

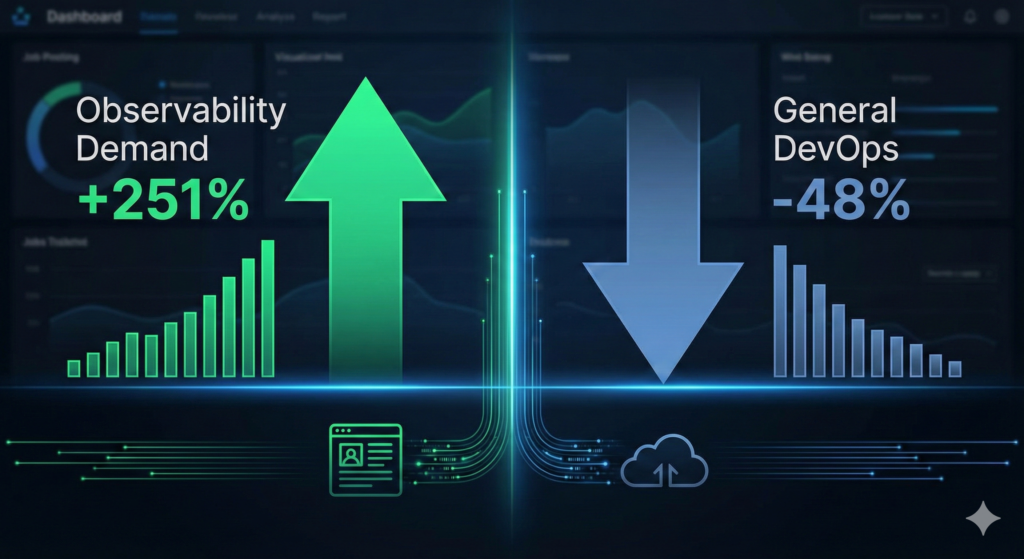
Observability specialists in the UK now command a median salary of £80,000, representing a 14% premium over general DevOps engineers and an 18% premium over cloud engineers. More striking still, senior observability roles at the 90th percentile reach £130,000, a figure that climbs past £150,000 for staff-level platform engineers at organisations like Citi, Wise, and Apple’s London office. Over the past two years, job postings citing observability skills have surged 251%, even as general DevOps postings declined 48%. For mid-to-senior cloud professionals, this represents the single most efficient career acceleration available in UK tech today.
Most cloud engineers approach their careers by accumulating generalist skills across AWS, Azure, Kubernetes, and CI/CD, expecting gradual progression from £60K to £90K over five to seven years. This approach worked well in 2018, but the market has fundamentally shifted. Regulatory pressure from the FCA’s operational resilience regime and the new DORA requirements, combined with the explosion of microservices architecture, has created urgent demand for specialists who can design, implement, and optimise enterprise observability platforms. Yet organisations struggle to hire because observability sits at the intersection of distributed systems, data engineering, networking, and application performance, a combination few engineers possess. The result is a severe skills shortage driving sustained salary premiums.
Consider the career trajectory at Monzo, which operates 2,800+ microservices with observability “baked into the platform by default.” Engineers who joined as mid-level DevOps practitioners and specialised in observability infrastructure now architect telemetry pipelines handling billions of metrics daily. Similarly, Citi is hiring an SRE Observability Lead at Senior Vice President level to define “strategic vision for observability across Services Technology,” a role commanding well into six figures. These aren’t hypothetical opportunities. The path from £60K generalist to £130K+ observability platform architect is mapped by real job postings available today, and the window is open now before the market saturates.
The Four-Level Observability Career Framework
Career progression in observability follows a distinct pattern that differs from traditional infrastructure paths. Where DevOps careers often plateau at senior engineer unless you transition to management, observability creates a clear individual contributor track to staff and principal levels because the discipline combines deep technical expertise with direct business impact. Understanding this framework helps you identify your current position and plan the specific skills needed for each advancement.
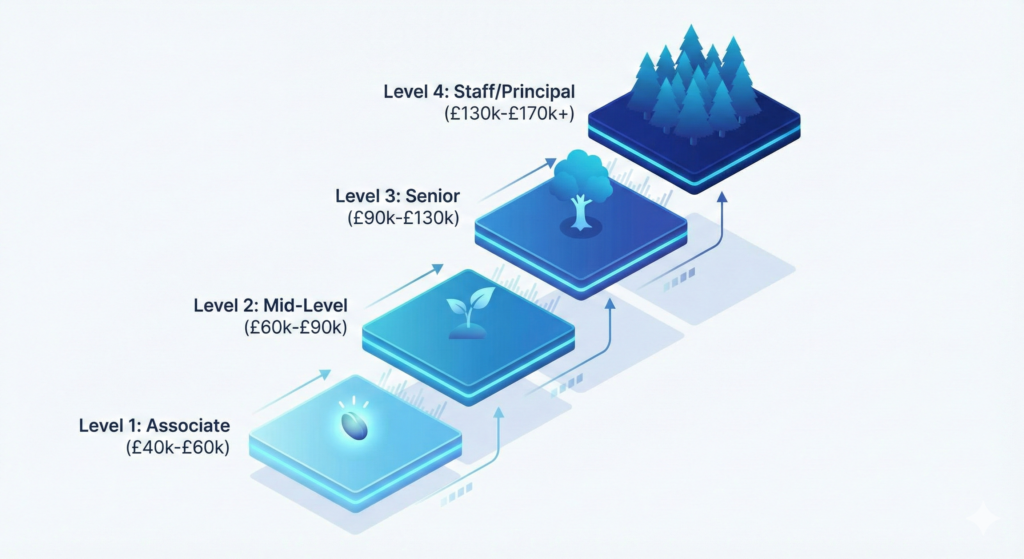
Level 1 represents Observability Associate roles (£40K-£60K), typically found at organisations building out their initial monitoring capabilities. You work under guidance to deploy Prometheus, configure Grafana dashboards, and instrument basic metrics. The focus is execution: implementing established patterns rather than designing them. Companies like Canonical and NETbuilder offer graduate and junior observability roles at this level.
Level 2 encompasses Mid-Level Observability Engineers (£60K-£90K) who independently design monitoring solutions for specific services or teams. You instrument applications with custom metrics, build distributed tracing, and architect alerting strategies that reduce noise. At this stage, you transition from “monitoring what we have” to “observing how systems behave,” understanding the three pillars (metrics, logs, traces) as complementary lenses rather than separate tools.
Level 3 defines Senior Observability Engineers (£90K-£130K) responsible for organisation-wide observability platforms. You design scalable infrastructure that serves dozens or hundreds of engineering teams, make build-versus-buy decisions for observability tooling, and bridge the gap between infrastructure monitoring and application performance management. This level demands architectural thinking, strong programming skills (particularly Go), and the ability to quantify business impact. Wise, G-Research, and NTT Data are actively hiring at this level.
Level 4 comprises Staff and Principal Observability Engineers (£130K-£170K+) who define company observability strategy, manage substantial tooling budgets (often £100K-£1M+ annually), and drive organisational transformation from reactive monitoring to proactive observability. These roles exist at Citi (SVP level), Apple, and major financial institutions where observability underpins regulatory compliance and business continuity. The work is as much leadership and strategy as it is technical architecture.
Technical Skills Mapped to Career Outcomes
The technical competencies that separate each salary band are specific and testable. More importantly, each skill directly enables particular career opportunities rather than merely expanding your CV.
Foundation Skills (£40K-£60K): Entry to Observability Roles
Prometheus setup and basic PromQL queries form the bedrock. You need to deploy Prometheus via Docker or Kubernetes, understand the metric types (counter, gauge, histogram, summary), and write queries using rate(), increase(), and basic aggregations. Grafana dashboard creation means more than dragging panels onto a canvas. You need to understand visualisation types (time series, gauge, bar chart) and when each serves the user’s needs. Basic Linux administration, Docker fundamentals, and Python or Bash scripting round out the entry requirements.
These skills unlock graduate and junior roles at organisations building monitoring infrastructure, typically paying £40K-£60K depending on location. London roles skew £5K-£10K higher than regional positions, though observability shows smaller geographic wage gaps than most specialisations.
Mid-Level Competencies (£60K-£90K): Independent Implementation
Advanced PromQL separates capable practitioners from beginners. Recording rules optimise expensive queries, subqueries enable complex calculations, and functions like histogram_quantile() extract meaningful percentiles from histogram data. Kubernetes monitoring requires deploying Prometheus Operator and understanding kube-state-metrics versus cAdvisor versus node-exporter, each exposing different telemetry dimensions. Distributed tracing with Jaeger or Grafana Tempo demands understanding sampling strategies (head-based versus tail-based) and trace context propagation across service boundaries.
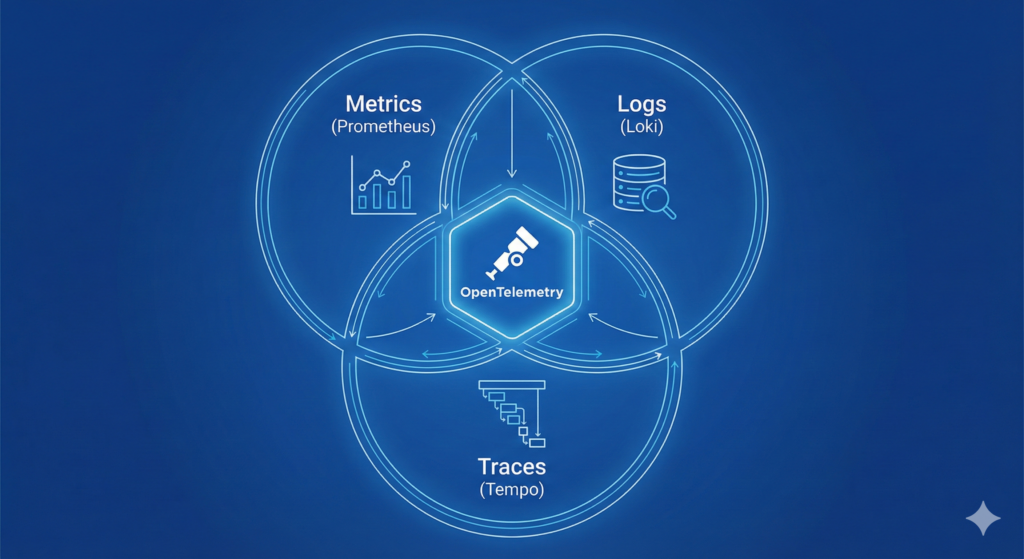
OpenTelemetry instrumentation at this level means adding the SDK to applications, configuring exporters, and understanding how traces, metrics, and logs correlate. Log aggregation with Loki or ELK Stack involves parsing strategies, index design, and query optimisation. Terraform proficiency allows you to define observability infrastructure as code, version controlling your monitoring alongside your applications.
These capabilities position you for roles at scale-ups and mid-size enterprises building out observability practices. Companies like Deliveroo, smaller FinTechs, and consultancies hire at this level for £60K-£90K, with contract positions offering £400-£550 per day.
Senior Expertise (£90K-£130K): Architectural Leadership
Senior observability demands designing platforms that serve entire organisations. This means deploying highly available Prometheus using Thanos, Cortex, or Mimir for long-term storage and multi-cluster aggregation. Advanced OpenTelemetry collector pipelines involve tail sampling (keeping only interesting traces), custom processors (enriching or filtering telemetry), and multi-destination routing (sending different signals to different backends).
SLO-driven development represents the paradigm shift from availability metrics to business outcomes, as explored in our analysis of essential cloud skills for 2025. You define Service Level Indicators, set error budgets, and create burn rate alerts that trigger at the right moment. Cross-domain observability means bridging infrastructure monitoring (Prometheus) with application performance monitoring (Datadog, Dynatrace) with security information (SIEM integration).
Programming skills become critical, particularly Go. Prometheus, Grafana, OpenTelemetry Collector, and most CNCF observability projects are written in Go. You need to read their source code, contribute bug fixes, and build custom exporters. Python remains valuable for data analysis and tooling automation.
Financial services organisations (Citi, Barclays, Macquarie), large FinTechs (Wise, Monzo), and technology companies (Apple, Google) hire at this level for £90K-£130K. These roles often require 5-8 years of total infrastructure experience with 2-3 years focused specifically on observability.
Staff/Principal Mastery (£130K-£170K+): Organisational Transformation
At staff and principal levels, technical depth remains essential but organisational impact defines your value. You evaluate vendors (Datadog versus Dynatrace versus New Relic) with TCO analysis spanning multi-year contracts. You design observability data strategies that balance telemetry fidelity against storage costs, often making decisions that save or spend hundreds of thousands of pounds annually.
Integration with security teams (SIEM correlation), FinOps practices (cost anomaly detection), and compliance frameworks (audit logging, regulatory reporting) positions observability as strategic infrastructure rather than operational tooling. You lead cultural transformation, moving engineering organisations from “monitoring” (did this break?) to “observability” (why did this behave unexpectedly?).
These roles exist at major banks, government agencies (GDS allocated £7.2 million for observability tooling), and technology companies operating at massive scale. Compensation ranges from £130K to £170K+, with total packages at Grafana Labs, Datadog, and similar vendors reaching £150K-£200K when including equity.
Business Skills That Separate Good Engineers from Platform Leaders
Technical expertise opens the door to senior observability roles, but business acumen determines who progresses to staff and principal levels.
Executive Communication and Business Case Development
Platform engineers must translate technical observability capabilities into business outcomes that executives understand. When proposing a £500K Datadog contract versus a self-hosted Prometheus stack, CFOs and CTOs need ROI analysis, not feature comparisons. You quantify observability’s impact through reduced MTTR (Mean Time To Recovery), prevented outages (each costing £50K-£2M per hour according to New Relic’s 2025 survey), and accelerated feature delivery. Our guide on FinOps evolution explores how to frame technical investments through financial impact, a skill that directly applies to observability platform proposals.
Writing business cases requires understanding Total Cost of Ownership beyond licensing. A £300K Dynatrace contract might seem expensive compared to free Prometheus, but calculating the engineering time saved (£80K-£100K fully loaded cost per engineer), reduced outage frequency, and faster incident resolution often favours commercial platforms at enterprise scale. Conversely, demonstrating that a Prometheus/Grafana/Loki stack costs £150K in engineering time but provides equivalent capabilities positions you to challenge vendor premiums.
Presentation skills matter increasingly as you progress. Board-level presentations require different framing than engineering demos. Executives want three-slide decks with business impact, risks, and recommendations. Engineering teams want architecture diagrams and implementation details. Adapting your communication to audience context separates engineers who advance from those who stall.
Strategic Thinking and Organisational Influence
Senior observability roles operate at the intersection of infrastructure, security, and development teams. Building observability platforms requires influencing teams you don’t control, negotiating standards across departments, and navigating organisational politics. When development teams resist adding tracing instrumentation, you need both technical justification (this reduces debugging time by 60%) and relationship capital built through prior successful collaborations.
Multi-year roadmap planning positions observability investments strategically rather than tactically. If your organisation is migrating from EC2 to Kubernetes, what observability changes does that necessitate? If DORA regulations require specific audit logging, how does your platform accommodate that? Anticipating these shifts and proposing solutions before crises emerge demonstrates strategic leadership.
Vendor relationship management becomes significant when you’re spending £250K+ annually. Understanding contract negotiation (volume discounts, multi-year commitments, data retention tiers) and maintaining multiple vendor relationships creates optionality. When Datadog raises prices 30%, having evaluated and architected fallback options (Grafana Cloud, self-hosted) provides negotiating leverage.
Team Leadership Without Direct Reports
Staff and principal engineers lead through influence rather than authority. You mentor junior observability engineers, establish best practices through documentation and reference implementations, and champion observability adoption across the organisation. This differs from people management (performance reviews, hiring, budget) but demands equally developed leadership skills.
Building communities of practice around observability creates multiplicative impact. Running internal guilds, hosting lunch-and-learns, and creating self-service onboarding documentation scales your expertise across hundreds of engineers. These contributions become visible during promotion cycles and position you as an organisational leader even without direct reports.
The Observability Career Roadmap: £60K to £150K in 4-6 Years
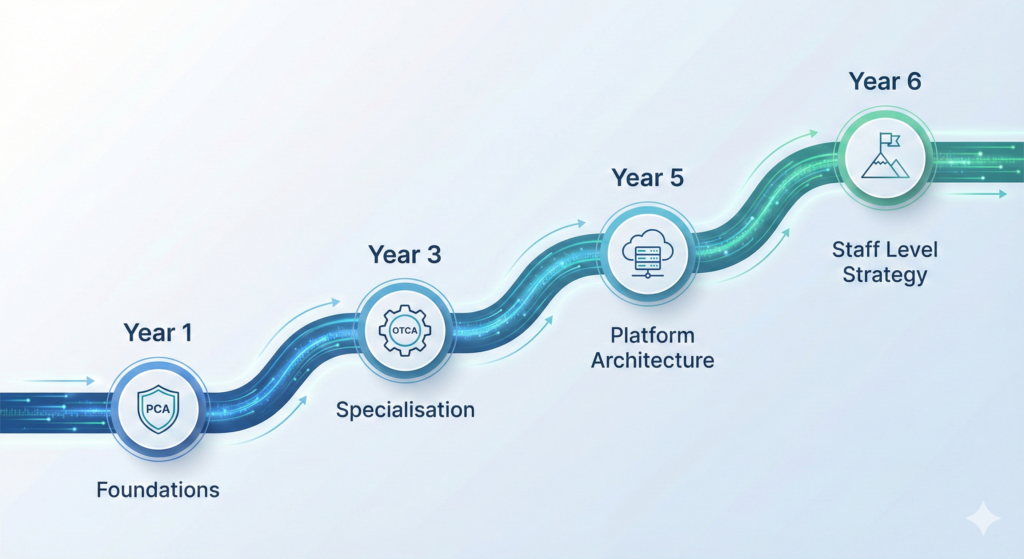
The timeline from mid-level cloud engineer to staff-level observability specialist is compressed compared to traditional infrastructure paths. Four to six years of focused development, strategic skill acquisition, and deliberate career positioning can take you from £60K to £150K+. Here’s the realistic progression.
Year 1: Foundation Building (Current: £50K-£70K → Target: £65K-£80K)
Begin with comprehensive Prometheus and Grafana mastery. Deploy a home lab running the complete Grafana LGTM stack (Loki, Grafana, Tempo, Mimir, Prometheus) on Docker Compose or minikube. Instrument a sample application (FastAPI, Go HTTP server, or Node.js service) with OpenTelemetry SDK, exporting traces to Tempo and metrics to Prometheus. Build Grafana dashboards that correlate metrics with traces, demonstrating RED metrics (Rate, Errors, Duration) for every endpoint.
Earn the Prometheus Certified Associate (PCA) certification (£250) within six months. The certification validates PromQL proficiency and Prometheus architecture understanding, providing credibility during job applications. Contribute to open-source projects by documenting implementation patterns, answering questions in CNCF Slack channels, or fixing “good first issue” bugs in Grafana or Prometheus repositories.
Target a mid-level role explicitly mentioning observability or monitoring responsibilities. Regional companies, consultancies, and scale-ups hiring DevOps engineers often need observability capabilities even if it’s not the job title. Salary progression from £60K to £75K is achievable through this positioning shift.
Years 2-3: Specialisation and Depth (Current: £65K-£80K → Target: £85K-£110K)
Deepen OpenTelemetry expertise by earning the OpenTelemetry Certified Associate (OTCA, £250) and deploying production-scale OTel collectors with advanced configurations (tail sampling, attribute processors, multi-exporter pipelines). Follow the guidance in our piece on moving from certification to practical expertise, focusing on portfolio projects that demonstrate real-world capability rather than toy implementations.
Learn Go by reading the Prometheus, Grafana, and OTel Collector codebases. Build a custom Prometheus exporter for a unique data source (a proprietary API, a legacy monitoring system, or internal tooling). Contributing Go code to CNCF projects signals senior-level capability and opens networking opportunities.
Add Kubernetes certification (CKA, £395) to validate container orchestration expertise, since most observability roles require Kubernetes proficiency. The parallel with Kubernetes career progression demonstrates how complementary specialisations compound value.
Target senior observability engineer roles at FinTechs, financial services, or technology companies operating distributed systems. Job titles include Senior Observability Engineer, Senior SRE (Observability), or Platform Engineer (Monitoring). Compensation at this level reaches £85K-£110K, with London roles and FinTech companies at the higher end.
Years 4-5: Platform Architecture (Current: £85K-£110K → Target: £120K-£140K)
Design and implement organisation-wide observability platforms. This means deploying highly available, multi-cluster Prometheus with Thanos or Mimir, establishing OpenTelemetry standards across engineering teams, and building self-service onboarding for development teams. Document decision frameworks for when to use which telemetry type, how to design effective dashboards, and how to set meaningful SLOs.
Develop business case and cost optimisation expertise. Observability platforms often represent £200K-£1M+ annual spend between tooling licenses, infrastructure costs, and engineering time. Quantifying ROI through reduced incident frequency, faster mean time to recovery, and prevented outages positions you as business-aligned rather than purely technical.
Build a public portfolio through blog posts, conference talks, or detailed GitHub projects. Document your observability platform architecture, share lessons learned from production incidents, or publish open-source tooling. Visibility in the observability community directly leads to senior opportunities.
Target staff-level roles or senior positions at larger organisations. Financial services firms (Citi, Barclays, LSEG), major technology companies (Apple, Google, Microsoft), and government agencies (GDS, HMRC) hire at this level for £120K-£140K. Contract opportunities exist at £650-£900 per day (£169K-£234K annualized).
Year 6: Staff-Level Positioning (Current: £120K-£140K → Target: £150K-£170K+)
At staff level, your impact extends beyond technical implementation to organisational strategy. You define observability roadmaps spanning multiple years, influence architectural decisions across the company, and represent observability interests in executive planning. Publishing thought leadership (conference talks, blog posts, open-source projects) establishes industry credibility that compounds career opportunities.
Staff and principal roles exist at every major financial institution, technology company, and mature scale-up. Compensation reaches £150K-£170K base, often with significant bonuses or equity at technology vendors like Grafana Labs, Datadog, or cloud providers.
Implementation Strategy: Actions to Take This Month

Theoretical career planning fails without concrete execution. Here’s the tactical implementation strategy broken into immediate actions, three-month goals, and annual milestones.
This Week: Immediate Actions
Deploy a home lab observability stack using Docker Compose. Use the official Grafana LGTM tutorial or the OpenTelemetry demo application (Astronomy Shop). Allocate four hours over the weekend. The goal isn’t perfection but hands-on exposure to Prometheus, Grafana, Loki, Tempo, and OpenTelemetry collector working together.
Create a GitHub repository documenting your learning. Include configuration files, a README explaining what you’ve deployed, and a journal of challenges encountered and solutions found. This repository becomes the foundation of your portfolio.
Join CNCF Slack and specifically the #prometheus, #opentelemetry, and #grafana channels. Read the discussions daily for two weeks to understand the problems practitioners face and the solutions they propose.
Next 90 Days: Skill Development and Certification
Register for and pass the Prometheus Certified Associate (PCA, £250). Use the Linux Foundation’s official training or YouTube tutorials. Block six hours weekly for study, focusing on PromQL and Prometheus architecture. The exam is approximately 4/10 difficulty but requires solid fundamentals.
Instrument a real application with OpenTelemetry. If you have a side project, add OTel SDK instrumentation. If not, fork an open-source web application and add tracing. The goal is understanding spans, attributes, and trace context propagation through practical implementation.
Attend local meetups or online webinars about observability. Grafana Labs, Datadog, and New Relic regularly host free training. CNCF hosts virtual meetups globally. Networking builds relationships that lead to job opportunities and provides insight into how organisations implement observability at scale.
This Year: Portfolio, Contribution, and Career Positioning
Complete a significant portfolio project demonstrating senior-level capability. Options include deploying the OpenTelemetry demo with custom instrumentation, building an SLO tracking dashboard with error budget calculations, or creating a custom Prometheus exporter in Go. Document this thoroughly on GitHub and blog about the implementation.
Make at least five meaningful open-source contributions. “Meaningful” means bug fixes, documentation improvements, or feature additions rather than trivial typo corrections. Target Prometheus, Grafana, OpenTelemetry, or related CNCF projects. Include these contributions prominently on your CV and LinkedIn.
Update your CV and LinkedIn profile with observability-focused positioning. Lead with observability skills and projects rather than generic DevOps capabilities. Actively apply to 10-15 observability-specific roles even if you don’t meet every requirement. The application process itself provides market intelligence about what skills are valued.
Navigating continuous learning without burnout becomes critical as you layer observability expertise onto existing responsibilities. The 70-20-10 framework (70% hands-on practice, 20% learning from others, 10% formal training) prevents the overwhelm that stalls many engineers’ specialisation attempts.
Measuring Success: Career Progress Indicators
Tracking career advancement requires quantifiable metrics beyond just salary. Here’s how to measure whether your observability specialisation is progressing effectively.
Technical Proficiency Metrics
Certifications completed provide objective markers. Target: PCA within six months, OTCA within 12 months, CKA within 18 months. Each validates specific capabilities and improves application success rates.
GitHub activity demonstrates practical expertise. Aim for 50+ contributions annually to observability-related projects, whether through code, documentation, or issue triage. A complete portfolio project (fully instrumented application or custom exporter) signals senior-level capability.
Technical blog posts or conference talks measure your ability to communicate expertise. Publishing two to four blog posts annually on observability topics (implementation guides, lessons learned, tool comparisons) builds industry visibility and establishes thought leadership.
Career Advancement Indicators
Job offer quality improves measurably with focused specialisation. Track recruiter inquiries, interview requests, and offer amounts. Observability specialists receive 2-3x more recruiter contacts than generalist DevOps engineers once LinkedIn profiles are optimised. Interview-to-offer ratios improve as your expertise becomes scarce and valuable.
Salary progression should show clear momentum. Target 10-15% annual increases when changing roles, with progression from £60K to £90K achievable within two to three years through strategic positioning. Salary offers above £100K indicate you’ve reached senior level, while £130K+ suggests staff-level positioning.
Internal recognition within current organisations provides validation. Observability specialists often become go-to experts for incident response, monitoring design, and tooling evaluation. Being pulled into architectural discussions across teams signals growing influence.
Market Value Indicators
Contract rate offers (if you pursue contract work) crystallise market value. Observability specialists command £500-£650 per day at mid-senior level, rising to £750-£900 for staff-level expertise. These rates exceed general DevOps contractors (£450-£550) by 20-30%.
LinkedIn connections from observability professionals, CNCF community participation (attending SIG meetings, contributing to working groups), and invitations to speak at meetups indicate growing industry recognition. These networks directly generate opportunities.
Common Career Pitfalls in Observability Specialisation
Several predictable mistakes stall engineers attempting to specialise in observability. Awareness helps you avoid them.
Over-indexing on certifications versus practical experience. Earning PCA, OTCA, CKA, and every vendor certification creates a credential-heavy CV but doesn’t demonstrate you can architect observability platforms. Employers hire based on portfolio projects and production experience. One complex GitHub project showing OTel implementation across microservices matters more than three certifications. Invest more time building than studying.
Staying in comfort zones too long. Many engineers deploy Prometheus and Grafana, declare themselves “observability engineers,” and stagnate. Advancement requires continuous expansion into distributed tracing, OpenTelemetry, advanced PromQL, Go programming, and SLO frameworks. Set quarterly learning goals and hold yourself accountable.
Neglecting business communication skills. Technical depth alone caps your progression at senior engineer. Staff and principal roles demand business case development, executive communication, and cost-benefit analysis. Practice translating technical decisions into business outcomes. “This monitoring solution will cost £200K annually” matters less than “This monitoring solution will prevent £2M in downtime costs and accelerate feature delivery by 20%.”
Poor networking and visibility. The best opportunities come through professional networks, not job boards. Yet most engineers avoid communities, meetups, and open-source contribution. Dedicate four hours monthly to community participation. Join CNCF Slack, attend virtual meetups, answer questions, and build relationships. Networking compounds over years.
Not documenting achievements. You won’t remember the observability platform you built, the outages you prevented, or the dashboards you designed when updating your CV two years later. Maintain a career journal documenting projects, outcomes, and lessons learned. Update it monthly. This documentation becomes interview stories and CV bullet points.
Avoiding leadership opportunities. Staff-level roles require leadership even without direct reports. Turning down opportunities to mentor junior engineers, lead working groups, or present technical topics signals lack of leadership development. Accept these opportunities even when uncomfortable. Leadership skills develop through practice, not study.
ROI Analysis: Investment Required and Returns Expected
Transitioning from generalist to observability specialist requires both time and financial investment. Understanding the return helps justify the commitment.
Time Investment
Home lab deployment and experimentation demands 4-6 hours weekly, primarily evenings and weekends. Over one year, this totals 200-300 hours. At your current hourly rate (£60K salary = £29/hour), this represents £5,800-£8,700 in opportunity cost. However, front-loading skill development accelerates salary progression, compressing what might take five years of passive learning into two years of focused effort.
Certification study requires 40-60 hours per certification (PCA, OTCA, CKA), totaling 120-180 hours for the three most valuable credentials. Portfolio projects demand 60-100 hours for a production-quality GitHub showcase. Networking and community participation absorbs 4-8 hours monthly (50-100 hours annually). Total first-year time investment: 350-500 hours.
Financial Investment
Certification costs total £895 (PCA £250 + OTCA £250 + CKA £395). Budget an additional £200-£300 for training courses, books, or cloud infrastructure for home labs. Total financial outlay: £1,100-£1,200 in year one.
Expected Returns
Salary progression from £60K to £75K within 12-18 months through repositioning represents £15,000 annual increase. After tax (assuming 40% effective rate), this nets £9,000 annually. Payback period on £1,200 investment: under two months of the new salary.
Progression from £75K to £100K within 24-36 months adds another £25,000 annually (£15,000 after tax). Reaching £130K at senior level (48-60 months) represents £70,000 annual increase over the starting £60K baseline, or £42,000 after tax. Staff roles at £150K+ represent £90,000+ premiums over the £60K starting point.
Over a five-year career trajectory, specialising in observability could generate £150,000-£200,000 in additional after-tax earnings compared to remaining a generalist. The £1,200 investment and 500 hours of focused development in year one produce a 125-167x financial return over five years. Few career investments offer comparable ROI.
Next Steps: Actions to Take This Week
Career transformation begins with immediate action, not prolonged planning. Here’s what to start this week.
First, audit your current technical capabilities. Do you understand the three pillars (metrics, logs, traces) and their relationships? Can you write moderately complex PromQL queries? Have you instrumented an application with any observability SDK? Honest self-assessment reveals your starting point.
Second, deploy a basic observability stack. Use Docker Compose to run Prometheus, Grafana, and a sample application with instrumentation. Spend three hours Saturday morning following any tutorial. The goal is getting hands-on experience, not perfection.
Third, optimise your LinkedIn profile with observability keywords. Change your headline to include “Observability,” “Prometheus,” “OpenTelemetry,” or “Platform Engineering.” Add these skills to your profile. This immediately increases recruiter visibility for observability roles.
Fourth, join CNCF Slack and introduce yourself in the #prometheus and #opentelemetry channels. State your experience level and what you’re learning. The community is welcoming to newcomers who engage authentically.
Fifth, identify two to three specific observability roles you’d like to reach in 12-24 months. Find actual job postings and analyse the requirements. What skills appear consistently? What certifications do they mention? This research guides your learning priorities.
The observability salary premium exists because supply lags demand. Organisations need specialists now. Engineers who build expertise over the next 12-18 months will be positioned to fill the senior and staff roles that companies are struggling to hire for today. Start this week.
Useful Links
- IT Jobs Watch – Observability Trends: Real-time UK salary data and job demand trends
- CNCF Prometheus Certified Associate: Official certification (£250)
- CNCF OpenTelemetry Certified Associate: Latest observability certification (£250)
- OpenTelemetry Demo (Astronomy Shop): Production-ready reference implementation
- Grafana LGTM Stack Tutorials: Official documentation for Grafana, Loki, Tempo, Mimir
- Prometheus Documentation: Complete technical reference and best practices
- CNCF Slack (Observability Channels): Join #prometheus, #opentelemetry, #grafana communities
- Datadog Learning Centre: Free courses and certifications
- Reed Tech Jobs – Observability: UK-specific job listings






