on cloud lack sufficient scale to justify multi-cloud complexity, whilst those lacking dedicated platform teams (minimum 5-8 engineers for medium enterprises) will struggle with operational overhead.
Phase 2 network and identity foundation establishes the connectivity and security infrastructure supporting all subsequent workload migration, typically requiring 2-3 months for proper implementation. Landing zone design implements hub-and-spoke network topology across clouds, with AWS Transit Gateway, Azure Virtual WAN, or third-party solutions like Aviatrix providing centralised routing. VPN connectivity provides initial validation at lower cost and risk before progressing to dedicated interconnects (AWS Direct Connect, Azure ExpressRoute, Google Cloud Interconnect) for production workloads transferring more than 5-10 TB monthly where economics favour private connectivity despite higher fixed costs.
Identity federation through centralised providers (Azure Active Directory, Okta, AWS IAM Identity Center) implements SAML 2.0 single sign-on across all cloud platforms, with workload identity federation enabling service-to-service authentication without long-lived credentials. PayPal’s implementation federated identities across GCP, AWS, Azure, and on-premises infrastructure, with HAProxy Fusion Control Plane providing unified observability whilst the Meridian fabric handled network routing. Security baseline configuration includes encryption at rest and in transit, network segmentation through security groups and network policies, centralised log aggregation to SIEM platforms, and baseline monitoring with alerting through unified observability platforms like Datadog or New Relic.
Phase 3 workload migration and integration consumes 6-12 months executing wave-based migrations with rigorous testing and validation protocols. The migration factory approach establishes standard operating procedures, automated tooling, and health metrics enabling predictable execution at scale. Twitter’s Hadoop migration to GCP BigQuery demonstrates the pattern: initial pilot processing non-critical analytics workloads, followed by progressive migration of 20,000 daily Hadoop jobs to cloud-native data processing over 18+ months. Pre-migration activities validate dependencies, size resources appropriately, test connectivity, and create comprehensive backups. Migration execution performs data replication, application deployment, DNS cutover, and real-time monitoring, with immediate rollback capabilities if health metrics degrade. Post-migration validation includes functional testing, performance validation comparing to baseline metrics, security scanning for misconfigurations, and comprehensive documentation enabling operational teams to support migrated workloads.
Phase 4 optimisation and automation begins 2-4 months into operation but continues indefinitely, targeting the 30% cloud waste typical of unoptimised multi-cloud deployments. Cost optimisation through rightsizing recommendations from AWS Compute Optimizer, Azure Advisor, and GCP Recommender typically yields 20-35% savings on compute costs by reducing oversized instances. Reserved instance and savings plan purchases deliver 30-40% discounts on predictable workloads, whilst spot and preemptible instances provide up to 90% savings for fault-tolerant batch processing. Storage lifecycle policies automatically tier infrequently accessed data to cheaper storage classes, reducing storage costs by 50-80% through intelligent automation. Target achieved double the compute utilisation through dynamic workload placement and continuous optimisation, validating the substantial efficiency gains possible with mature operations.
When to embrace or avoid multi-cloud complexity
Multi-cloud integration makes strategic sense for organisations meeting specific criteria, with annual cloud spend exceeding $5 million representing the approximate threshold where complexity costs justify potential benefits. Regulatory compliance requirements provide the clearest justification: financial services firms operating globally face data sovereignty mandates requiring specific providers in particular jurisdictions, healthcare organisations navigate HIPAA and regional privacy laws favouring multi-cloud data residency patterns, and public sector entities encounter procurement rules or sovereignty requirements mandating domestic cloud options. Form3’s three-cloud architecture exists specifically because UK financial regulators require demonstrated cloud portability, an external mandate leaving little discretion in architectural approach.
Best-of-breed service selection justifies multi-cloud when specific capabilities deliver 10x+ improvements versus alternatives. GCP’s BigQuery processes analytical queries 54% faster than competing data warehouses with serverless scaling eliminating capacity planning, making it compelling for data-intensive organisations despite requiring integration with existing AWS or Azure infrastructure. Twitter’s analytics platform migration demonstrates this calculus: the performance and operational improvements from moving 100+ petabytes to GCP-native services like BigQuery and Dataflow justified the multi-cloud complexity, with query times dropping from hours to minutes whilst eliminating management of 20,000 daily Hadoop jobs. Similarly, organisations heavily invested in Microsoft 365 and Active Directory find Azure’s native integration reduces complexity rather than increasing it, even when primary compute workloads remain on AWS.
Post-merger integration frequently creates multi-cloud by accident rather than design, with acquired companies bringing established cloud platforms and technical expertise. The business case for consolidation must weigh migration costs ($430,000 to $1,070,000 per major application including assessment, data migration, refactoring, and testing) against ongoing operational overhead. PayPal’s situation illustrates this pattern: the eBay separation created overlapping IP address spaces from multiple acquisitions, all using 10.0.0.0/8 RFC 1918 ranges privately, requiring innovative networking solutions rather than expensive renumbering projects. When integration costs exceed ongoing operational overhead savings, maintaining heterogeneous cloud platforms with robust integration layers proves more economical than forced consolidation.
Organisations should avoid multi-cloud when adopting it by default without clear business justification, as Gartner research indicates 89% of multi-cloud deployments emerge organically rather than strategically, leading to the prediction that 50%+ will fail to achieve expected benefits by 2029. Enterprises spending less than $1 million annually on cloud lack sufficient scale to absorb the 38% TCO premium from multi-cloud operations. Small operational teams with fewer than 5 engineers cannot maintain expertise across multiple platforms whilst managing day-to-day operations, leading to operational burnout and increased incident frequency. Applications with tightly coupled architectures requiring sub-50ms latency between components will experience substantial performance degradation from cross-cloud communication, making single-cloud deployment mandatory unless components can be decoupled.
Theoretical vendor lock-in concerns prove insufficient justification without quantifiable negotiating leverage. Organisations must demonstrate the ability to credibly switch providers (requiring workload portability, budget authority, and executive commitment to migration) before vendors provide meaningful discounts. Simply running workloads on multiple clouds without genuine portability yields no negotiating leverage whilst incurring full complexity costs. The decision framework evaluates latency sensitivity (high sensitivity favours single cloud), annual spend (less than $5 million suggests single cloud), team size (fewer than 10 engineers complicates multi-cloud), and integration patterns (tightly coupled applications cannot span clouds effectively).
Emerging patterns and future considerations
Kubernetes has solidified its position as the universal abstraction layer for multi-cloud workload portability, with 80% of customers preferring managed Kubernetes (EKS, AKS, GKE) over self-managed clusters according to Forrester research. The maturity of service mesh implementations (Istio, Linkerd, Consul) enables sophisticated traffic management, security through mutual TLS, and unified observability across heterogeneous Kubernetes clusters spanning clouds. Lunar Bank operates 9 Kubernetes clusters across AWS, Azure, and GCP running 250+ microservices with Linkerd service mesh and GitOps-based configuration management, demonstrating production viability of truly cloud-agnostic operations for appropriately architected applications. However, the 80/20 reality persists: whilst Kubernetes abstracts compute orchestration effectively, the remaining 80% of technical stack (databases, networking, security, monitoring) remains cloud-specific, limiting portability to containerised application logic rather than complete systems.
AI and machine learning workloads increasingly drive multi-cloud adoption, with 72% of organisations using generative AI services according to Flexera’s 2025 data. The competitive landscape creates genuine differentiation: GCP’s Vertex AI provides native TensorFlow integration and TPU acceleration, AWS SageMaker offers the broadest selection of algorithms and frameworks with recent Inferentia3 launch for cost-effective inference, whilst Azure ML delivers confidential computing capabilities essential for regulated industries and deep integration with Microsoft’s Cognitive Services. BNP Paribas achieved 98.7% fraud detection accuracy processing 14 million transactions per second through Azure ML’s confidential computing with federated learning, whilst HSBC reduced scenario modelling time by 40% running 16,000 parallel simulations through Vertex AI. The pattern emerging involves training models where data resides to avoid expensive cross-cloud transfer, exporting to portable formats like ONNX, and deploying inference endpoints across clouds via RESTful APIs for geographic distribution and resilience.
FinOps maturity has emerged as the critical success factor separating successful from failed multi-cloud implementations. The FinOps Foundation framework provides standardisation around cost allocation, forecasting, resource optimisation, and commitment-based discount management, with 50%+ of organisations now establishing dedicated FinOps teams. The FOCUS billing standard (FinOps Open Cost and Usage Specification) gains momentum with AWS, Microsoft, and Google supporting vendor-neutral cost views, addressing the fragmentation where organisations use 5+ separate tools with 83% manually consolidating data. Organisations with mature FinOps practices (maturity level 3+) achieve 30-40%+ cost savings through continuous optimisation, whilst those lacking discipline see the 30% cloud waste typical of unmanaged multi-cloud deployments.
Infrastructure-as-code has become mandatory rather than optional, with Terraform achieving near-universal adoption for multi-cloud provisioning through 1,000+ provider support and cloud-agnostic HCL configuration language. The pattern combines Terraform for infrastructure provisioning, GitOps tools like ArgoCD or Flux for Kubernetes application deployment, and policy-as-code frameworks like Open Policy Agent for security and compliance enforcement. Target’s contribution to 300+ open-source projects and publication of 24 projects demonstrates the industry trend towards shared tooling and vendor-neutral technologies, reducing dependency on proprietary management platforms whilst building community expertise applicable across multiple organisations.
Strategic recommendations for platform architects
Multi-cloud adoption decisions should follow rigorous evaluation frameworks rather than technology trends or vendor marketing. Start with honest assessment of organisational readiness: annual cloud spend, platform team size and expertise, application architecture coupling, and concrete business drivers justifying complexity. Enterprises spending less than $1 million annually should master single-cloud operations deeply, achieving FinOps maturity level 3 and building comprehensive automation before considering multi-cloud expansion. The 38% TCO premium requires offsetting through measurable benefits (20%+ cost reductions, 30%+ performance improvements, or non-negotiable regulatory requirements) rather than theoretical vendor independence.
For organisations meeting the scale and capability thresholds, implement in deliberate phases spanning 12-24 months: assessment and planning (2-4 months), network and identity foundation (2-3 months), workload migration and integration (6-12 months), and continuous optimisation (ongoing). Start with non-production environments and low-dependency applications, building confidence and refining processes before migrating business-critical systems. PayPal and Target both followed staged approaches validating their custom integration platforms with limited-risk workloads before expanding to production systems processing billions of dollars in transactions.
Invest heavily in automation and unified tooling from day one, implementing 100% infrastructure-as-code through Terraform or equivalent, establishing CI/CD pipelines for consistent deployment, and deploying unified observability platforms like Datadog or New Relic providing single-pane-of-glass visibility. The tooling investment ($50,000-150,000 annually for mid-sized enterprises) pales compared to manual operational costs from fragmented point solutions. Establish FinOps practices immediately with cost allocation, budget alerts, and quarterly optimisation reviews targeting elimination of the 30% waste typical of unmanaged deployments.
Security by design proves far cheaper than retrofitting, with Microsoft’s 2024 research indicating organisations average 351 exploitable attack paths and 80% of breaches resulting from misconfigurations rather than sophisticated attacks. Implement Zero Trust architecture from inception: centralised identity federation through Azure AD or Okta, workload identity for service authentication eliminating long-lived credentials, network segmentation through security groups and microsegmentation, and Cloud Security Posture Management platforms like Wiz or Prisma Cloud providing automated misconfiguration detection and remediation. The 50% security breach risk reduction documented in Azure Arc’s Forrester TEI study translates directly to avoided incident costs averaging $4.45 million per breach according to IBM research.
Build genuine cloud expertise rather than superficial knowledge across multiple platforms, with successful organisations maintaining 2-3 specialists per major cloud platform. Budget $5,000-10,000 annually per engineer for training, certifications, and continuous learning, recognising the 25-35% salary premium for multi-cloud expertise reflects genuine market scarcity. Consider strategic use of consultants for 6-12 months during initial implementation to accelerate capability development, but avoid dependency on external parties for ongoing operations which indicates insufficient internal expertise.
The multi-cloud decision ultimately rests on honest cost-benefit analysis incorporating the full complexity premium. Organisations meeting the criteria (exceeding $5 million annual cloud spend, maintaining 10+ person platform teams, possessing clearly articulated business drivers delivering 10x improvements or regulatory necessity) will find multi-cloud delivers measurable strategic value when implemented with discipline and mature operational practices. Those lacking these characteristics should focus on deep single-cloud expertise, achieving excellence in one platform before entertaining multi-cloud complexity that statistically fails to deliver expected benefits for most organisations.
Useful Links
- Google Anthos Documentation – Official technical documentation for Anthos multi-cloud platform
- AWS Direct Connect Pricing – Current pricing for AWS dedicated network connectivity
- Azure Arc Overview – Microsoft’s multi-cloud management platform details
- Flexera State of the Cloud Report 2024 – Annual industry research on cloud adoption trends
- Gartner Magic Quadrant for Strategic Cloud Platform Services – Vendor analysis and positioning
- FinOps Foundation Framework – Industry standard for cloud financial management
- BigQuery Omni Documentation – Multi-cloud analytics capabilities and setup
- CNCF Cloud Native Landscape – Comprehensive map of cloud-native technologies
- Forrester Total Economic Impact Studies – ROI research methodology and case studies
- HashiCorp Terraform Multi-Cloud Tutorials – Infrastructure-as-code implementation guides