Most teams treat Lambda cold starts as a performance problem to be fixed. The more experienced position is to treat them as a design constraint to be managed, and to be precise about which functions actually need managing. According to AWS’s own analysis of production Lambda workloads, cold starts occur in fewer than 1% of invocations at steady state. The engineers spending engineering cycles warming every function in their estate, or paying for Provisioned Concurrency across the board, are solving a problem that mostly does not exist while creating a cost one that definitely does. The August 2025 change to INIT-phase billing made this calculus concrete: cold starts are now a budget line, not just a latency footnote, and for UK financial services firms operating under FCA/PRA operational resilience impact tolerances that came into full force in March 2025, they are also a governance requirement.
The failure mode that gets teams into trouble is treating cold start mitigation as a binary. Either you have a cold start problem or you do not, and if you do, you enable Provisioned Concurrency and move on. The reality is more structured than that. Different functions in the same estate have different invocation patterns, different latency tolerances, and dramatically different mitigation costs. A synchronous API handler processing payment confirmations has nothing in common with an async event processor consuming from SQS, even if both run on Lambda and both occasionally cold-start. Applying the same mitigation strategy to both is how teams end up with a Provisioned Concurrency bill 17 times higher than their on-demand compute costs for workloads that never needed it.
The framework in this post maps five decision variables (latency SLA, invocation pattern, init duration, traffic predictability, and throughput volume) to four response strategies: do nothing, optimise the init phase, apply SnapStart, or apply Provisioned Concurrency. It also covers the two exit ramps: Fargate/ECS for steady high-throughput workloads, and the new Lambda Managed Instances for the middle ground that previously had no good answer. WirelessCar used SnapStart to reduce Java function initialisation from four seconds to 0.4 seconds, a 90% reduction, at no additional cost. Smartsheet combined Provisioned Concurrency with auto-scaling and a move to Graviton to cut p95 latency by 83% while reducing GB-second costs by 20%. The mechanism matters. Choosing the right one for the right function is the skill.
Why Cold Starts Got Worse Before They Got Better
Lambda’s cold start story has two distinct eras. Before 2019, VPC-attached functions carried a genuine and significant penalty: creating an Elastic Network Interface in the customer’s VPC took several seconds and made VPC attachment something to avoid unless the function genuinely needed private resource access. The Hyperplane ENI architecture change moved ENI creation to function creation and update time, removing most of that penalty. By 2025, the remaining VPC attachment cost, the Geneve tunnel setup, that routes the function’s traffic into the customer VPC, had been reduced to the point where AWS engineering described the end result as adding roughly 200 microseconds of tunnel latency, down from 150 milliseconds before the eBPF-based rework. The DHCP portion of network setup remains an open optimisation as of mid-2026, contributing under 50-100ms in most real-world measurements, but the era of VPC attachment being a reason to architect around Lambda is effectively over.
What has not changed is the fundamental structure of the INIT phase. When Lambda has no warm execution environment available, it allocates a Firecracker microVM, boots the language runtime, downloads and mounts the deployment package or container image, initialises any Lambda extensions, and runs all code outside the handler function: global variables, SDK client initialisation, database connection setup, configuration loading. Only after all of that completes does the handler execute. The duration of this phase ranges from under 100ms for a lightweight Node.js or Python function with minimal dependencies to over five seconds for a Spring Boot application with a deep dependency graph. Runtime is the single biggest lever on cold-start magnitude: Node.js and Python typically initialise in 200-400ms; Go often under 200ms; Java and .NET frequently 500ms to two seconds and beyond for heavy frameworks.
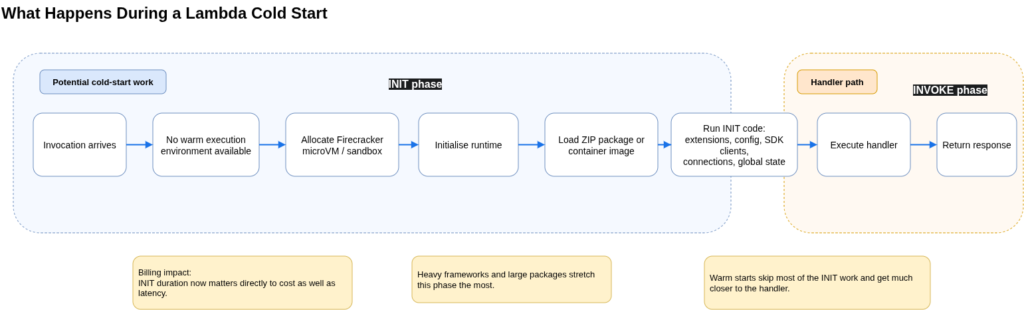
The August 2025 INIT billing change added a direct financial dimension to this. Previously, ZIP-packaged functions using managed runtimes did not bill the INIT phase on on-demand invocations; custom runtimes, container images, and Provisioned Concurrency already did. Now INIT duration is included in Billed Duration across all configurations. AWS’s framing was that most users would see minimal impact given that cold starts affect fewer than 1% of invocations. That is accurate for steady-state, high-traffic functions. For low-traffic functions with heavy init code, the internal tooling endpoint that gets hit intermittently, the scheduled job that cold-starts every time, the change can increase Lambda spend by 10-50% for those functions. The practical consequence is that optimising init code now has a return on the monthly bill, not just on latency.
The other meaningful shift in 2025-2026 is the container image cold-start story. Historically, container images cold-started significantly slower than ZIP packages, sometimes by multiple seconds. AWS’s on-demand container loading work uses block-level demand loading, deduplication across a multi-tier cache, and layer optimisation to reduce the time needed to make a container function ready to execute. For larger packages, especially where dependency management or reproducible builds matter, container images are no longer automatically a cold-start anti-pattern. Teams should benchmark the specific runtime and package size rather than assuming ZIP is always faster; the gap that previously made container images difficult to justify on latency grounds has narrowed substantially.
The Technical Architecture of Cold Start Mitigation
SnapStart: The Underused Free Mechanism
SnapStart is the most underused cold start mitigation in the Lambda toolkit, primarily because it launched as Java-only in 2022 and the expansion to Python 3.12 and .NET 8 in late 2024 has not fully penetrated enterprise adoption patterns. As of mid-2026, it is GA across 23 regions including London. The mechanism is conceptually simple: Lambda initialises the function once at publish time, takes a Firecracker microVM snapshot (memory and disk state), encrypts it, and caches copies. Cold starts restore from the snapshot instead of running the INIT phase, reducing startup from seconds to the restoration duration, which AWS benchmarks show in the 30-280ms range depending on memory allocation and snapshot size.
The cost model makes SnapStart the default choice for eligible functions with heavy init. For Java, it is free: there is no charge for snapshotting or restoration, just the standard execution pricing. For Python and .NET, snapshot caching and restoration carry a small additional charge, but this is typically far below the cost of Provisioned Concurrency for the same workload. WirelessCar’s Java functions dropped from 4 seconds initialisation to 0.4 seconds after enabling SnapStart, with no architectural changes beyond the configuration toggle and runtime hook implementation.
The limits are real and need to be understood before enabling. SnapStart is mutually exclusive with Provisioned Concurrency: you choose one mechanism, not both. It does not support EFS-mounted filesystems. Ephemeral storage is capped at 512MB. It operates on published versions only, not $LATEST. Container images are not eligible; it applies only to managed runtimes. Architecture support varies by runtime: Java functions support both x86 and ARM64/Graviton, but verify the current documentation for Python and .NET before assuming ARM64 is available for your specific runtime and version combination, as support has expanded incrementally. The most significant design consideration is uniqueness: anything generated during the INIT phase that needs to be unique per environment (random seeds, UUIDs, cached DNS resolutions, database connections, credentials fetched from Secrets Manager) is frozen into the snapshot and reused across restored environments. AWS provides runtime hooks (the CRaC interface for Java, the Snapshot Restore library for Python) to regenerate these after restoration. Skipping this step causes subtle bugs that are hard to reproduce and hard to diagnose.
AWS’s own guidance on when not to use SnapStart is worth noting directly: if your functions initialise within hundreds of milliseconds, the improvement is unlikely to be significant, and Provisioned Concurrency is the better choice for guaranteed double-digit-millisecond latency. SnapStart targets the seconds-to-sub-second improvement; it does not target sub-100ms cold starts.
Provisioned Concurrency: Surgical Application Only
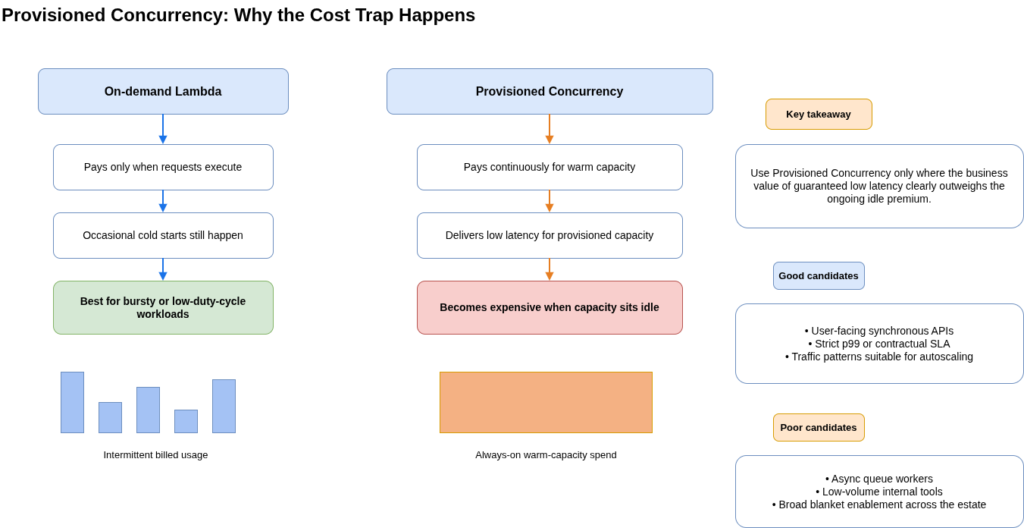
Provisioned Concurrency pre-initialises a configured number of execution environments so that invocations hit the INVOKE phase directly, delivering latency in the tens of milliseconds rather than hundreds or thousands. It is the right answer for a specific and narrow set of problems: synchronous, user-facing functions with strict p99 SLAs where SnapStart is either unavailable or insufficient.
The cost model is the reason it must be applied surgically. Provisioned Concurrency charges continuously on warm capacity whether invocations are happening or not: $0.0000041667 per GB-second on x86 in standard-tier regions including London, 24 hours a day, seven days a week. ARM/Graviton reduces this by approximately 20%. A 1GB function with 10 provisioned instances costs roughly £81 per month in warm-capacity charges alone, before any execution billing. The same 1GB function handling 5 million requests at 150ms average duration on pure on-demand costs roughly £5 per month. This is not a marginal difference; it is an order-of-magnitude premium for a specific latency guarantee. Caylent’s cost analysis makes the structural point directly: even a function invoked every single second of every day is cheaper on on-demand than with one unit of Provisioned Concurrency: PC does not reduce costs and should only be considered as a latency tool.
The correct operational discipline for Provisioned Concurrency is auto-scaling against the ProvisionedConcurrencyUtilization metric. Smartsheet’s implementation, documented in the AWS Architecture Blog, used a 60% utilisation target for interactive API functions (prioritising availability headroom) and a 90% utilisation target for async data processing functions (prioritising cost). Consistent utilisation below 50% is the signal to either cut provisioned capacity or switch to SnapStart. Consistent ProvisionedConcurrencySpilloverInvocations (on-demand cold starts occurring because burst exceeded provisioned capacity) is the signal to increase it or reconsider the workload pattern.
Async Invocation: The Free Mitigation Most Teams Ignore
The architectural decision that removes cold start from the caller’s synchronous latency path for a large proportion of Lambda functions costs nothing and requires no configuration change: move the work behind a queue. Cold starts on asynchronous invocations via SQS, EventBridge, or direct async Lambda invocation are absorbed by the queue, not experienced by the caller. The end user or upstream service receives an acknowledgement immediately; the function initialises in the background. This removes cold start from the user-facing response, though it does not remove it from the end-to-end processing time, which still matters for workloads with downstream SLAs, backlog risk under burst, or retry behaviour that is sensitive to processing latency. This pattern is appropriate for a significant proportion of enterprise Lambda workloads: data processing, transformation pipelines, notification dispatch, audit logging, downstream integration calls, and any workflow step where a synchronous response is not required.
AWS’s load testing of their own reference architecture (“Ask Around Me“) showed that Provisioned Concurrency applied to the synchronous, user-facing Lambda function cut the slowest execution time by 75%. The async functions in the same architecture did not need it, because async invocation already absorbed the cold start outside the user’s latency budget. The discipline is to map invocation pattern first, before reaching for a mitigation mechanism: synchronous and user-facing, or async and fire-and-forget? The answer determines whether cold start mitigation is even necessary.
Container Image Loading and Response Streaming
Two additional architectural tools are worth including in the decision framework, though they target narrower use cases. AWS’s on-demand container loading improvements have substantially reduced the historical cold-start penalty for container-packaged functions. Teams running containerised Lambda functions to gain reproducible builds, precise dependency control, or larger image sizes should benchmark their specific runtime and package size before assuming ZIP is the faster option; the decision is no longer as one-sided as it once was.
Response streaming, available via function URLs and the InvokeWithResponseStream API, does not reduce cold start duration but reduces perceived latency by sending partial responses as they are generated rather than buffering the complete response. For LLM-backed functions, large report generation, or any function where time-to-first-byte matters more than total duration, streaming changes the user experience significantly. Lambda response streaming now supports streamed payloads up to 200MB, compared with the 6MB maximum for buffered responses, and became available across all commercial AWS regions in April 2026. Lambda buffers chunks smaller than approximately 10KB, so the first chunk may still take one to two seconds. Streaming is not a substitute for cold start mitigation on functions that must respond in under 200ms.
Mitigation Strategy Comparison
| Mechanism | Cold Start Reduction | Cost Impact | Eligible Runtimes | Latency Achieved |
|---|---|---|---|---|
| Optimise init code | Partial (30-60%) | Neutral or positive | All | Varies |
| SnapStart | 80-95% | Free (Java) / low additional cost (Python, .NET) | Java 11+, Python 3.12+, .NET 8+ | Sub-second |
| Provisioned Concurrency | 100% (eliminates) | High premium (continuous) | All | Double-digit ms |
| Async invocation | 100% (user-facing) | None | All | N/A (absorbed) |
| Move to Fargate/ECS | N/A (no cold start) | Higher baseline, lower peak | All | Sub-10ms p99 possible |
| Lambda Managed Instances | Reduced frequency | EC2 pricing + 15% management fee (discounts apply to EC2 component only) | All | Lower variance |
Real-World Case Studies
Company Name and Industry: Smartsheet, Enterprise SaaS (work management platform)
Scale Context: Hundreds of Lambda functions across the platform; sustained high-concurrency API traffic
Challenge: Cold start tail latency on synchronous API paths was degrading user experience under burst, with insufficient cost discipline on Provisioned Concurrency configuration.
Solution Implemented: Provisioned Concurrency with auto-scaling on the LambdaProvisionedConcurrencyUtilization metric (60% target for interactive APIs, 90% for async processing), combined with a migration from x86 to ARM/Graviton across the function fleet, implemented via Terraform.
Measurable Outcomes:
- 83% reduction in p95 invocation latency on synchronous API paths
- 20% reduction in GB-second costs from x86 to Graviton migration
- Consistent service quality maintained through continued platform growth
Source: https://aws.amazon.com/solutions/case-studies/smartsheet-lambda-case-study/
Cost Analysis and ROI
The cost arithmetic of Lambda cold start mitigation is worth working through precisely, because the right mechanism varies significantly depending on workload profile and the wrong choice is expensive.
On-demand Lambda pricing in standard-tier regions (including London/eu-west-2) sits at $0.0000166667 per GB-second on x86, with ARM/Graviton approximately 20% cheaper at $0.0000133334 per GB-second. Requests cost $0.20 per million. From August 2025, INIT duration is included in Billed Duration across all configurations, meaning a 1GB function with a 1-second cold start on an on-demand invocation adds $0.0000166667 to that invocation’s bill. For a function cold-starting on 1% of 10 million monthly invocations, 100,000 cold starts. The monthly INIT billing impact is approximately $1.67. Meaningful for a function with 5-second Java init (approximately $8.33 per month in INIT charges alone at that volume), negligible for a 200ms Python function.
Provisioned Concurrency changes the calculus entirely. Ten provisioned instances of a 1GB function cost approximately $109 per month in warm-capacity charges at current rates (730 hours × 10 instances × 1GB × $0.0000041667). That same function handling five million monthly requests at 150ms average duration costs roughly $6.60 per month on pure on-demand. The premium for eliminating cold starts on that workload is approximately 16.5x the baseline compute cost. This premium is justified when the cold-start tail latency creates a business impact (lost transactions, FCA/PRA tolerance breach, contractual SLA penalty) that exceeds the monthly delta. For most workloads, it is not justified.
SnapStart changes the mitigation cost model for eligible runtimes. Java SnapStart costs nothing beyond standard execution pricing. Python and .NET SnapStart carry a snapshot storage and restoration charge, but at typical function sizes and invocation rates this is far below the Provisioned Concurrency alternative. For a Java function with 3-5 second initialisation and moderate traffic, SnapStart can achieve a comparable user-facing latency improvement to Provisioned Concurrency at essentially zero additional cost. The WirelessCar deployment illustrates this: the economic case for SnapStart was the primary driver alongside the latency benefit.
The three-to-five year TCO picture requires accounting for the full cost of operations. Our FinOps Evolution guide covers the broader cost discipline frameworks that apply here. The key Lambda-specific point is that Provisioned Concurrency requires ongoing operational attention (monitoring utilisation, adjusting capacity, preventing idle overspend) that on-demand and SnapStart do not. Auto-scaling Provisioned Concurrency via Application Auto Scaling reduces but does not eliminate this overhead. Factor in two to four hours of engineering time per quarter per significant function cluster when modelling the true cost of a Provisioned Concurrency strategy.
Fargate/ECS becomes worth modelling when Lambda traffic is sustained and predictable enough that always-on container capacity would remain highly utilised. The signals are functions running for hundreds of milliseconds or longer, workloads approaching the 15-minute execution limit, persistent connection requirements, or situations where Lambda cannot economically deliver the required latency variance under burst. There is no universal TPS crossover point: the decision should be modelled using the actual memory size, duration, concurrency, regional pricing, and Savings Plan assumptions for the specific workload rather than applied as a rule of thumb.
The Decision Framework for Lambda Cold Starts
The framework operates as a sequential triage. Work through the stages in order; stop when you reach the right answer for each function.
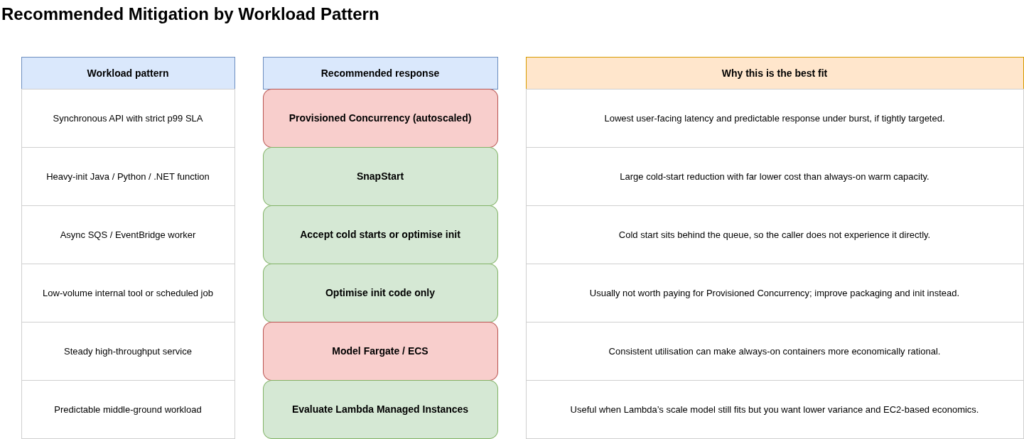
Stage 1: Is this function actually cold-starting? Pull Init Duration from CloudWatch REPORT log lines or the InitDuration metric. If Init Duration is consistently zero or absent, the function is always warm and mitigation is unnecessary. If Init Duration appears on fewer than 1% of invocations and the absolute duration is under 500ms, this is normal Lambda behaviour and likely requires no intervention. A consistent cold-start rate above 5% of invocations, or Init Duration above 1 second, warrants investigation.
Stage 2: Is the cold start user-facing? Map the invocation pattern: synchronous (API Gateway, function URL, direct synchronous invocation) or asynchronous (SQS, EventBridge, SNS, async Lambda invocation). If asynchronous, cold start latency is absorbed by the queue and does not reach the caller on the synchronous path. Do nothing for async functions unless the downstream processing SLA is strict enough that cold start duration materially affects end-to-end latency or backlog recovery. If synchronous, continue to Stage 3.
Stage 3: What is the p99 latency requirement? If the function’s p99 SLA tolerance is above 500ms and current cold start duration is below that threshold, no mitigation is required. If cold starts are causing SLA breaches or risk breaching FCA/PRA operational resilience impact tolerances, continue to Stage 4. For teams managing impact tolerances under PS21/3 (SYSC 15A), the relevant test is whether a cold-start spike during a burst scenario would breach the maximum tolerable disruption duration for the associated important business service.
Stage 4: Optimise the init phase first. Before reaching for Provisioned Concurrency or SnapStart, optimise the init code itself: lazy-load dependencies not needed on every invocation, move heavy initialisation into handler logic where it can be skipped on warm starts, right-size memory (CPU scales with memory allocation, so increasing memory from 512MB to 1024MB typically halves init duration), and prefer ARM/Graviton (approximately 20% cheaper compute at the same CPU allocation). Our spot instance architecture guide covers the broader right-sizing discipline that applies to Lambda memory allocation decisions. After init optimisation, reassess whether the remaining cold start duration falls within the acceptable range.
Stage 5: Choose the mitigation mechanism. If the runtime is Java 11+, Python 3.12+, or .NET 8+ and init duration is above ~500ms, enable SnapStart. It is free or low-cost, achieves sub-second restoration, and is the right default for heavy-init functions on eligible runtimes. If SnapStart is unavailable (unsupported runtime, container image, or a runtime/architecture combination not yet supported) or if the p99 requirement is below ~100ms even post-restoration, apply Provisioned Concurrency surgically to that specific function, with auto-scaling at 60-70% utilisation target and a hard floor of zero during off-peak hours if traffic allows. If traffic is sustained and predictable enough that always-on capacity would be highly utilised, or the function approaches 15-minute execution limits, evaluate moving to Fargate/ECS or Lambda Managed Instances using the AWS Pricing Calculator with the actual workload profile.
Stage 6: Apply governance for regulated workloads. FCA/PRA-regulated firms should map Lambda-backed synchronous functions to important business services, document the cold start mitigation strategy in the operational resilience self-assessment, and scenario-test burst behaviour including AZ evacuation events. The warm-up ping approach (EventBridge rules calling the function on a schedule) should be noted in assessments but not relied upon as a primary mitigation: it keeps only one environment warm per ping, does not handle concurrent scale-up, and does not survive AZ rebalancing.
Implementation Roadmap
Phase 1: Audit and Baseline (Months 1-3)
The immediate priority is instrumentation, not mitigation. Enable Lambda Insights across the function estate if not already active, it surfaces Init Duration, memory utilisation, and concurrency metrics without requiring code changes. Extract the Init Duration distribution for every synchronous, user-facing function; classify each as cold-start-impacted (Init Duration over 500ms on more than 1% of invocations) or acceptable. This audit typically reveals that cold start mitigation is genuinely needed for 10-20% of functions in a mature estate, not the majority.
For each impacted function, profile init code to identify the largest contributors: which SDK clients are being initialised at global scope, what configuration is being loaded, whether database connections are being established before the handler runs. Document the current p99 latency against the business SLA or impact tolerance. Establish baseline Provisioned Concurrency spend if currently in use, and calculate whether that spend would be justified by a pure business-impact assessment or whether it has grown by inertia. Our AWS RDS vs Aurora decision guide covers relevant patterns for connection management in Lambda contexts where RDS Proxy or connection pooling are relevant to the init cost.
Phase 2: Optimise and Migrate (Months 4-9)
Execute init code optimisation across the impacted function set: lazy-load dependencies, right-size memory, move to ARM/Graviton, trim deployment package size. Re-measure after each change. Enable SnapStart on all eligible Java, Python, and .NET functions with Init Duration above 500ms, implement the required runtime hooks for uniqueness handling, and validate in staging before production promotion. Expect a 4-10x reduction in cold start duration for typical heavy-init Java functions, bringing them from seconds to hundreds of milliseconds.
Review Provisioned Concurrency configuration across the estate. Remove it from any function now eligible for SnapStart. Remove it from async functions where it was applied by default. Implement auto-scaling with utilisation-based targets for functions where PC remains justified. Monitor ProvisionedConcurrencySpilloverInvocations and ProvisionedConcurrencyUtilization weekly for the first two months. Expect this phase to reduce Provisioned Concurrency spend by 40-70% for most enterprise estates where it was applied broadly rather than surgically.
Phase 3: Govern and Evolve (Months 10-18)
Establish a cold start review as part of the standard Lambda function review process: any new synchronous function with init duration above 500ms requires either SnapStart enablement or a documented justification for Provisioned Concurrency before production deployment. Add Lambda Init Duration to the FinOps dashboard alongside standard cost metrics, the August 2025 billing change makes this a cost control item, not just a performance metric.
For FCA/PRA-regulated firms, integrate Lambda cold start behaviour into the operational resilience scenario testing programme. The specific scenario to test is a traffic spike (two to five times normal volume) causing concurrent scale-out across multiple AZs, with timing measurements of p99 latency during the scaling event. Document the mitigation strategy, the tested behaviour, and the conclusion in the board-approved self-assessment.
Evaluate Lambda Managed Instances for functions that have grown toward the Fargate crossover threshold without quite reaching it: sustained moderate throughput with durations in the 1-5 second range and acceptable but not ideal cold start frequency. Lambda Managed Instances’ multi-concurrency model (multiple requests handled per environment) and EC2-based pricing with Savings Plan eligibility may change the economics meaningfully for that profile. The feature is relatively new as of mid-2026 and warrants a proof-of-concept before broad adoption.
The Emerging Compute Picture
Two developments in the 2025-2026 period are reshaping the Lambda cold start conversation in ways that will become more significant over the next two to three years.
Lambda Managed Instances, announced at re:Invent 2025, introduces a model where Lambda functions run on EC2 instances in the customer account, with AWS managing the runtime, patching, and scaling. Multi-concurrency (multiple concurrent requests per instance) reduces cold start frequency by amortising environment initialisation across more traffic. EC2-based pricing with Savings Plan and Reserved Instance eligibility brings the cost model closer to Fargate for predictable workloads. The management fee is a 15% premium on the underlying EC2 on-demand instance price; note that Savings Plans and Reserved Instance discounts apply to the EC2 compute component but not to the management fee itself. For workloads currently sitting uncomfortably between Lambda’s event-driven model and Fargate’s container model, Lambda Managed Instances may prove to be the right default by 2027.
Durable Functions, also introduced at re:Invent 2025, allows multi-step workflows with checkpointing and waits measured in hours or days to be written in Lambda function code rather than Step Functions state machine definitions. This addresses one of the historical reasons to leave Lambda for longer-running orchestration: the 15-minute execution limit. As Durable Functions matures, more workloads currently running on ECS for duration reasons will have a credible Lambda path, moving them into the event-driven cost model and making the cold start decision framework above relevant to a larger proportion of the compute estate.
AI inference workloads are the most active area of Lambda optimisation as of mid-2026. Response streaming combined with Lambda’s scale-to-zero economics makes it attractive for intermittent inference endpoints. The cold start challenge here is significant (model loading during init can take 5-30 seconds), and the current best practice is either SnapStart (where the model is loaded into the snapshot and restored rather than re-loaded on each cold start) or a dedicated inference endpoint via SageMaker or Bedrock for high-frequency inference where scale-to-zero does not apply. The model-in-snapshot pattern for SnapStart is early-stage but promising.
Strategic Recommendations
The single most impactful change most enterprise Lambda estates can make is to audit their Provisioned Concurrency spend and remove it from async functions, from functions where SnapStart would achieve equivalent latency at lower cost, and from functions with low enough traffic that the idle premium is disproportionate to the cold start impact. The typical outcome of this audit is a 40-60% reduction in Provisioned Concurrency spend with no perceptible change in user-facing latency.
For Java shops specifically, enabling SnapStart on synchronous, heavy-init functions should be treated as a default configuration, not an advanced option. The mechanism has been GA since 2022 for Java, is free, and typically achieves a 4-10x reduction in cold start duration without ongoing cost. The runtime hook requirement for uniqueness handling is real but modest in engineering effort, a few hours for a typical function, not a multi-sprint initiative.
The exit ramp to Fargate/ECS is the right answer for a specific and identifiable set of workloads: those with consistent high throughput, sub-10ms p99 requirements under burst, durations approaching 15 minutes, or persistent connection requirements. Trying to make Lambda work for these workloads via aggressive Provisioned Concurrency is technically possible and economically wasteful. Lambda is not the right compute primitive for everything, and recognising the boundary is a sign of architectural maturity.
For regulated firms, the FCA/PRA operational resilience framework provides a useful discipline: if a Lambda-backed service cannot demonstrate that it operates within its impact tolerance during a simulated burst scenario, the mitigation is insufficient regardless of what the CloudWatch averages show. Test under burst. Document the result. Fix what breaks.
Useful Links
- AWS Lambda Pricing (official)
- AWS Lambda SnapStart documentation
- The invisible engineering behind Lambda’s network (Werner Vogels, April 2026)
- How Smartsheet reduced latency and optimised costs in their serverless architecture (AWS Architecture Blog)
- Smartsheet Lambda case study
- WirelessCar Lambda SnapStart case study
- BMW Connected Drive case study
- AWS Lambda operating performance optimisation (AWS Compute Blog)
- FCA PS21/3 Building operational resilience