

There is a diagram that appears in AWS architecture reviews so reliably it has become invisible: producer publishes to an SNS topic, which fans out to a set of SQS queues, each consumed by a downstream service. It is clean. It is defensible. It is also, in a meaningful number of cases, the wrong shape for the problem. SNS fan-out has become AWS-flavoured muscle memory, chosen not because the architecture demands it but because the diagram looks correct. At low scale this is harmless. At enterprise scale, the accumulated assumptions behind that diagram become load-bearing, and the ones that fail tend to fail quietly.
The Decoupling Argument Does Not Hold Up Under Inspection
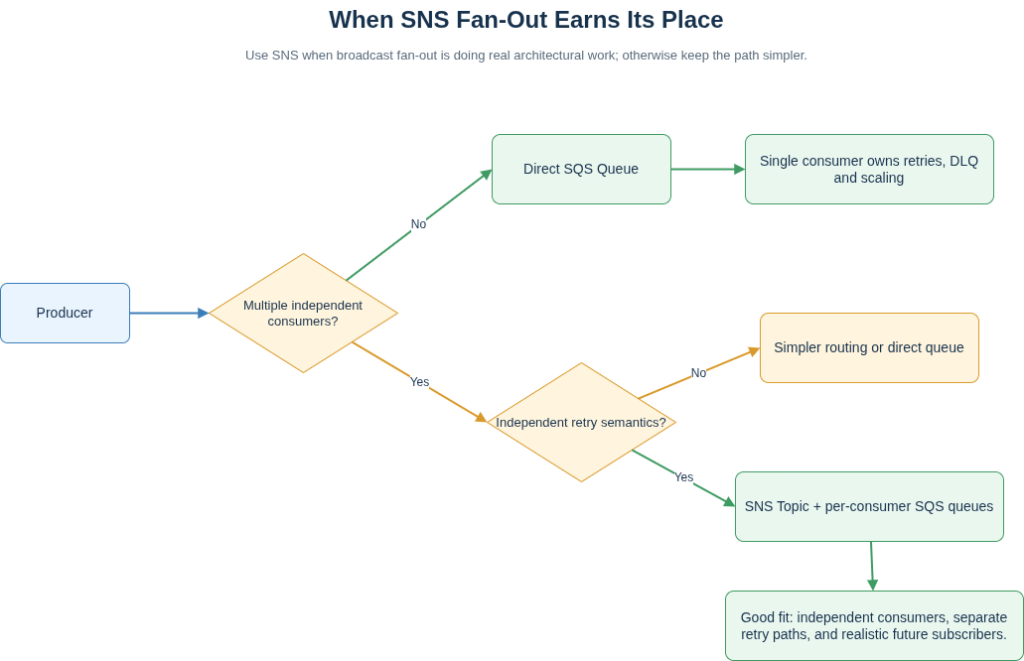
The standard justification for SNS is that it decouples the publisher from its consumers. The publisher does not need to know who is listening; new subscribers can be added without touching the producer. This is true, and it is also almost never the reason teams actually need. Most enterprise event streams have a small, well-known, slowly-changing set of consumers: inventory, payments, audit, analytics, two or three services at most. The argument that you can add subscribers later without touching the publisher is invoked frequently and exercised rarely. When you audit your SNS topics in a mature account, a substantial portion will have one or two subscribers, both written by the same team, deployed on the same cadence. The fan-out layer is doing no architectural work. It is adding a routing hop, an extra IAM surface, and an extra place to lose messages.
The useful question before reaching for SNS is not “do I want decoupling?” but “do I have at least two independent consumers that need this event, with independent retry semantics, and a realistic expectation of more being added?” If the answer is no, writing directly to an SQS queue per consumer is almost always the cleaner, more observable design.
SNS Has No Central Dead-Letter Queue
In SQS, the dead-letter queue is attached to the source queue via a redrive policy. You know what failed, when it failed, and how many times it was attempted. There is one place to look. In SNS, dead-letter queues are configured per subscription, not per topic. If a subscription has no DLQ configured, client-side delivery failures (an endpoint permission error, a stale queue policy, a misconfigured Lambda resource policy) are silently discarded. AWS does not retry these. The message is gone.
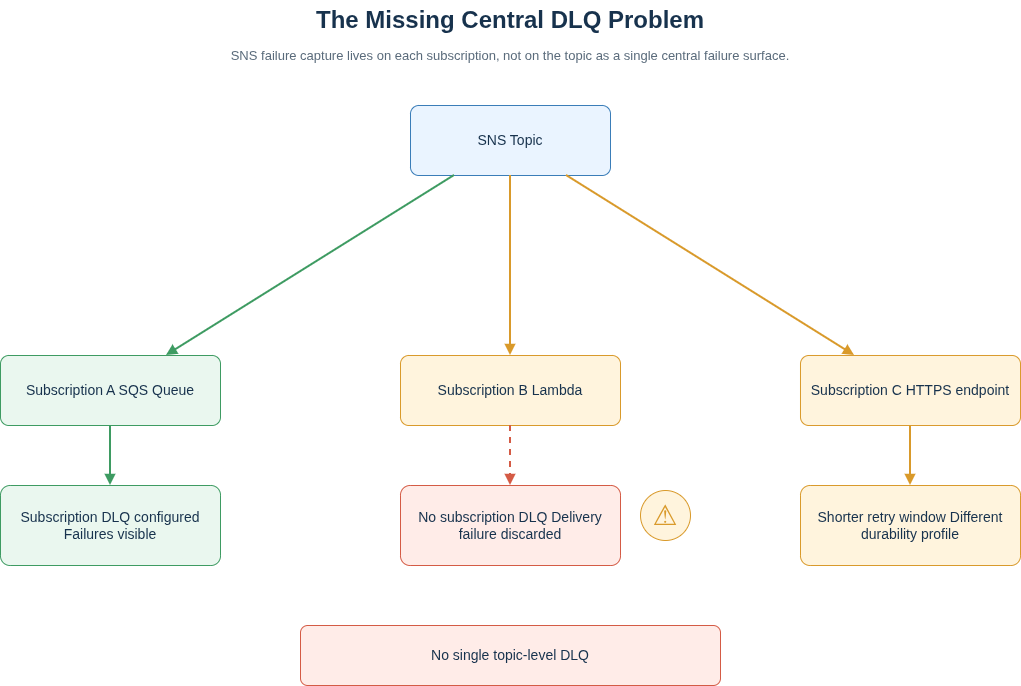
Retry behaviour also varies by protocol in ways that are not obvious from the console. For AWS-managed endpoints such as SQS and Lambda, SNS will retry up to 100,015 times over 23 days. For HTTP and HTTPS endpoints, the default backoff policy caps the total retry window at 3,600 seconds. For email and SMS, it is 50 attempts over six hours. A single SNS topic with mixed subscriber types has multiple different durability profiles running simultaneously, none of them visible from the topic itself. The failure pattern that follows: a queue policy change removes SNS’s permission to deliver to an SQS subscriber, the subscription has no DLQ, and the alert arrives from a business metric anomaly a week later rather than from anything the messaging layer said. This is a pattern teams encounter repeatedly, because there is no centralised failure surface to alert on. The AWS CloudWatch custom alarms guide covers building metric-based alerting across services, but no alarm configuration compensates for a dead-letter queue that was never added to the subscription in the first place.
The SQS Primitives That Matter at Scale Are the Ones Teams Skip
Pull-based consumption is SQS’s most important architectural property and the one most frequently overlooked when teams move past it to SNS fan-out. SNS pushes events regardless of downstream health. A slow consumer behind an SNS-to-Lambda or SNS-to-HTTP subscription receives the same inbound rate whether it can keep up or not, and the retry policy amplifies load during an outage rather than respecting consumer capacity. SQS consumers pull at their own rate. When the downstream is under pressure (a saturated RDS instance, an API rate limit, an inference endpoint with finite concurrency) the queue absorbs the backpressure naturally. The AWS Lambda performance post covers concurrency control in detail, but the structural point is simpler: the queue gives the consumer control over its own consumption rate, and SNS does not.
FIFO queues are similarly under-used, often dismissed because of the 300 transactions-per-second-per-queue figure. In practice, FIFO queues partitioned by MessageGroupId support up to 3,000 messages per second with batching in high-throughput mode. More importantly, FIFO delivers per-entity ordering, per-user or per-account or per-order, which is what teams actually need when they say they need ordering. Global ordering across all messages is a different requirement, and rarely the correct one.
Fan-Out Complexity Grows Non-Linearly
SNS subscription filter policies look powerful on first contact and become a maintenance problem at scale. Each policy is capped at five attribute keys and a combination complexity of 150. The account-level limit was raised to 10,000 policies in late 2022, but per-topic complexity constraints remain. Multi-tenant SaaS designs that route per-customer events using filter policies hit these ceilings on a predictable growth curve, and the migration from one topic with per-customer filters to one topic per customer is not a small refactor. It happens under time pressure, after the limit has already been breached, and it is entirely foreseeable from the design stage.
SNS FIFO is also more constrained than the name suggests. It cannot deliver to HTTP, email, SMS, or mobile push endpoints. It supports a maximum of 100 subscriptions per topic. Ordering is guaranteed within each subscription’s delivery stream, not across all subscribers simultaneously: two subscribers to the same SNS FIFO topic may process events in different orders relative to each other. Teams that build reconciliation logic on the assumption that all subscribers see events in the same sequence are building on a property that does not exist.
The Pattern Is Correct When the Question Is Correct
SNS fan-out with per-consumer SQS queues is a well-suited architecture when the conditions actually apply: multiple independent consumers with distinct retry semantics, a real expectation that new subscribers will be added without publisher changes, and a broadcast model where all subscribers need every event. When those conditions hold, the pattern earns its place.
When they do not, it adds surface area without adding value. The third option that deserves more consideration than it typically receives is EventBridge. For content-based routing, cross-account fan-out, or any scenario where the routing logic is more specific than “all subscribers get all messages,” EventBridge is better suited than SNS and has been for several years. Many teams still reach for SNS because they learned AWS before EventBridge reached maturity, and the habit has not updated with the toolset.
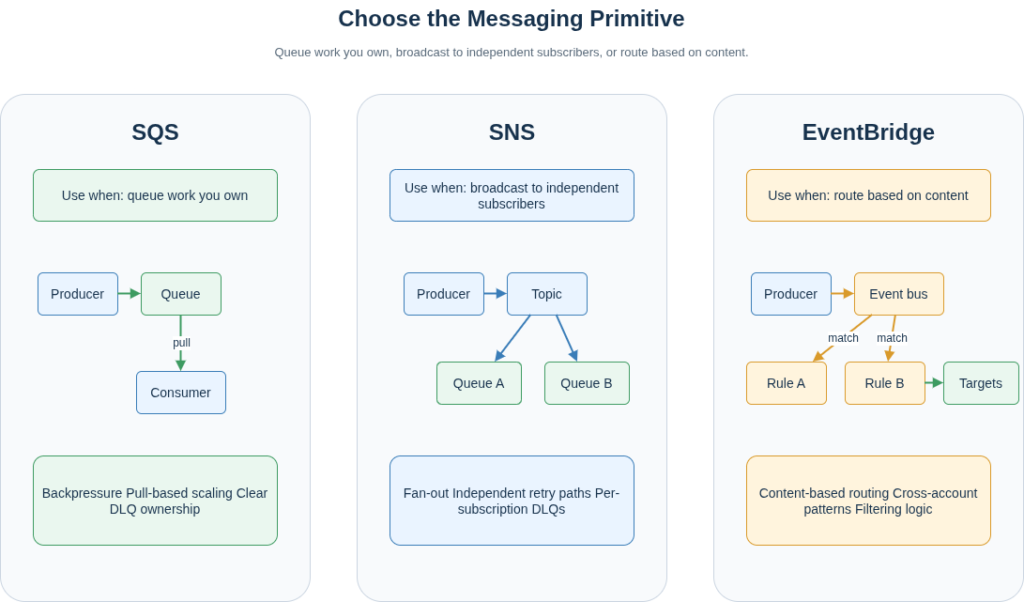
Three primitives: queue work you own, broadcast to independent subscribers, route based on content. Before the next SNS topic appears in a design review, it is worth asking which of those three the architecture actually requires.
Useful Links
- AWS Decision Guide: Amazon SQS, Amazon SNS, or Amazon EventBridge?
- Amazon SNS dead-letter queues (AWS Documentation)
- Amazon SNS message delivery retries (AWS Documentation)
- SNS subscription filter policies (AWS Documentation)
- SNS filter policy constraints (AWS Documentation)
- SQS high-throughput FIFO queues (AWS Documentation)
- Amazon SNS FIFO topic message ordering (AWS Documentation)
- AWS What’s New: SNS filter policy quota raised to 10,000
- How to Design Around Serverless Service Limits (Ready, Set, Cloud)
- Designing durable serverless apps with DLQs (AWS Compute Blog)






