Cloud providers are offering up to 91% off on-demand compute prices, and most engineering teams are leaving that money on the table. Not because they lack awareness (Spot Instances, Azure Spot VMs, and GCP Spot VMs are well-publicised), but because the gap between “enabling Spot” and “designing for Spot” is larger than most organisations anticipate. The average AWS Spot interruption rate has historically been below 5%, which means that for most workloads, well-architected Spot infrastructure will run uninterrupted for weeks. Yet teams regularly deploy Spot capacity without the architectural underpinning to handle the 5% case, discover this in production under load, and either abandon Spot entirely or maintain fragile workarounds that erode the savings they were chasing.
The conventional failure mode is predictable. A team identifies a promising workload, switches the instance type to Spot, watches costs drop, and concludes the migration is complete. Everything holds until a regional capacity event or a weekend maintenance window triggers a wave of evictions. Stateful sessions are dropped. Long-running jobs restart from scratch. The incident gets blamed on Spot rather than on the architecture, and on-demand instances quietly return. The savings disappear, but the lesson that Spot is an architectural commitment, not a configuration setting rarely lands until the next attempt.
This post lays out the engineering framework for doing Spot correctly, covering both greenfield design and brownfield migration. It addresses the cross-provider mechanics that determine what your graceful shutdown logic can actually accomplish, the workload viability criteria that separate genuine Spot candidates from workloads that will cause incidents, and the Kubernetes patterns that most production implementations now rely on. ITV, the UK broadcaster, grew Spot from 9% to 24% of its EKS compute and achieved £150,000 in annual savings. The architecture that made that possible is replicable, but it requires deliberate design decisions before the first eviction, not after.
How Spot Pricing Actually Works Across Three Clouds
Understanding the discount mechanics is a prerequisite for building appropriate cost models and fallback strategies, and the three major providers work differently enough that treating them as equivalent is a mistake.
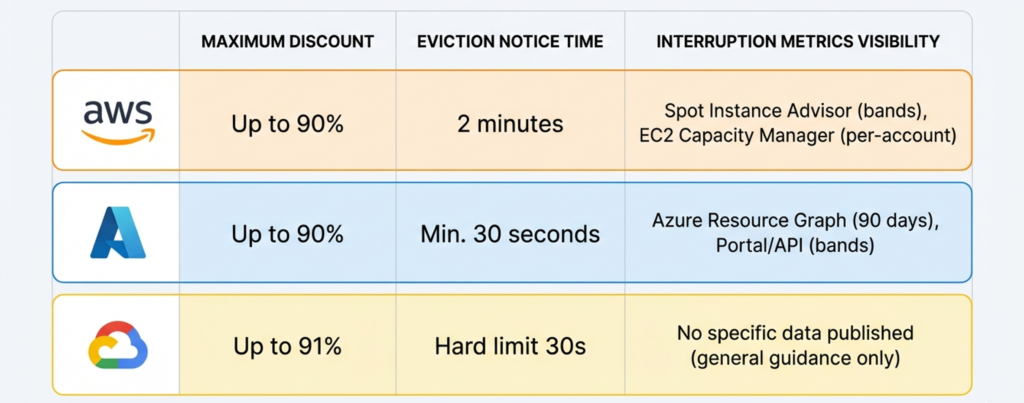
AWS offers up to 90% off on-demand, with typical savings of 70-90% depending on instance family and region. AWS abandoned its auction-based bidding model in 2017; Spot prices now change gradually based on long-term supply trends, updated every five minutes, and are considerably more stable than the original model implied. Users can set a maximum price (which defaults to the on-demand rate if omitted), but AWS explicitly recommends against doing so, since price-based terminations are more frequent and less predictable than capacity-based ones. One critical interaction that teams frequently miss: Savings Plans and Reserved Instances do not apply to Spot usage. They cover the on-demand portion of a mixed fleet only, which means Spot is a complementary strategy to commitment-based discounts rather than a replacement for them. For context on how to structure that combined strategy, the reserved instance decision framework on this blog covers the commitment-versus-flexibility trade-off in detail.
Azure Spot VMs offer up to 90% off pay-as-you-go pricing and introduce a configuration choice that AWS does not expose at the VM level: eviction type. Capacity-only eviction triggers solely when Azure needs the capacity back, and your price is capped at pay-as-you-go rates. Price-or-Capacity eviction allows you to set a maximum price to five decimal places, and the VM is evicted if the Spot price exceeds your cap. Setting the maximum price to -1 prevents price-based eviction entirely, meaning you pay the lower of the current Spot rate or the on-demand rate. This is a useful default for most production workloads. Azure pricing history is available for 90 days via Azure Resource Graph, and per-SKU eviction probability bands are surfaced in the portal and via API.
GCP Spot VMs offer the steepest published discount, up to 91% off on-demand, with pricing that is variable but changes at most once per day for any given resource. This makes GCP’s model the most predictable of the three. GCP’s Spot VMs replaced the legacy Preemptible VM type, which carried a hard 24-hour maximum runtime. Spot VMs have no such limit and can run indefinitely until preempted. Neither Committed Use Discounts nor Sustained Use Discounts apply to Spot VMs, making Spot the only discount mechanism available for this capacity class.
Neither Azure nor GCP publish precise interruption rate data with the granularity AWS provides. AWS’s Spot Instance Advisor reports trailing 30-day interruption frequency in five bands per instance type per region, with the historical cross-provider average below 5%. As of January 2026, AWS added per-account Spot interruption rate metrics to EC2 Capacity Manager for the first time, making it possible to track realised interruption performance against the Advisor’s predictions. Azure surfaces eviction probability ranges per SKU per region based on 7-day trailing data in the portal and 28-day data via API. GCP publishes no specific preemption rate data, noting only that rates vary by day and zone and recommending smaller machine types and off-peak scheduling for improved availability.
The Interruption Window: The Constraint That Governs Everything
The single most architecturally consequential difference between providers is not the price: it is how much time your application has before it stops running.
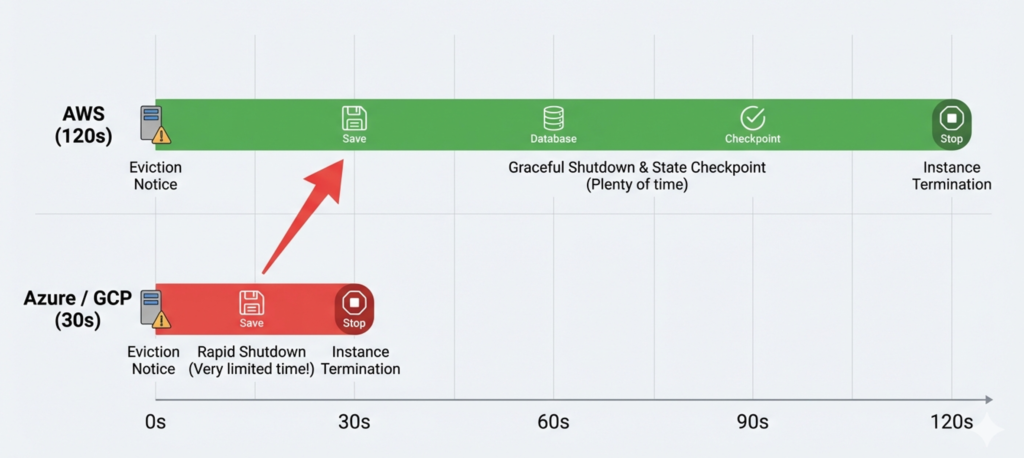
AWS provides a 2-minute interruption notice. When a Spot instance is selected for reclamation, it receives an interruption notice via the EC2 Instance Metadata Service, detectable by polling the IMDS endpoint every 5 seconds or by subscribing to the corresponding EventBridge event. AWS also emits a Rebalance Recommendation signal before the formal interruption notice when it detects elevated risk of reclamation. This is a softer signal with no guaranteed lead time, but it provides an additional window for proactive instance replacement before the hard clock starts.
Azure and GCP both provide approximately 30 seconds. Azure delivers a Preempt event via the Scheduled Events API on a best-effort basis with a minimum of 30 seconds’ notice. GCP sends an ACPI G2 soft-off signal that triggers your shutdown script, which has a hard ceiling of 30 seconds before a forced machine-off is applied. GKE documentation is explicit about this constraint: it recommends that non-system pod graceful termination be limited to 15 seconds within that window to allow the kubelet sufficient time to complete its own shutdown sequence.
This gap matters enormously in practice. A 2-minute AWS window allows an application to complete in-flight web requests, drain connections from a load balancer, flush buffered writes, and emit a final checkpoint. A 30-second Azure or GCP window is barely sufficient for the connection drain alone if your shutdown path has any complexity. The implication is that workloads designed with AWS’s generous window in mind, and relying on that window for correctness, can silently fail when ported to Azure or GCP. The safest architectural principle is to design for a 25-second shutdown window and treat the additional 90 seconds on AWS as a buffer, not a dependency.
The platform-agnostic graceful shutdown sequence follows four phases, all of which must complete within the available window. In the first phase the instance stops accepting new work: it deregisters from load balancers, marks health checks as unhealthy, and stops polling message queues. In the second phase it drains in-flight connections, allowing current requests to complete within a defined timeout and returning any uncommitted queue messages to their visible state so other workers can claim them. In the third phase it checkpoints state, flushing in-memory data to durable external storage, saving ML training progress, releasing distributed locks. In the fourth phase it closes database connections cleanly to free pool slots and exits with code zero. On Azure and GCP, phases one through three must run largely in parallel. On AWS they can run sequentially. Either way, the shutdown path must be exercised and timed before production deployment, not discovered during the first real eviction.
Workload Viability: A Decision Framework
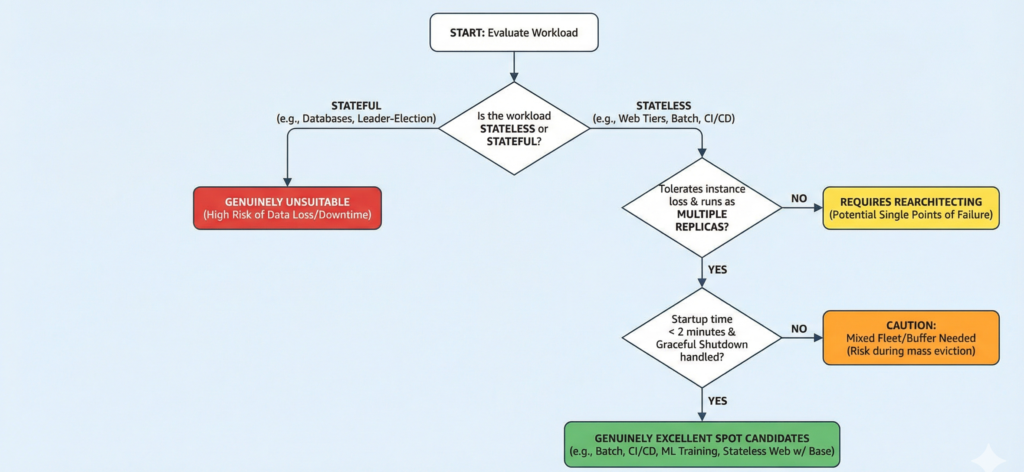
The viability question is not binary. Workloads exist on a spectrum from “drop-in replacement with no changes” to “requires fundamental rearchitecting” to “not suitable regardless of effort.”
Genuinely excellent Spot candidates share three characteristics: they tolerate instance loss without data loss, they run as multiple replicas so no single instance is a single point of failure, and their state lives outside the compute layer entirely. Batch processing pipelines, CI/CD build agents, ML training jobs, video rendering farms, and event-driven data processing on Spark, Dataflow, or EMR all fit this profile. CI/CD agents are arguably the easiest migration in the industry, being ephemeral by design, produce no persistent state, and a failed build simply retries. ML training is a close second, particularly on AWS where SageMaker’s managed Spot training automates checkpoint-to-S3-and-resume with a single configuration flag.
Stateless web tiers can run on Spot with the right mixed-fleet architecture, but they require sufficient on-demand base capacity to absorb a correlated eviction event. A fleet that is 90% Spot with a 10% on-demand base and no auto-scaling headroom will fail under a mass eviction. A fleet with a properly sized on-demand floor, fast Spot replenishment, and load shedding at the edge can tolerate significant Spot churn with no user-visible impact.
The genuinely unsuitable category is narrower than many teams assume, but it is real. Stateful databases are the clearest case, since sudden termination risks data corruption without careful configuration, and the replication topology assumes predictable node availability. Leader-election-sensitive clusters (etcd, ZooKeeper, Consul) face similar risks: leader loss triggers a re-election cycle that can take several minutes, during which writes are blocked. Latency-sensitive synchronous APIs with no fallback capacity are unsuitable unless the on-demand base is sized to serve 100% of traffic independently, at which point the economics of Spot become questionable. Any workload with a hard uptime SLA that cannot be met by the on-demand base alone belongs on committed capacity.
The blast radius calculation (how much of your fleet can safely run on Spot) lacks a single canonical answer, but a consistent pattern emerges from production deployments: 20-30% on-demand base capacity with 70-80% Spot for production web workloads, scaling to 100% Spot for batch, dev/test, and CI/CD where no SLA applies. On AWS, the Auto Scaling Group MixedInstancesPolicy codifies this with OnDemandBaseCapacity setting a fixed floor of on-demand instances and OnDemandPercentageAboveBaseCapacity controlling the Spot ratio for all capacity above that floor. Azure’s equivalent is the Spot Priority Mix in Flexible VMSS, with baseRegularPriorityCount and regularPriorityPercentageAboveBase serving the same function. The important subtlety on AWS is to avoid failing over from Spot to on-demand using the same instance type: this can increase Spot interruptions in that pool and simultaneously compete for on-demand capacity. Maintain separate, diversified pools for each purchase type.
Greenfield Design: Building for Interruption from Day One
Designing a workload for Spot from scratch means making statelessness the default, not an afterthought. The test is simple: if the current instance disappears in the next five seconds, what do you lose? If the answer is anything beyond CPU cycles, the architecture needs work.
This means logs shipped in real time rather than batched locally, sessions stored in an external distributed cache, all file processing streamed directly from object storage, and temporary state written to durable external stores on every meaningful boundary. An instance-local write is a liability on Spot; an external write is a recovery point.
Instance diversification is non-negotiable. AWS’s own guidance recommends flexibility across at least ten instance types per workload. A Spot capacity pool is defined as one instance type in one Availability Zone. If you pin to a single type and that pool experiences elevated demand, you receive zero capacity even when adjacent pools have surplus. AWS’s Attribute-Based Instance Type Selection, available in Auto Scaling Groups and EC2 Fleet since late 2021, addresses this by expressing requirements as vCPU and memory ranges rather than specific instance names. The fleet selects from all qualifying types automatically and includes new types as they launch. The allocation strategy matters as much as the pool size: the price-capacity-optimized strategy, AWS’s recommended default, balances price against capacity availability. Tests by engineering teams comparing strategies have shown that the deprecated lowest-price strategy can produce significantly more interruptions, sometimes several times the rate of price-capacity-optimized, for relatively modest cost savings.
Queue-based decoupling is the foundational resilience pattern for processing workloads on Spot. Producers place work items on a durable queue (SQS, Cloud Tasks, Azure Service Bus, or Pub/Sub). Spot workers act as stateless consumers that acquire a message, process it, and delete it on success. If a worker is evicted mid-processing, the message’s visibility timeout expires and another worker acquires it. This architecture requires idempotent job execution: if a message is processed more than once, the outcome must be the same. Without idempotency, retries produce duplicate writes or corrupted aggregates.
Checkpointing for long-running jobs must be a continuous property of normal operation, not an emergency measure executed at shutdown. Checkpoint intervals of 5-15 minutes balance recovery overhead against I/O cost. On AWS SageMaker, checkpoint data written to a local path is automatically synchronised to S3; on restart, the training job resumes from the last checkpoint without application-level intervention. Equivalent patterns on GCP Vertex AI Pipelines and Azure ML use object storage in the same way.
Brownfield Migration: The Strangler Fig Approach
Migrating existing workloads to Spot demands a risk-ordered sequence. The teams that encounter mass eviction during peak demand are almost always the ones that migrated too aggressively and too early in the adoption curve.
The correct sequence follows a strict gradient from lowest to highest production risk. The first phase covers dev/test environments, CI/CD build agents, and scheduled batch jobs. These workloads carry no production SLA, they are already expected to fail occasionally, and the retry logic either already exists or is trivial to add. This phase provides the operational experience of eviction events in the CloudWatch or Azure Monitor logs, observed recovery times, actual interruption frequencies that informs every subsequent decision.
The second phase addresses async processing workloads: ETL pipelines, data transformation jobs, background media processing, ML training. These workloads have well-defined retry semantics and the state externalisation patterns are straightforward. Migration here produces meaningful cost savings with manageable risk.
The third phase involves stateless web tiers, and this is where the mixed-fleet architecture becomes load-bearing. The on-demand base must be sized to serve peak traffic independently, with Spot providing cost-efficient burst capacity. Session state must have already been externalised to a distributed cache, the most common brownfield blocker and the work that must happen before migration, not during it. Startup time matters here: instances with cold start times exceeding two minutes will not provision quickly enough to absorb a sudden eviction event. Optimise your machine image and bootstrap process before attempting this phase.
The common architectural changes required for brownfield migration are predictable: externalising session state from in-process memory to Redis or an equivalent distributed cache, adding idempotency to job processing logic, removing hardcoded instance type assumptions from configuration management and autoscaling rules, implementing SIGTERM handlers in application code with appropriate timeouts, and adopting immutable server patterns so instance replacement is a routine operation rather than a surgical procedure. The most frequently overlooked change is the SIGTERM handler: applications that ignore SIGTERM and wait for a forced SIGKILL will exhaust the graceful shutdown window without doing any useful work.
The most common failure mode when migrating too aggressively is a correlated mass eviction during peak demand. This typically happens when Spot represents more than 80% of fleet capacity without sufficient on-demand base, when all Spot instances are in a single capacity pool, or when the on-demand fallback uses the same instance type as the Spot pool (which can trigger further evictions). Test your fallback behaviour explicitly before it is needed. AWS Fault Injection Service, Azure Chaos Studio, and GCP’s equivalent chaos tooling allow you to simulate eviction events in controlled conditions. The first real eviction in your fleet should not be your first test of your recovery path.
Kubernetes on Spot: Node Pools, Karpenter, and the PDB Caveat
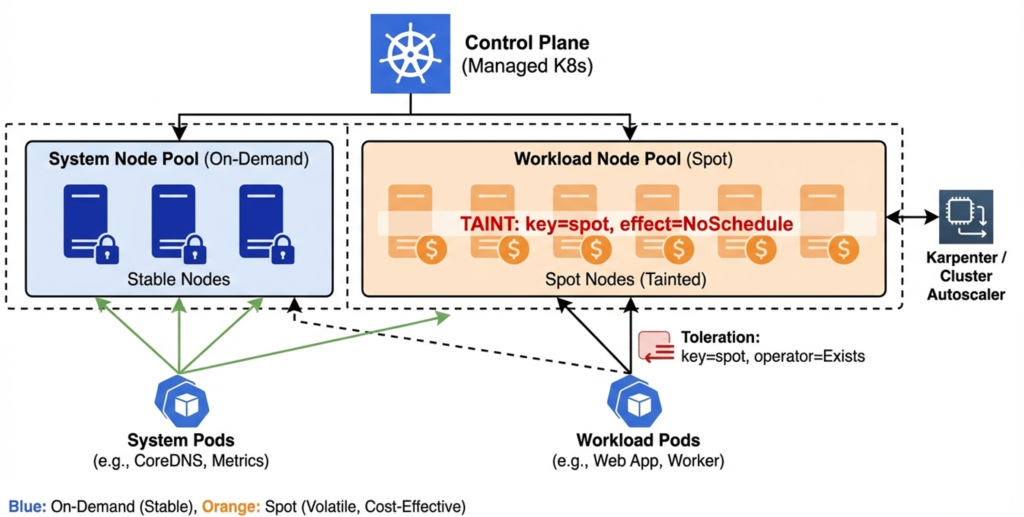
Kubernetes is now the dominant operational model for containerised Spot workloads, and all three managed services support dedicated Spot node pools, but with meaningfully different defaults that affect how you design your node topology.
On EKS, managed node groups configured with capacityType: SPOT automatically apply the price-capacity-optimized allocation strategy and opt into Capacity Rebalancing. EKS applies the label eks.amazonaws.com/capacityType=SPOT to Spot nodes but does not automatically apply a taint [VERIFY BEFORE PUBLISHING: confirm current EKS behaviour in managed node group documentation]. The practical consequence is that without an explicit taint and toleration pattern, pods will schedule onto Spot nodes by default, including workloads that should be protected on on-demand capacity. The recommended pattern is a dedicated on-demand system node pool for cluster-critical infrastructure and Spot node pools for workload capacity, with node affinity and tolerations used to enforce placement.
On AKS, an immutable taint (kubernetes.azure.com/scalesetpriority=spot:NoSchedule) is applied automatically to all Spot node pool nodes, and a webhook prevents its removal. This means workloads must opt in to Spot scheduling explicitly via tolerations, which is the safer default. AKS Spot pools must be user pools; they cannot serve as the system node pool. Microsoft recommends the Delete eviction policy rather than Deallocate, because deallocated nodes count against quota and cause scale-out failures. For a detailed look at AKS node pool architecture more broadly, the AKS enterprise implementation guide covers the full production pattern including system and user pool design.
On GKE, Spot node pools automatically apply cloud.google.com/gke-spot=true:NoSchedule. A critical constraint specific to GKE is that it limits graceful termination for non-system pods to 15 seconds within the 30-second shutdown window, leaving only 15 seconds for kubelet shutdown tasks. Workloads that require longer drain times should not run on GKE Spot pools without explicit engineering to complete shutdown within that budget.
There is an important nuance about Pod Disruption Budgets that is frequently misunderstood. PDBs govern voluntary disruptions (node drains, rolling updates, scale-down events) and provide a guarantee about the minimum number of available pods during these operations. They do not protect against involuntary disruption caused by the underlying VM being reclaimed. When Karpenter, the Node Termination Handler, or a managed node group detects an upcoming eviction and initiates a drain, that drain is a voluntary disruption and PDBs apply. But if the eviction window expires before the drain completes, the VM is terminated regardless of PDB status. On GCP and Azure, with 30-second windows, this is a real risk for pods with long graceful termination periods.
Karpenter represents a materially better operational model for Spot on AWS compared to Cluster Autoscaler. Where Cluster Autoscaler operates against pre-defined node groups with fixed instance type lists, Karpenter calls the EC2 Fleet API directly, passing all eligible instance types and allowing EC2 to apply price-capacity-optimized selection across them. A single Karpenter NodePool can span hundreds of instance types, eliminating the manual curation of instance type lists that Cluster Autoscaler requires. Karpenter handles interruptions natively through an EventBridge-to-SQS pipeline, cordoning and draining affected nodes while provisioning replacements in parallel. Since version 0.34.0, Karpenter also supports Spot-to-Spot consolidation (replacing existing Spot nodes with cheaper alternatives as prices shift), but AWS recommends maintaining at least 15 eligible instance types in any NodePool to prevent consolidation from pushing the entire fleet toward the cheapest and most frequently interrupted capacity pools.
Real-World Case Studies
Company Name & Industry: ITV, UK broadcast and streaming media
Scale Context: Platform serving ITV Hub and BritBox; 75% of workloads on EKS
Challenge: Scaling containerised streaming workloads cost-effectively while maintaining availability for live broadcast events and on-demand content delivery
Solution Implemented: EKS with mixed Spot and on-demand node groups; Spot grown from 9% to 24% of total compute across production workloads
Measurable Outcomes:
- 60% reduction in compute costs for Spot-eligible workloads
- £150,000 annual compute cost reduction
- Production availability maintained across live broadcast events
Source: https://aws.amazon.com/solutions/case-studies/itv-case-study/
Company Name & Industry: Mapbox, mapping and location data platform
Scale Context: Processing over 1.3 billion requests daily across maps, navigation, and geospatial services
Challenge: Running compute-intensive map tile generation and navigation processing at scale while managing infrastructure costs for a usage-based business model Solution Implemented: Dual Auto Scaling Group waterfall architecture, with Spot variants attempted first across multiple instance families and AZs, with on-demand as last resort; Spot interruptions handled through checkpointing and job retry
Measurable Outcomes:
- Over 98% of runtime running on Spot instances
- 90% cost savings on maps service compute
- Spot interruptions occurring approximately 1-2 times per month
Source: https://aws.amazon.com/blogs/aws/semi-autonomous-driving-using-ec2-spot-instances-at-mapbox/
Company Name & Industry: amaysim, Australian telecommunications provider
Scale Context: 1.2 million customers; billing platform, self-service portal, and customer-facing applications all in scope
Challenge: Running 100% of production telecommunications infrastructure cost-effectively while meeting customer-facing SLA requirements
Solution Implemented: 100% of production compute on Spot across 6 instance families; mixed fleet with instance diversification across families and AZs; full retry and idempotency instrumentation across billing and customer-facing services
Measurable Outcomes:
- 75% reduction in compute costs
- Production customer-facing applications maintained on Spot throughout
- Zero reported SLA breaches attributable to Spot evictions
Source: https://aws.amazon.com/solutions/case-studies/amaysim-spot/
Cost Analysis and ROI
The discount headline is straightforward: with AWS historically below 5% average interruption rates and discounts of 70-90%, a fleet running 70% Spot and 30% on-demand achieves an effective compute cost reduction of roughly 50-63% compared to pure on-demand, accounting for the cost of fallback instances during interruption events. The amaysim result of 75% savings at 100% Spot represents the upper bound achievable when workloads are fully rearchitected; ITV’s 60% is more representative for organisations migrating a mixed production estate.
The hidden costs that most initial cost models miss fall into three categories. The first is operational overhead: implementing and maintaining interruption handlers, checkpoint logic, and fallback automation requires engineering time, and the ongoing operational discipline to keep instance type lists current and diversified is non-trivial. For teams without prior Spot experience, budget four to six weeks of platform engineering time for the foundational architecture before any application migration begins. The second hidden cost is fallback compute: when a mass eviction triggers on-demand fallback, you pay on-demand rates until Spot capacity is replenished. Size your on-demand base to serve peak traffic and your cost model will absorb these spikes. Undersize it and you will experience both incidents and unexpected cost spikes simultaneously. The third is instance type maintenance: new instance types launch regularly, and a pool that was optimally diversified six months ago may be suboptimal today. Building instance type selection from attributes rather than names (where supported) reduces this overhead significantly.
The FinOps governance layer for Spot requires tracking realised savings rather than theoretical maximum discounts. The realised savings formula is: (on-demand equivalent cost minus actual total cost including fallback) divided by on-demand equivalent cost. AWS provides a native Savings Summary in the EC2 console with per-account Spot savings data, and the new EC2 Capacity Manager metrics added in January 2026 expose per-account interruption rate for the first time, enabling teams to track whether their interruption performance matches the Spot Instance Advisor’s predictions for their chosen instance types. For a broader view of how Spot savings fit into a multi-lever cloud cost strategy, the FinOps Evolution guide on this blog covers the full spectrum from tactical cost reduction to strategic value creation.
Implementation Roadmap
Phase 1: Foundation (Months 1-2): Establish the operational baseline before migrating any workload. This means instrumenting your existing fleet for Spot-readiness assessment (which workloads are stateless, which have retry logic, which have local state dependencies. Deploy Spot for dev/test environments and CI/CD build agents. These migrations carry no production risk and generate the interruption event data that informs your architectural decisions. Configure your monitoring to capture Spot interruption events, recovery times, and fallback behaviour. Set up the Spot Instance Advisor or equivalent Azure/GCP tooling as part of your regular cost review cadence. Deliverables: Spot-enabled dev/test environment, CI/CD build pipeline on Spot, interruption monitoring in place.
Phase 2: Batch and Async Workloads (Months 3-5): Migrate batch processing, ETL pipelines, and async event processing. These workloads require explicit checkpoint and retry instrumentation, which will take engineering time but produces patterns that the subsequent web tier migration can reuse. Implement the queue-based decoupling pattern for any job processing workloads. Begin instance type diversification across at least five to eight instance families per workload. Measure realised savings against your cost model assumptions from Phase 1. Deliverables: batch and ETL workloads on Spot, queue-based retry patterns documented and deployed, first realised savings measurement.
Phase 3: Production Web Tiers and Kubernetes (Months 6-10): Migrate stateless web tier capacity to mixed fleets, with on-demand base sized for peak traffic and Spot providing burst capacity. If running Kubernetes, deploy dedicated Spot node pools with explicit taint and toleration patterns, and evaluate Karpenter for AWS or Cluster Autoscaler priority expander configuration for Azure and GCP. Run chaos experiments to validate eviction handling under load before cutover. This phase produces the largest cost impact and carries the most production risk. Do not compress the timeline to chase savings targets. Deliverables: mixed fleet production web tier, Spot Kubernetes node pools, chaos-validated interruption handling, full FinOps cost tracking against baseline.
Decision Framework
The decision to run a workload on Spot should be evaluated against five criteria. First, can the workload tolerate instance loss without data loss? If state lives outside the compute layer entirely and jobs are idempotent, the answer is yes. If the workload writes to local disk and reads it back, the answer is no until that is changed. Second, can the workload run across multiple replicas with no single point of failure? Anything with a single-instance architecture is unsuitable unless that architecture is changed first. Third, is the startup time under two minutes? Applications with long bootstrap sequences cannot recover within the interruption window. Fourth, does the workload have a hard uptime SLA that cannot be met by the on-demand base alone? If yes, the Spot portion should be treated as capacity that can disappear at any moment, and the SLA commitment must be backed entirely by on-demand or reserved capacity. Fifth, has your graceful shutdown path been tested end-to-end? The answer to this must be yes before any production migration.
Workloads that fail criteria one through three should not be migrated to Spot until the underlying architectural issues are resolved. Workloads that fail criterion four can still use Spot for burst capacity, provided the on-demand base is self-sufficient. The organisations achieving the headline savings numbers arrived there because they resolved these criteria systematically before migration, not by accepting the risk and hoping the eviction rate stayed low.
Future Considerations
The Spot landscape is shifting in two meaningful directions. The first is AI and GPU compute. GPU instance Spot discounts on AWS are substantial, often 60-70% off on-demand, and ML training is one of the best-suited workload types for Spot by architecture. SageMaker’s managed Spot training, Vertex AI Pipelines’ checkpoint support, and the proliferating GPU instance families across all three providers are converging to make Spot the default choice for model training at scale. The checkpointing patterns established for CPU workloads translate directly.
The second shift is the increasing abstraction of Spot mechanics into managed services. Karpenter increasingly handles instance diversification, interruption detection, and replacement as a platform concern rather than an application concern. AWS Batch, Google Cloud Batch, and Azure Batch all expose Spot as a first-class scheduling option with built-in retry semantics. As these abstractions mature, the engineering burden of Spot adoption shifts from application teams to platform teams, which is the right direction, but it requires platform engineering investment to establish the foundations that enable application teams to opt in safely.
Strategic Recommendations
For organisations that have not yet deployed Spot in any form: start with CI/CD and dev/test. The engineering investment is minimal, the risk is zero, and the operational experience gained in the first few weeks removes most of the uncertainty that delays production adoption.
For organisations with Spot in dev/test but not production: the bottleneck is almost always session state externalisation and SIGTERM handling in application code. These are application-level changes that require coordination with development teams but are not architecturally complex. Prioritise them over any further infrastructure work.
For organisations running Spot in production but below 50% of eligible capacity: the likely constraint is insufficient instance type diversification or an on-demand base that has been sized too conservatively. Revisit your pool configuration and run chaos experiments to establish actual recovery times before expanding Spot coverage.
The organisations that achieve 70-90% effective savings from Spot share one characteristic: they treated the architectural prerequisites as non-negotiable before the first production migration. The discount is real, the mechanics are well-documented, and the operational patterns are proven at scale. The only remaining variable is the engineering discipline to implement them in the right order.
Useful Links
- AWS EC2 Spot Instance best practices
- AWS Spot Instance Advisor (interruption frequency by instance type
- AWS EC2 Spot interruption notices and rebalance recommendations
- Azure Spot VM documentation and eviction policies
- Azure Spot Priority Mix for VMSS
- GCP Spot VM documentation
- GKE Spot VM node pool guidance
- ITV case study: EKS and Spot Instances
- Mapbox: Spot Instances at scale
- amaysim: 75% compute cost reduction with Spot