GCP Committed Use Discounts (CUDs) offer 20-57% savings on compute resources, yet most organizations leave money on the table by purchasing commitments manually or not at all. The Cloud Billing API provides the data needed to automate CUD analysis, but extracting actionable recommendations requires understanding usage patterns, calculating break-even thresholds, and timing purchases strategically.
This automation framework analyses your GCP usage, identifies optimal commitment opportunities, and generates purchase recommendations with ROI calculations, eliminating the guesswork from commitment decisions.
The Problem: Manual CUD Analysis Leaves Money on the Table
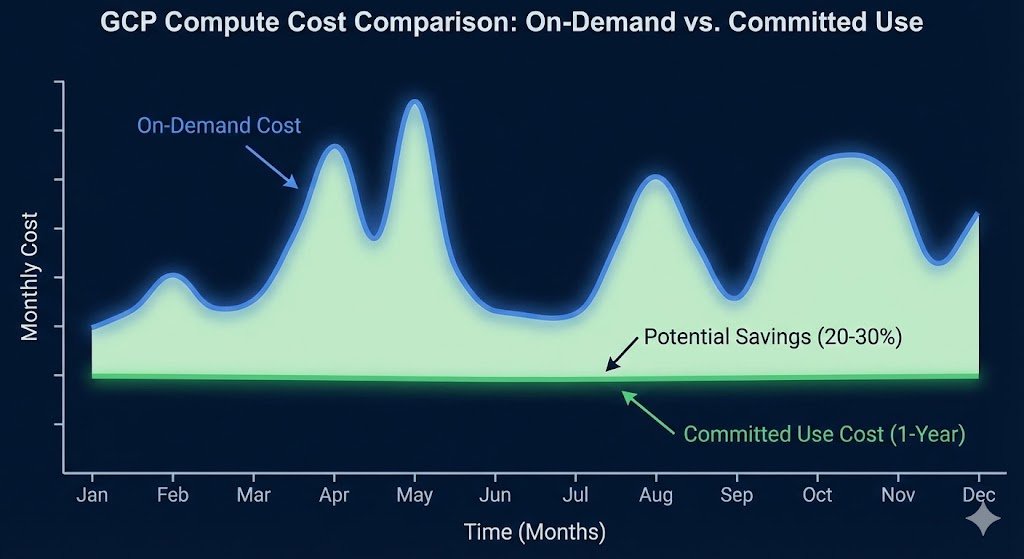
Platform teams managing GCP environments face a recurring challenge: determining which resources justify Committed Use Discounts and whether 1-year or 3-year commitments deliver better returns. The GCP console provides basic recommendations, but these lack critical context.
Manual analysis limitations:
- Missing Context: Console recommendations don’t account for planned capacity changes or future roadmap items.
- No “Safety Buffer”: Manual calculations often fail to account for usage variance, leading to over-commitment.
- Hidden Complexity: Comparing the break-even point for a 1-year vs. 3-year commitment requires complex modeling.
- Reactive, Not Proactive: Time-consuming monthly reviews often miss optimization opportunities until the bill arrives.
The financial impact compounds quickly. A typical enterprise running 500 vCPUs continuously wastes approximately £180,000 / $220,000 annually by not leveraging CUDs effectively.
The Solution: Automated CUD Analysis Framework
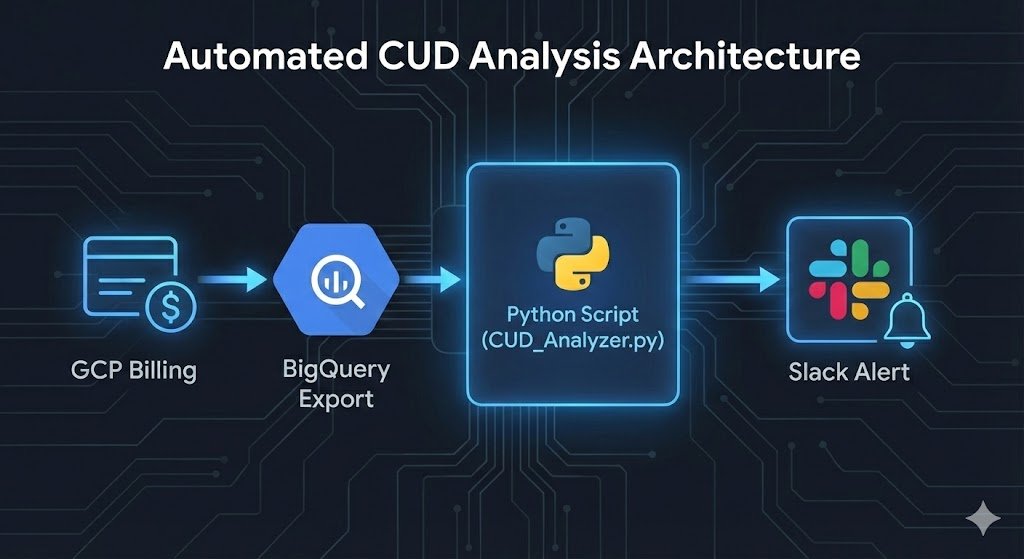
This Python framework uses the Cloud Billing API and BigQuery billing exports to analyze usage patterns and generate CUD recommendations with ROI calculations.
Note on Scope: This framework specifically targets Resource-based CUDs (Compute Engine vCPUs). While Spend-based CUDs (for Cloud Run, Spanner, etc.) are valuable, they require a different analytical approach.
Prerequisites
Bash
# Install required packages
pip install google-cloud-billing google-cloud-bigquery pandas db-dtypes --break-system-packages
# Enable required APIs
gcloud services enable cloudbilling.googleapis.com
gcloud services enable bigquery.googleapis.com
# Set up BigQuery billing export (if not already configured)
# Navigate to Billing > Billing export in GCP ConsoleCore Analysis Script
This updated script includes logic to exclude Preemptible/Spot instances (which cannot be covered by CUDs) and applies conservative discount estimates.
Note: This script analyzes vCPUs. To analyze RAM, you can modify the SQL query to search for ‘Instance Ram’ SKUs.
Python
#!/usr/bin/env python3
"""
GCP CUD Optimization Analyzer
Analyzes 90-day usage patterns and generates CUD purchase recommendations
"""
from google.cloud import bigquery
from datetime import datetime, timedelta
import pandas as pd
class CUDAnalyzer:
def __init__(self, project_id, billing_dataset, billing_table):
self.client = bigquery.Client(project=project_id)
self.billing_dataset = billing_dataset
self.billing_table = billing_table
self.analysis_days = 90
self.currency_symbol = "$" # Update to £ or € if required
def analyze_compute_usage(self):
"""
Query 90 days of compute usage to identify CUD opportunities.
Filters for specific Instance Core usage and EXCLUDES Spot/Preemptible VMs.
"""
query = f"""
SELECT
service.description AS service,
sku.description AS sku_description,
location.region AS region,
DATE(usage_start_time) AS usage_date,
SUM(usage.amount) AS total_usage,
SUM(cost) AS total_cost,
cost_type
FROM
`{self.billing_dataset}.{self.billing_table}`
WHERE
DATE(usage_start_time) >= DATE_SUB(CURRENT_DATE(), INTERVAL {self.analysis_days} DAY)
AND service.description IN ('Compute Engine', 'Kubernetes Engine')
AND sku.description LIKE '%Instance Core%'
AND sku.description NOT LIKE '%Preemptible%' -- Exclude Spot/Preemptible
AND sku.description NOT LIKE '%Spot%'
AND cost_type = 'regular' -- Exclude existing CUD costs
GROUP BY
service, sku_description, region, usage_date, cost_type
ORDER BY
total_cost DESC
"""
return self.client.query(query).to_dataframe()
def calculate_cud_recommendations(self, usage_df):
"""
Calculate optimal CUD purchases based on usage patterns
Recommends commitments at 80% of minimum daily usage (safety buffer)
"""
# Group by service and region
# Note: In production, also group by 'sku_description' to distinguish N1 vs N2 vs E2
region_usage = usage_df.groupby(['service', 'region']).agg({
'total_usage': ['min', 'mean', 'max'],
'total_cost': 'sum'
}).reset_index()
recommendations = []
for _, row in region_usage.iterrows():
# CRITICAL: Convert usage from "Seconds" to "Concurrent vCPUs"
# BigQuery export typically stores Instance Core usage in seconds.
# We divide by 86,400 (seconds in a day) to get the average core count.
seconds_in_day = 86400
min_daily_cores = row[('total_usage', 'min')] / seconds_in_day
avg_daily_cores = row[('total_usage', 'mean')] / seconds_in_day
total_cost = row[('total_cost', 'sum')]
# Recommend commitment at 80% of minimum usage (safety buffer)
recommended_commitment = min_daily_cores * 0.8
if recommended_commitment < 0.5: # Skip insignificant usage
continue
# Calculate annualized cost without CUDs
annual_cost_without_cud = (total_cost / self.analysis_days) * 365
# 1-year CUD savings (Estimated 25% discount)
one_year_savings = annual_cost_without_cud * recommended_commitment / avg_daily_cores * 0.25
# 3-year CUD savings (Estimated 52% discount)
three_year_savings = annual_cost_without_cud * recommended_commitment / avg_daily_cores * 0.52
recommendations.append({
'service': row[('service', '')],
'region': row[('region', '')],
'recommended_vcpus': round(recommended_commitment, 2),
'min_daily_usage': round(min_daily_cores, 2),
'avg_daily_usage': round(avg_daily_cores, 2),
'annual_cost_no_cud': round(annual_cost_without_cud, 2),
'one_year_annual_savings': round(one_year_savings, 2),
'three_year_annual_savings': round(three_year_savings, 2),
'recommendation': '3-year CUD' if three_year_savings > one_year_savings * 2.5 else '1-year CUD'
})
return pd.DataFrame(recommendations)
def generate_report(self):
"""Generate comprehensive CUD recommendations report"""
print("Analyzing GCP usage patterns...")
usage_df = self.analyze_compute_usage()
if usage_df.empty:
print("No eligible usage found for CUD recommendations")
return
print(f"Analyzed {len(usage_df)} days of usage data")
recommendations = self.calculate_cud_recommendations(usage_df)
# Sort by potential savings
recommendations = recommendations.sort_values('three_year_annual_savings', ascending=False)
print("\n" + "="*80)
print("GCP COMMITTED USE DISCOUNT RECOMMENDATIONS")
print("="*80)
total_potential_savings = recommendations['three_year_annual_savings'].sum()
print(f"\nTotal Potential Annual Savings: {self.currency_symbol}{total_potential_savings:,.2f}")
print(f"Analysis Period: {self.analysis_days} days")
print(f"Safety Buffer: 80% of minimum daily usage\n")
for _, rec in recommendations.iterrows():
print(f"\nService: {rec['service']} | Region: {rec['region']}")
print(f" Recommended Commitment: {rec['recommended_vcpus']:.2f} vCPUs")
print(f" Usage Pattern: Min {rec['min_daily_usage']:.2f} / Avg {rec['avg_daily_usage']:.2f} vCPUs")
print(f" 1-Year CUD Savings: {self.currency_symbol}{rec['one_year_annual_savings']:,.2f}/year (Est. 25%)")
print(f" 3-Year CUD Savings: {self.currency_symbol}{rec['three_year_annual_savings']:,.2f}/year (Est. 52%)")
print(f" Recommendation: {rec['recommendation']}")
return recommendations
# Usage
if __name__ == "__main__":
analyzer = CUDAnalyzer(
project_id="your-project-id",
billing_dataset="your_billing_dataset",
billing_table="gcp_billing_export_v1_XXXXXX"
)
recommendations = analyzer.generate_report()
# Export to CSV for stakeholder review
if recommendations is not None:
recommendations.to_csv(f'cud_recommendations_{datetime.now().strftime("%Y%m%d")}.csv', index=False)
print(f"\nRecommendations exported to CSV")
Example Output
When running the script against a production dataset, the output clearly highlights where steady-state workloads are ripe for savings:
| Service | Region | Recommended vCPUs | Min/Avg Usage | 1-Year Savings | 3-Year Savings | Recommendation |
| Compute Engine | europe-west2 | 48.50 | 60.0 / 85.2 | £12,450 | £25,800 | 3-Year CUD |
| Compute Engine | us-central1 | 12.20 | 15.5 / 18.0 | £3,100 | £6,400 | 1-Year CUD |
| Kubernetes Engine | europe-west2 | 110.00 | 138.0 / 150.5 | £28,200 | £58,500 | 3-Year CUD |
Automated Alerting Integration
To make this actionable, we can integrate the output with Slack to notify the FinOps or Platform team monthly.
Python
def send_slack_notification(recommendations, webhook_url):
"""
Send CUD recommendations to Slack channel
Useful for monthly reviews and renewal alerts
"""
import requests
import json
total_savings = recommendations['three_year_annual_savings'].sum()
top_opportunities = recommendations.head(3)
message = {
"text": f"GCP CUD Optimization Report",
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": f"💰 Potential Savings: £{total_savings:,.2f}/year"
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*Top Opportunities:*\n" + "\n".join([
f"• {row['service']} ({row['region']}): £{row['three_year_annual_savings']:,.2f}/year"
for _, row in top_opportunities.iterrows()
])
}
}
]
}
requests.post(webhook_url, data=json.dumps(message), headers={'Content-Type': 'application/json'})
Enterprise Considerations
Commitment Flexibility: GCP’s CUD model applies at the project level but can be shared across projects in a billing account. Structure your analysis by billing account to maximize commitment utilisation across teams. This differs from AWS Reserved Instances, which are account-specific by default.
vCPU vs. RAM Commitments: The script above focuses on vCPUs, which often drive the bulk of compute costs. However, GCP requires you to commit to vCPU and Memory separately for Resource-based CUDs. You should run a similar analysis for RAM (filtering for Instance Ram SKUs) before finalizing your purchase.
Multi-Year Commitment Risk: Three-year CUDs deliver maximum savings (52% vs 25% for 1-year) but require confidence in sustained usage. Our FinOps Evolution guide recommends 3-year commitments only for baseline workloads with proven 18+ month stability. Use 1-year CUDs for growing or experimental workloads.
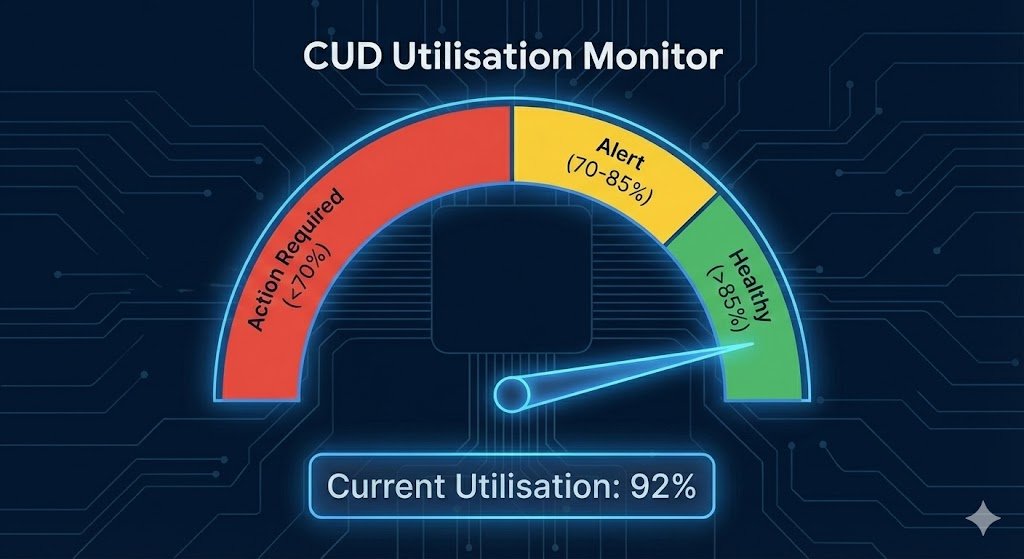
Monitoring Utilisation: Deploy Cloud Monitoring alerts when CUD utilisation drops below 85%. Under-utilised commitments (below 70%) indicate over-purchasing and require commitment adjustments at renewal. Track utilisation metrics in your cost dashboards alongside our automated cost anomaly detection patterns.
Key Takeaways
- Automate analysis of 90-day usage patterns using Cloud Billing API and BigQuery exports to identify optimal CUD opportunities.
- Filter smartly by excluding Preemptible and Spot instances from your baseline calculations.
- Apply safety buffers (80% of minimum usage) to avoid over-commitment from usage variance.
- Review quarterly alongside capacity planning to adjust commitments for infrastructure changes.