

Every cloud engineer breaks something in production. If you haven’t yet, you will. The engineers who reach senior roles earning £90,000-£130,000 are not the ones who avoided incidents throughout their early career, they’re the ones who handled the 48 hours that followed well. Research from Google’s Site Reliability Engineering team found that organisations with the strongest incident learning cultures also had the fastest individual engineer development cycles. The difference between an engineer who grows through a production mistake and one who is quietly defined by it is almost never about the technical fix. It’s about everything else.
Most early career engineers get the instinctive part right: fix the problem as fast as possible. What they get wrong is everything that happens before, during, and after the fix. They go quiet when they should communicate. They work alone when they should involve others. They avoid the post-mortem when they should be leading parts of it. And they walk away from the experience having absorbed the shame without extracting the value. That pattern, repeated across the first two or three incidents in a cloud career, is one of the most consistent reasons engineers stall below £60,000 when their technical ability would carry them well past it.
The 48-hour window after a production mistake is one of the most career-defining periods of your first five years. This post gives you a clear framework for navigating it, illustrated with three scenarios you might recognise, and explains how to turn what feels like a setback into evidence of exactly the kind of engineering maturity that gets people promoted.
The Instinct That Works Against You
When something breaks in production and you know you caused it, the instinct is to go invisible. Fix it quietly, say as little as possible, and hope that if you restore service quickly enough, no one will ask too many questions. This instinct is understandable and it is almost always wrong.
Silence during an active incident is not read as competence by the senior engineers around you. It is read as confusion. Working alone without communicating is not read as independence. It is read as poor judgement about when to involve others. Finishing the fix without contributing to the post-mortem is not read as humility. It is read as a missed opportunity that senior engineers make a mental note of.
The engineers who are viewed well after incidents are not the ones who caused the fewest. They are the ones who responded clearly, communicated honestly, and contributed meaningfully to making the system more resilient. That reputation compounds over time. It is one of the fastest ways to earn the kind of visibility that drives progression from junior (£40,000-£60,000) to mid-level (£60,000-£90,000) in 18 months rather than four years. And it starts in the first hour.
The First Hour: Communication Before the Fix
The most important thing you do in the first hour is not the technical remediation. It’s the communication.
The moment you realise something has gone wrong, your first action should be to say so. Not to your team in a panic, but clearly and specifically. In Slack or Teams, in the relevant channel, with the information you have right now: what happened, when you noticed it, and what you are doing about it. You do not need the full picture. You do not need to know the root cause. What you need to do is establish that you are aware of the problem and actively working on it.
This single action changes how the incident is perceived. It moves you from “engineer who caused a problem” to “engineer who is managing a situation.” Those are very different things in the eyes of the people around you.
If your organisation uses an on-call rotation or an incident response process, follow it. Declare the incident at the appropriate severity level. Page the on-call engineer if the situation warrants it, even if that feels uncomfortable. Bringing someone in early is not an admission of failure. It is sound judgement, and senior engineers know the difference immediately. Keep communicating throughout. Short, factual updates every 15 to 30 minutes are enough. “Service partially restored, investigating root cause” is far better than silence. It keeps stakeholders informed and gives your senior colleagues confidence that someone is in control.
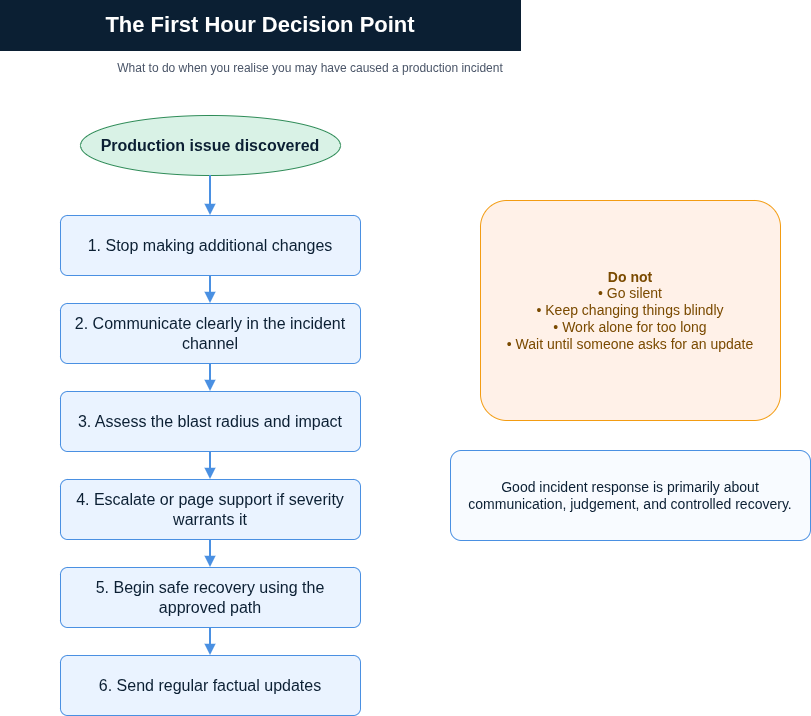
Three Scenarios: What This Looks Like in Practice
Scenario 1: The Terraform Apply That Deleted Something
You ran a terraform apply in the wrong environment, or against a state file you didn’t realise was shared. A database, a storage bucket, a set of VMs – gone. Your stomach drops.
First, stop. Do not run another apply to try to fix it. Do not make any further infrastructure changes until you understand the blast radius. One of the most common ways engineers compound a Terraform incident is by making additional changes before they understand what was affected, turning a recoverable situation into a significantly worse one.
Message your team immediately. State what happened factually: “I ran a terraform apply in the prod environment and it destroyed the following resources. I’m assessing the impact now and working on recovery. Bringing in [name] to help.” If your organisation has backups or snapshots enabled, identify them now. That becomes your recovery path, and surfacing it quickly demonstrates the kind of operational awareness that matters at mid-level and beyond.
The engineering lesson here has a direct parallel in career development. As explored in From Certification to Expertise: Building Practical Skills, the engineers who navigate recovery paths faster than others do so because they have spent time understanding the infrastructure below the surface. Incidents accelerate that understanding in ways that structured study cannot replicate.
Scenario 2: The Misconfigured IAM Policy That Locked People Out
You pushed a new IAM policy, or modified an existing one, and now a team of colleagues cannot access the systems they need to work. The support tickets are arriving. Your Slack notifications are active.
The first instinct is to roll back the policy immediately. That is often the right call, but before you do, check whether the rollback itself is safe. Can you make the change? Are your own permissions intact? If you locked yourself out as well, you need an IAM administrator to intervene, and you need to tell them that now rather than spending 20 minutes discovering you cannot resolve it independently.
What makes this scenario specifically instructive for early career engineers is that IAM mistakes feel uniquely embarrassing because they affect other people visibly and immediately. The natural response is apology followed by silence. What actually serves you better is apology followed by clear communication about what happened, what you are doing, and when you expect it to be resolved. People are generally more forgiving than engineers expect, particularly when they can see that someone is handling it professionally. The AWS IAM Policy Simulator is worth bookmarking now, before you need it. Simulating policy effects before applying them to production removes an entire category of this kind of incident.
Scenario 3: The Deployment That Caused a Cost Spike
You pushed a change, an autoscaling configuration or a resource size adjustment or a misconfigured service, and the following morning a cost alert fires with a number that makes you feel sick. The spend is real and the cause is your change.
This scenario plays out over a longer timeline than the first two. The immediate action is to identify the cause and roll it back or correct the configuration. The second action is to quantify the impact: how long was it running, what is the estimated spend, what is the current trajectory if left uncorrected. The third action is to communicate this to whoever owns your cloud budget, factually and without waiting to be asked.
Cost incidents are career-defining for a different reason than outages. Outages have obvious urgency. Cost spikes can sit quietly if no one speaks up. Proactively surfacing a cost problem you caused, before anyone asks, is the kind of behaviour that gets noticed and remembered. It signals financial awareness and accountability that most junior engineers do not demonstrate until much later in their careers. The progression paths outlined in From Cloud Support to Solutions Architect: £240K Roadmap are consistent on this point: financial accountability is one of the behaviours that reliably separates engineers who advance quickly from those who plateau.

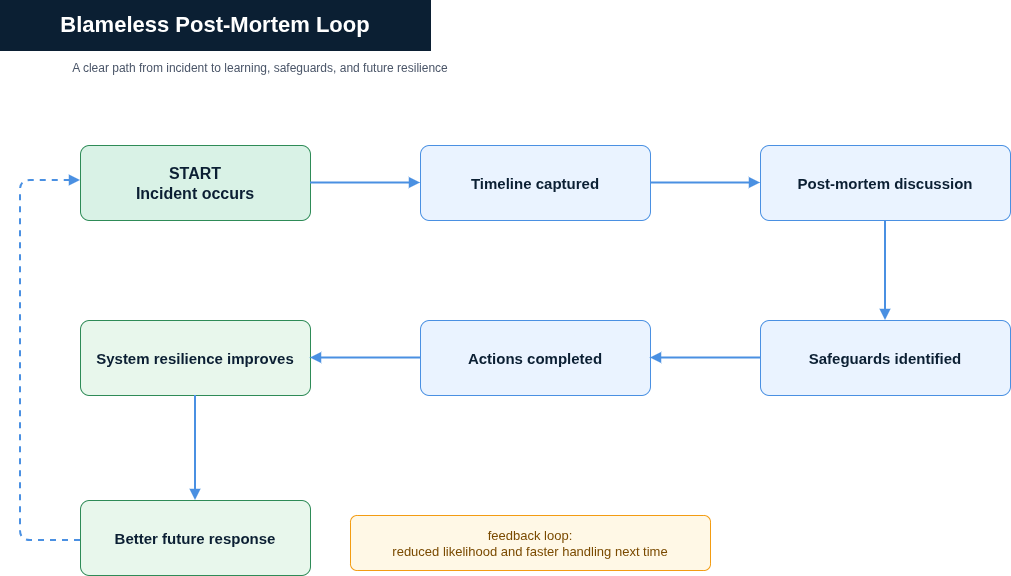
The Blameless Post-Mortem: Your Career Opportunity
Most organisations that run cloud infrastructure at scale will conduct a post-mortem after a significant incident. If yours does, your participation is not optional from a career perspective, even if it feels optional from an organisational one.
A blameless post-mortem is not a tribunal. Its purpose is to understand how the system allowed the incident to occur and to identify improvements that reduce the likelihood of recurrence. In a well-run post-mortem, the question is never “who made the mistake?” It is “what in our process, tooling, or design made this mistake possible?” Your role is to contribute the most accurate account of what happened from your perspective, not a sanitised version, not a version that minimises your involvement, but the actual sequence of events as you experienced it.
Come prepared. Write down your timeline before the meeting: what you were doing, what changed, when you noticed something was wrong, what you tried. This helps the team build an accurate picture, and it demonstrates that you took the process seriously. If you can identify a process gap or a missing safeguard that would have prevented the incident, raise it. “What if we had a pre-apply plan review step for production changes?” is the kind of suggestion that gets you noticed in a post-mortem as someone with systems thinking, not just someone who caused a problem.
The engineers who advance furthest in cloud careers share one quality that becomes apparent in high-pressure situations: they perform well when the situation is uncomfortable. The behaviours that separate £90,000 engineers from £150,000 principals, explored in Under Pressure: The High-Stakes Performance Skill That Separates £90K Engineers from £150K+ Principals, are visible in post-mortems long before they show up in major incidents. A blameless post-mortem is an uncomfortable setting. Preparing for it and contributing clearly is how you demonstrate those qualities early.
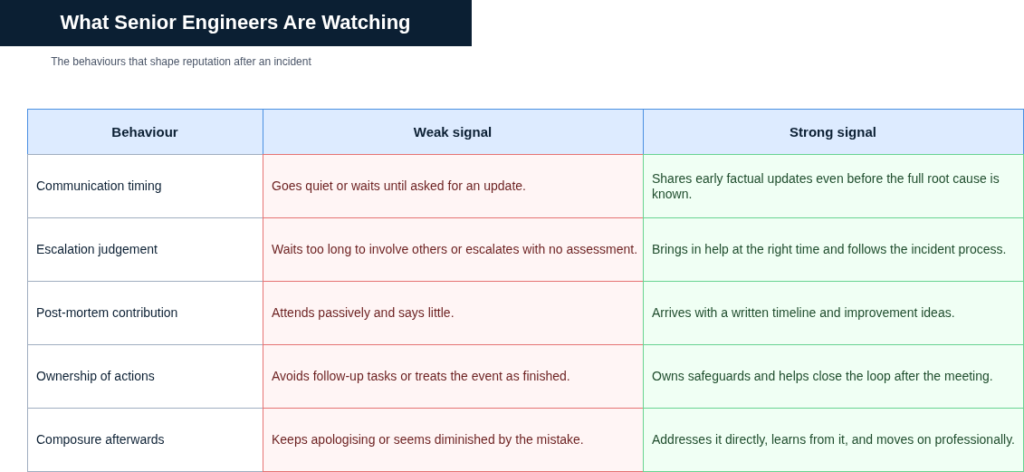
What Senior Engineers Are Watching
Senior engineers are not primarily evaluating you on whether you caused the incident. They are evaluating you on how you handled it. The specific behaviours that form their assessment are more precise than most junior engineers realise.
They are watching whether you communicated early or late. Early communication, even when the picture is incomplete, signals maturity. Late communication, or no communication until asked, suggests that your instinct under pressure is to hide rather than engage. They are watching whether you escalated appropriately. Escalation is a skill. Escalating too late, after the situation has worsened, is a judgement failure. Escalating too early on a problem you could have resolved independently in a few minutes is a different kind of judgement failure. Learning where the line is takes experience, and incidents are how you learn it.
They are watching whether you contributed to the post-mortem or attended it passively. A junior engineer who arrives with a written timeline and raises a process improvement is memorable. A junior engineer who attends quietly and says nothing contributes nothing to the team’s resilience.
They are watching how you talk about it afterwards. Engineers who handle incidents well do not reference the mistake repeatedly in self-deprecating ways, nor do they pretend it did not happen. They address it directly when relevant and move on, demonstrating that they have processed the experience without being diminished by it. That composure, observed consistently, is one of the clearest signals that an engineer is ready for increased responsibility.
Turning the Incident Into Career Evidence
Incidents are not just things to survive. They are some of the richest sources of operational knowledge you will encounter in your first five years. The engineer who treats a production mistake as a learning event, extracts the technical understanding from it, and makes a meaningful contribution to the post-mortem comes out of the experience materially stronger.
In practical terms, this means documenting what you learned. Not publicly, and not in a performative way. A private note on what you understood about the system after the incident, what safeguards you would now recommend, and what you would do differently is enough. Over time, these notes become the foundation of the kind of operational knowledge that distinguishes senior engineers from those who have accumulated years without accumulating depth.
It also means updating your working knowledge of your organisation’s infrastructure in ways that matter. If you caused a Terraform incident because you didn’t understand which workspaces mapped to which environments, you now understand it. Document that mapping. If you caused an IAM issue because you didn’t fully understand the inheritance model in your organisation’s account structure, learn it properly now. Incidents are accelerated education, and the engineers who treat them that way close the gap between junior and mid-level faster than those who treat them purely as things to recover from.
By the time you reach mid-level roles at £60,000-£90,000, the engineers who advance fastest are those who can speak specifically about operational experiences and what they took from them. The incident you are navigating right now is one of those experiences. How much you extract from it is your choice.
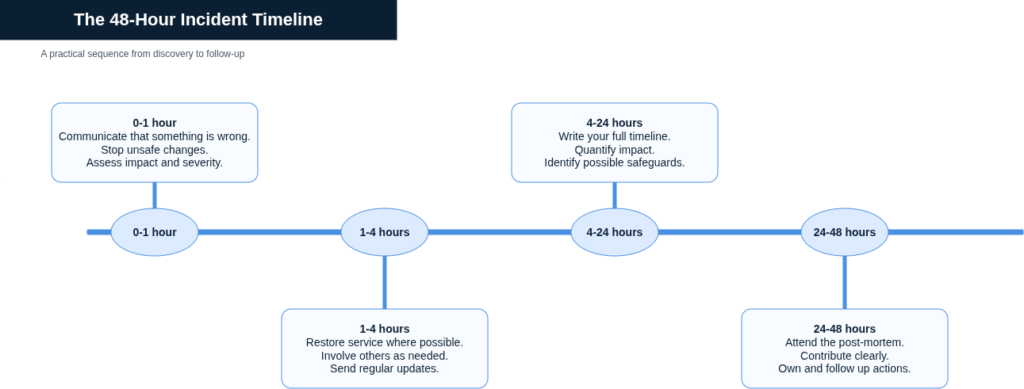
The 48-Hour Timeline
The practical sequence looks like this. In the first hour, communicate that something is wrong and that you are working on it. Involve others if the severity warrants it. Do not make additional changes until you understand the blast radius. In the first four hours, restore service where possible, communicate progress regularly, and begin building your timeline of what happened.
In the first 24 hours, write your full account of the incident while it is fresh. Identify any safeguards that would have prevented it and note them for the post-mortem. If the post-mortem is scheduled, prepare your contribution. In the 48 hours following, attend the post-mortem, contribute clearly, and raise the safeguard improvements you identified. Follow up on any actions you own from the discussion. Then get back to work.
The engineers who reach £90,000 and beyond are not the ones who never made mistakes in their early career. They are the ones who handled mistakes professionally and consistently, building a reputation that compounds over years. That process begins in the first hour after something goes wrong.
Next Steps You Can Take This Week
- If you have recently had an incident, write your private timeline now while memory is fresh. Be honest about the sequence of events, including what you tried that didn’t work.
- Review your organisation’s post-mortem process. If your team doesn’t run post-mortems, raise it with your manager as something worth introducing.
- Check whether your current environments have basic safeguards: pre-apply plan reviews for Terraform changes, IAM policy simulation before applying permission changes, and cost alerts with realistic thresholds.
- Read one post-mortem from a major engineering organisation. Google and Atlassian publish theirs publicly. Understanding what a high-quality blameless analysis looks like before you need to write one is worthwhile.
- If there is an engineer on your team who handles high-pressure situations well, watch how they communicate during incidents. That behaviour is learned, not inherited.
Useful Links
- Google SRE Book: Postmortem Culture – The canonical reference on blameless post-mortems and learning from failure in production systems
- Atlassian Incident Management Handbook – Practical incident response guidance used by engineering teams at scale
- PagerDuty Incident Response Guide – Open-source incident response documentation with templates and communication frameworks
- Terraform Workspace Documentation – Official guidance on workspace organisation to reduce environment-level risk
- AWS IAM Policy Simulator – Simulate IAM policy effects before applying them to production environments
- Azure Policy Compliance – Azure-specific guidance on policy testing and compliance validation
- IT Jobs Watch – Cloud Engineer Salaries – Current UK salary benchmarks for cloud engineering roles at all experience levels






