S3 Intelligent-Tiering has acquired a reputation as a safe default: enable it across your buckets, pay a small per-object monitoring charge, and let AWS automatically move cold data to cheaper storage tiers. The pitch is appealing, especially at scale, when access patterns are difficult to predict. The reality is more conditional. For the right workload, the cost reduction is real and the operational overhead is low. For the wrong workload, you pay the monitoring charge every month without triggering a single tier transition, and your storage bill increases rather than decreases. The distinction matters more than most cost reviews acknowledge, and a significant amount of published advice is based on how S3-IT worked before September 2021, not how it works today.
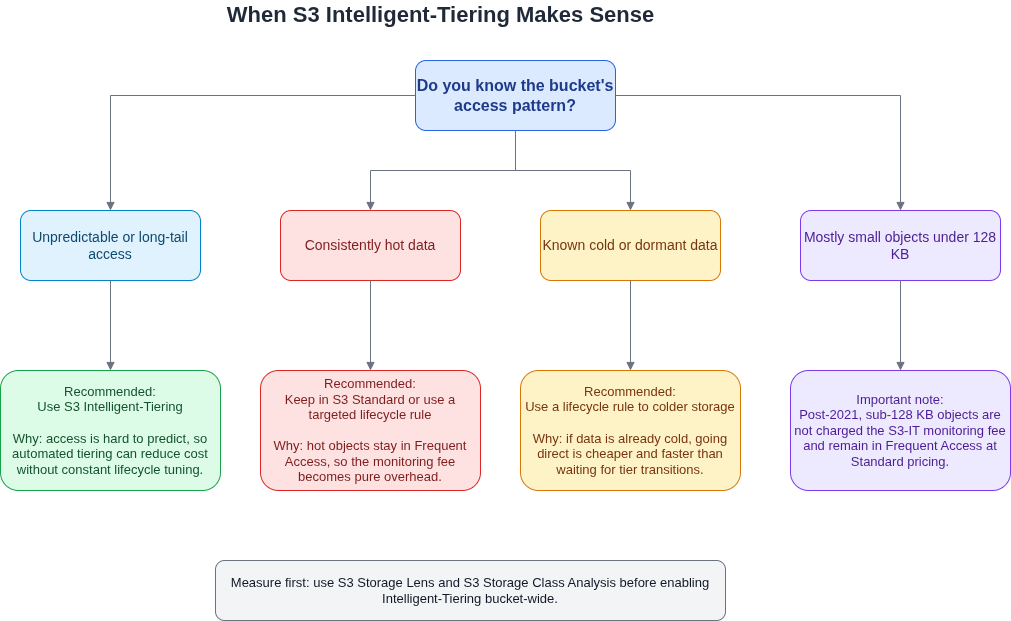
The per-object monitoring and automation charge is $0.0025 per 1,000 objects per month. Written differently: $25 per month per ten million objects, $250 per hundred million, $2,500 per billion. At billion-object scale, the monitoring charge alone reaches $30,000 per year before you count any storage costs. That fee applies to every eligible object in an S3-IT bucket, regardless of whether it ever transitions to a cheaper tier. If your workload is hot (consistently accessed within any given 30-day window), every object stays in the Frequent Access tier, which is priced identically to S3 Standard. Paying Standard storage rates plus the monitoring charge is reliably more expensive than staying on Standard. A 100-million-object bucket where all objects are regularly accessed will cost roughly 11% more in S3-IT than in Standard. That is not a marginal inefficiency; it is a structural one that compounds with object count.
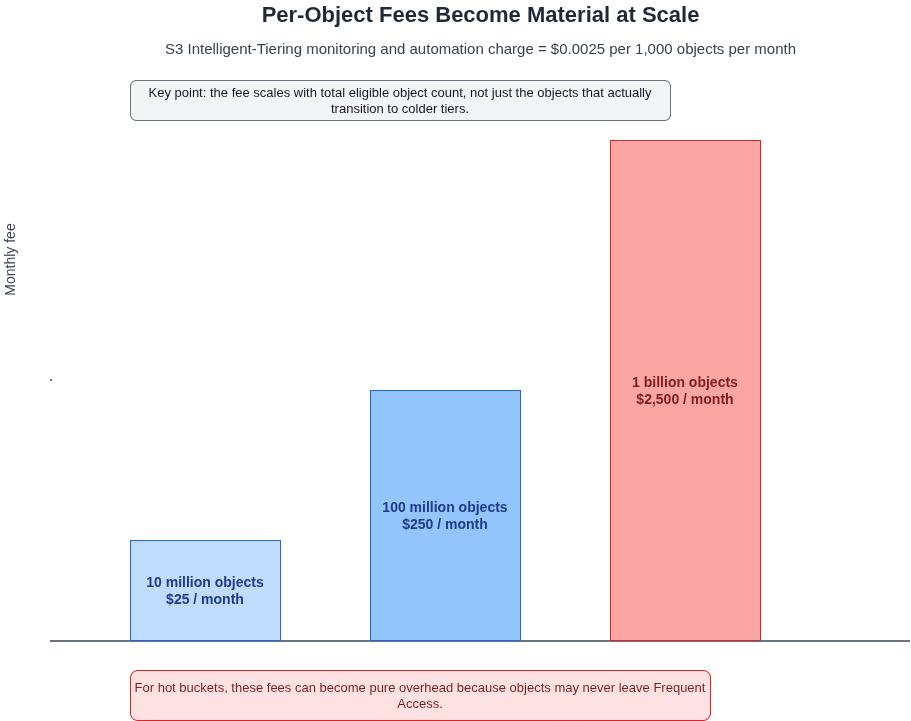
AWS made two substantive changes to S3-IT in September 2021 that resolved some of the concerns in older guidance. Prior to that update, objects smaller than 128 KB were billed the monitoring charge even though they could never tier, making S3-IT a guaranteed cost increase for buckets dominated by small files. AWS removed that behaviour: objects below 128 KB now stay in the Frequent Access tier permanently and are charged at Standard rates with no monitoring overhead. The same update also removed the 30-day minimum storage duration, which had previously meant early deletion incurred a pro-rated penalty. Both changes were meaningful. The problem is that the vast majority of advice warning against S3-IT predates these changes, and practitioners who absorbed that guidance concluded S3-IT should be avoided without ever revisiting the assumption. The failure mode in 2026 is not small objects. It is hot buckets, and those are not the same thing.
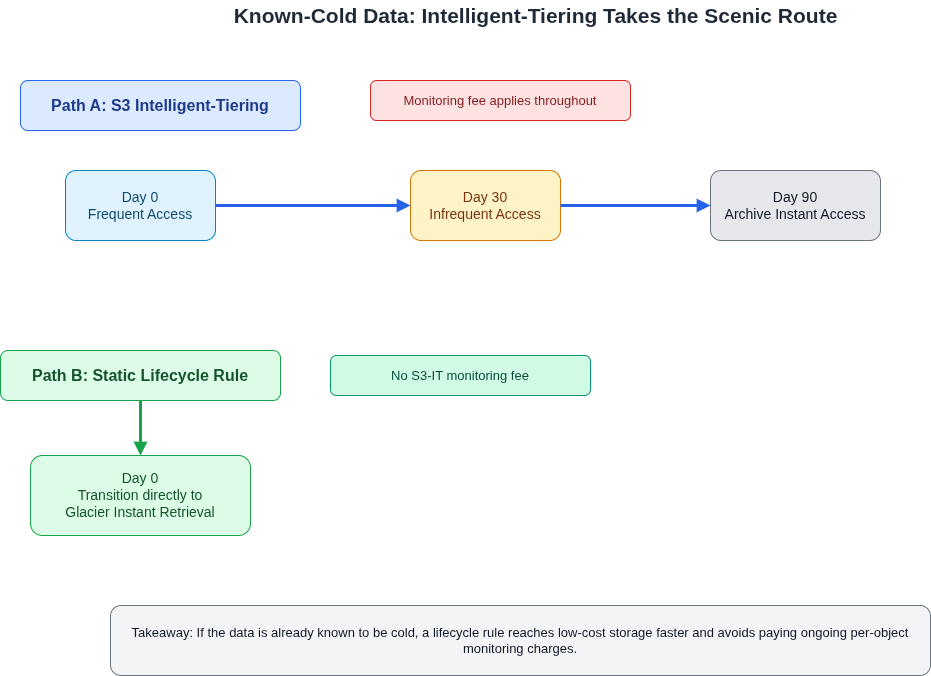
The second scenario where S3-IT reliably costs more than the alternative is less obvious. For data that is already cold, S3-IT is not the shortest path to the cheapest storage. When you enable S3-IT on a bucket of dormant data, every object starts in the Frequent Access tier regardless of how long it has been untouched. After 30 days without an access, it moves to Infrequent Access. Only after another 60 days does it reach the Archive Instant Access tier at $0.004 per GB per month. For data you know to be cold (backup snapshots, compliance archives, support attachments dormant for months), a lifecycle rule transitioning directly to Glacier Instant Retrieval on day one reaches the same storage price with no waiting period and no ongoing monitoring charge. The 90-day detour through Frequent and Infrequent Access, combined with the monitoring fee throughout, means teams with demonstrably cold workloads can spend more in the first quarter of S3-IT enablement than they would have spent staying on Standard.
The discipline that applies to identifying hidden storage waste applies here too: measure before you enable. S3 Storage Lens provides per-bucket metrics including object count, average object size, and storage class distribution. S3 Storage Class Analysis goes further and reports actual access patterns over a configurable observation window, which is the same input S3-IT’s tiering algorithm uses internally. Running either of those before enabling S3-IT on a new bucket takes the guesswork out of the decision. For buckets with unpredictable demand (user-generated content, machine learning feature stores, raw zones in a data lake), the cost reduction is well-documented and the operational overhead is low. For buckets with consistent access patterns, a targeted lifecycle rule is almost always cheaper. Identifying which category your buckets fall into is precisely the kind of work a Well-Architected cost review surfaces when storage is on the agenda, and it should happen before enablement, not after the monitoring charges appear in the cost and usage report.
S3 Intelligent-Tiering is a well-designed service for the workloads it was built to handle. The question worth asking before you enable it is not whether a bucket exists, but whether you know that bucket’s access pattern. For unpredictable, long-tail workloads, it reduces costs without requiring manual lifecycle rule maintenance. For hot buckets with consistent access, it adds cost without adding value. For already-cold data, a static lifecycle rule is cheaper and faster. The monitoring fee scales with your object count rather than just the objects that tier, which means the cost of getting the scope wrong scales with your estate. That is the calculation worth running before the next storage review, and it sits squarely in the cloud unit economics framing that good cost analysis applies across every AWS service: understand the per-object cost of every decision, not just the per-gigabyte headline.
Useful Links
- Amazon S3 Intelligent-Tiering storage class: AWS product page including tier pricing, case studies, and activation guidance
- Amazon S3 pricing: official per-region storage class pricing; verify eu-west-2 rates directly in the console
- How S3 Intelligent-Tiering works: AWS documentation covering tier transitions, monitoring charges, and eligibility rules
- S3 Intelligent-Tiering: improved cost optimisations for short-lived and small objects: the September 2021 AWS blog post announcing the removal of minimum storage duration and the 128 KB monitoring exemption
- S3 Intelligent-Tiering: what it takes to actually break even: Duckbill Group’s break-even modelling; the most rigorous public analysis of S3-IT economics
- Amazon S3 Storage Lens documentation: per-bucket visibility into object counts, sizes, and storage class distribution
- Amazon S3 Storage Class Analysis: access pattern reporting used to inform lifecycle rule and S3-IT decisions