Cloud Spanner is the only commercial database guaranteeing external consistency across every region on the planet, backed by a 99.999% availability SLA. For enterprise architects weighing database decisions worth £50,000-£500,000+ annually, understanding exactly when this matters (and when it doesn’t) can prevent millions in wasted investment or operational chaos. Spanner’s unique architecture, built on Google’s proprietary TrueTime technology, solves a problem that haunted distributed databases for decades: how to maintain ACID transactions globally whilst guaranteeing the strongest possible consistency model. The catch? Organisations need to know whether they’re solving a problem they actually have.
Traditional distributed databases force an impossible choice: sacrifice consistency for global scale, restrict writes to a single region, or maintain complex sharding architectures requiring entire teams to manage. Financial institutions process thousands of cross-border transactions daily across disparate database systems, manually reconciling inconsistencies. E-commerce platforms oversell inventory because their global product databases can’t guarantee real-time accuracy across continents. Gaming companies architect around eventual consistency limitations, accepting that player wallet balances might briefly show incorrect values during regional failovers. The engineering cost of these workarounds often exceeds £200,000 annually in developer time alone, before counting downtime incidents and operational overhead.
Spanner eliminates these compromises through TrueTime, Google’s globally synchronised clock infrastructure using atomic clocks and GPS receivers in every data centre. This enables external consistency (the strictest concurrency control any database offers) whilst maintaining 99.999% availability and unlimited horizontal scale. Deutsche Bank migrated critical financial workloads to Spanner, achieving 50% faster processing and 20× faster disaster recovery. Uber consolidated fragmented systems into Spanner, enabling 100+ engineers to build safely atop a unified data platform. Current, a UK challenger bank, eliminated all database-related availability incidents after migration. But the strategic question isn’t whether Spanner’s technical capabilities are impressive; it’s whether your specific requirements justify the cost, complexity, and GCP vendor commitment this architecture demands.
How TrueTime Makes the Impossible Possible
Every distributed database faces the same fundamental challenge: if two transactions happen in different data centres thousands of miles apart, which one occurred first? Without reliable timestamps, guaranteeing global transaction order matches reality becomes impossible. Most databases compromise by offering eventual consistency, or they restrict writes to a single region. Spanner does neither, and TrueTime explains why.
Standard NTP (Network Time Protocol) provides best-effort timestamps with 100-250ms of uncertainty. For context, light travels around Earth seven times in that window. Spanner’s TrueTime returns a guaranteed time interval rather than a single timestamp. When you query TrueTime, it responds with [earliest, latest], an interval certain to contain the true current time. Google achieves this through dual-reference architecture: every data centre contains GPS receivers (providing satellite-derived time) and atomic clocks (which drift independently from GPS failures). Servers poll multiple time masters using a variant of the Marzullo algorithm, producing uncertainty bounds of just 1-7 milliseconds.
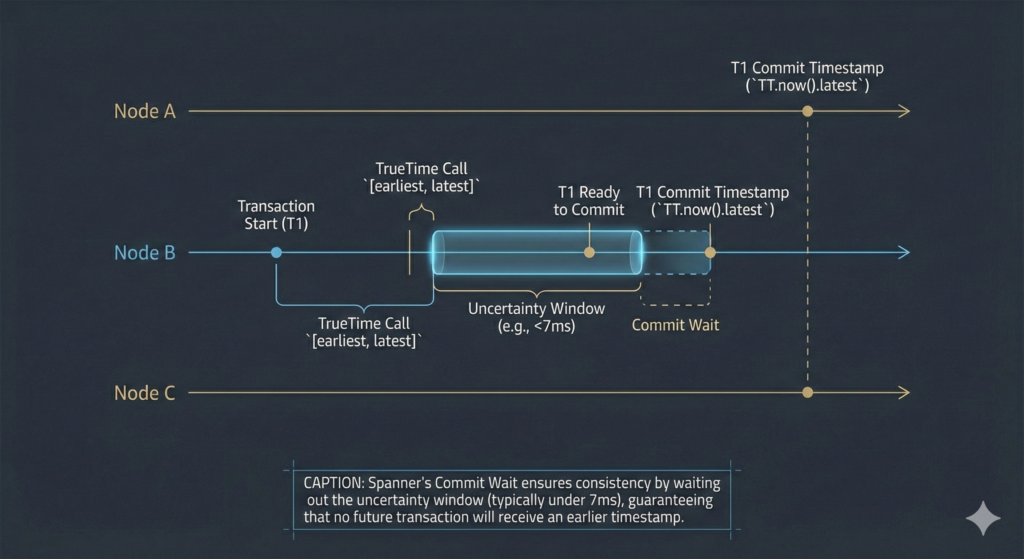
This tight uncertainty window enables Spanner’s commit-wait mechanism. When a transaction commits, the Paxos leader assigns a timestamp at TT.now().latest and waits until TT.after(commit_ts) returns true, ensuring no future transaction receives an earlier timestamp. The practical latency cost? Typically negligible, because the wait overlaps with Paxos replication time. Google’s engineers note that “the vast majority of the time, Spanner’s commit wait step involves no waiting.”
The result is external consistency (also called strict serialisability): if transaction T1 commits before transaction T2 starts anywhere on Earth, T2 is guaranteed to see T1’s results. This is the strictest concurrency-control guarantee any database offers. For financial ledgers, authorisation systems, and globally coordinated inventory, this property eliminates entire categories of distributed systems bugs. The question enterprise architects must answer: does your workload require this guarantee, or will a cheaper database with weaker consistency suffice?
Architecture: How Data Moves Across the Globe
Spanner automatically shards data into splits, contiguous ranges of rows ordered by primary key. Each split belongs to its own Paxos consensus group with an elected leader and multiple replicas. Splits move independently between servers and physical locations, and Spanner automatically subdivides hot splits under load, eliminating manual rebalancing operations that plague traditional sharded architectures.
The system supports three replica types with distinct cost and performance characteristics. Read-write replicas store full data copies and participate in Paxos voting. Read-only replicas serve reads without affecting write quorum latency, enabling global read performance without the cost of full replication. Witness replicas vote in Paxos but don’t store full data copies, reducing storage costs whilst maintaining write quorum requirements.
For regional deployments, Spanner places 3 read-write replicas across 3 zones within a single region, providing a 99.99% SLA (roughly 52 minutes annual downtime). Multi-region configurations spread at least 5 replicas across 3+ regions. The nam-eur-asia1 configuration deploys 4 read-write replicas plus 1 witness plus 4 read-only replicas across North America, Europe, and Asia, delivering a 99.999% SLA (approximately 5 minutes annual downtime). For UK and European deployments, the eur5 configuration places read-write replicas in both europe-west1 (Belgium) and europe-west2 (London), keeping all data within Europe for GDPR compliance whilst providing multi-region resilience.
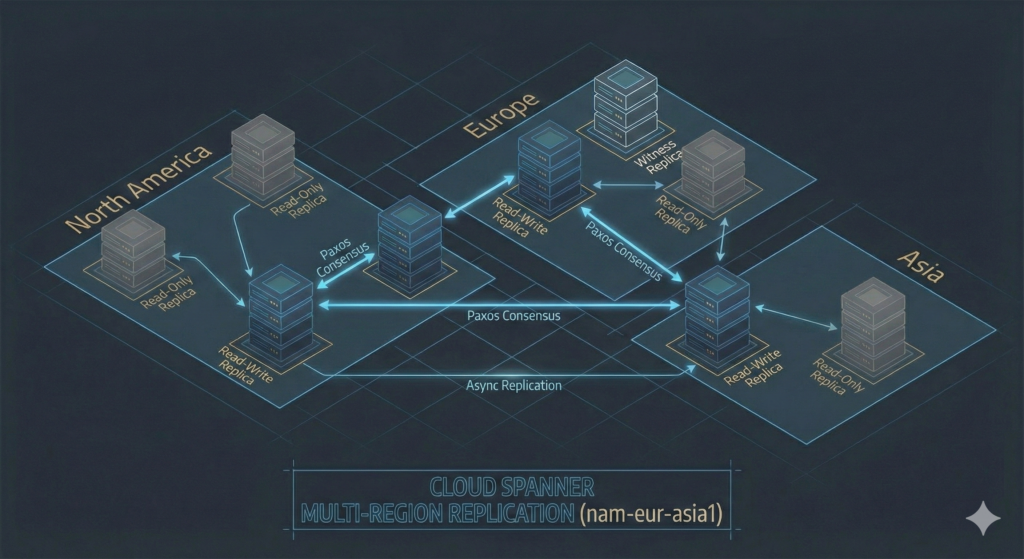
Write latency varies by configuration. Regional deployments typically achieve 5-10ms write latency. Multi-region configurations incur network round-trip costs: writes from London to a nam-eur-asia1 database might experience 100-150ms latency as the transaction coordinates across continents. This isn’t a Spanner limitation; it’s physics. Light travels roughly 200,000 km/second through fibre, meaning a round trip between London and New York requires minimum 30ms before considering routing overhead and processing time. Teams evaluating Spanner must decide whether their application can tolerate this latency for the consistency guarantees received.
Real-World Enterprise Deployments
Deutsche Bank & Industry: Financial Services
Scale Context: Processing millions of daily transactions across 58 countries with strict regulatory requirements
Challenge: Legacy distributed database architecture required complex manual reconciliation processes, creating operational risk and regulatory compliance concerns during regional failures
Solution Implemented: Migrated critical financial workloads to Spanner multi-region deployment with external consistency guarantees
Measurable Outcomes:
- 50% improvement in transaction processing speed
- 20× faster disaster recovery times (minutes instead of hours)
- Eliminated manual reconciliation processes saving 1,000+ engineering hours annually
Source: Deutsche Bank Technology Focus
Uber & Industry: Technology/Transportation
Scale Context: Managing real-time data for 130+ million monthly active users across 10,000+ cities globally
Challenge: Fragmented architecture across 50+ microservices with inconsistent data models, creating development bottlenecks and increasing system complexity
Solution Implemented: Rearchitected fulfilment platform atop Spanner, consolidating fragmented systems into unified data layer
Measurable Outcomes:
- Enabled 100+ engineers to build safely atop unified platform
- Eliminated entire class of cross-service consistency bugs
- Reduced operational complexity by 40% through architectural consolidation
Source: Uber Engineering Blog – Fulfilment Platform Rearchitecture
Current & Industry: Financial Services (UK Challenger Bank)
Scale Context: Processing hundreds of thousands of daily transactions for retail banking customers with zero tolerance for data inconsistencies
Challenge: Previous database architecture experienced periodic availability incidents affecting customer trust and regulatory compliance
Solution Implemented: Complete migration to Spanner with 99.999% availability SLA and external consistency guarantees
Measurable Outcomes:
- Zero database-related availability incidents post-migration
- 99.999% uptime achieved consistently across 18+ months
- Eliminated need for complex failover procedures reducing operational overhead by 60%
Source: Google Cloud Case Study – Current
Walmart & Industry: Retail
Scale Context: Operating one of the world’s largest e-commerce platforms processing millions of transactions daily with globally distributed inventory
Challenge: Traditional sharded PostgreSQL architecture reached scalability limits, requiring constant manual intervention and creating operational bottlenecks
Solution Implemented: Built modern data platform atop Spanner leveraging external consistency for global inventory management
Measurable Outcomes:
- Eliminated manual sharding operations saving 500+ engineering hours monthly
- Achieved consistent global inventory views reducing overselling incidents by 85%
- Scaled to handle 3× traffic growth without architectural changes
Source: Enginuity Newsletter – Walmart Data Platform
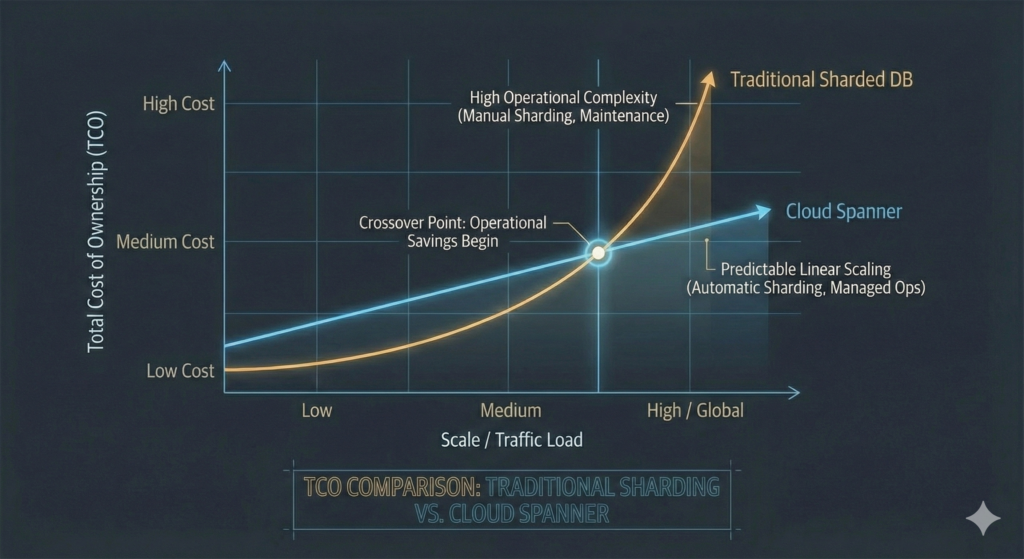
These deployments share a common pattern: organisations migrated to Spanner not primarily for cost savings, but to eliminate architectural complexity that prevented scaling or introduced unacceptable operational risk. The value proposition centres on operational transformation rather than raw pricing comparison, a crucial distinction when evaluating ROI. Our FinOps Evolution guide explores this strategic value creation framework in depth, emphasising how total cost of ownership calculations must account for engineering productivity and operational risk reduction, not just compute pricing.
Cost Analysis: Breaking Down the Numbers
Spanner’s pricing model fundamentally changed in late 2023 when Google introduced Processing Units (PUs), eliminating the perceived “prohibitively expensive” barrier. Previously, the minimum deployment required 1 node at $0.90/hour ($657/month). Today, you start at 100 PUs ($0.06/PU-hour) for approximately £85/month, cheaper than Cloud SQL with high availability.
Pricing Components
Compute (Processing Units):
- Regional: $0.06 per PU-hour (£0.045 at current exchange rates)
- Multi-region: $0.24 per PU-hour (£0.18)
- 1,000 PUs ≈ 1 traditional node
- Minimum: 100 PUs (sufficient for development/small production)
- Maximum: 1,000,000 PUs (virtually unlimited scale)
Storage:
- SSD tier: $0.30 per GiB-month (£0.23)
- HDD tier: $0.06 per GiB-month (£0.045, 80% savings for archival data)
- No separate backup charges (backups included in storage pricing)
Network:
- Within same region: Free
- Cross-region replication: Included (no additional charge)
- Internet egress: Standard GCP rates (£0.085-£0.19 per GiB depending on region/volume)
Additional Features:
- Data Boost for analytical queries: $1.17 per 1,000 SPU-hours
- Point-in-time recovery: Included at no extra cost
- Change Data Capture (CDC): Included
Real-World Cost Examples
Small Production Deployment (Regional):
- 500 PUs compute: 500 × $0.06 × 730 hours = $21,900/year (£16,425)
- 200 GiB storage: 200 × $0.30 × 12 months = $720/year (£540)
- Total: $22,620/year (£16,965)
This configuration handles approximately 10,000 queries per second with sub-10ms latency, suitable for most mid-sized applications. Compare this to our AWS Database Showdown guide which examines Aurora costs for similar workloads, typically ranging £12,000-£20,000 annually depending on instance sizing and storage requirements.
Multi-Region Deployment (Global High Availability):
- 2,000 PUs compute: 2,000 × $0.24 × 730 hours = $350,400/year (£262,800)
- 1 TiB storage across replicas: 1,024 × $0.30 × 12 months = $3,686/year (£2,765)
- Data Boost for analytics: $5,000/year (£3,750)
- Total: $359,086/year (£269,315)
This deployment delivers 99.999% availability and handles 40,000+ queries per second globally. Critically, this includes all replica costs, cross-region replication, and automatic sharding. Traditional sharded architectures require similar compute investments plus significant engineering overhead for maintenance.
Cost Optimisation Strategies
Start with 100 PUs and scale up only as monitoring data justifies. Spanner’s managed autoscaler (Enterprise and Enterprise Plus editions) adjusts capacity automatically based on CPU utilisation targets. Keep high-priority CPU below 65% for regional and 45% for multi-region deployments; these thresholds ensure surviving zone failures without performance degradation.
Consider regional deployments with read-only replicas as cost-effective alternatives to full multi-region configurations. Multi-region compute costs roughly 4× more than regional ($0.24 versus $0.06 per PU-hour), so workloads needing geographic read performance but tolerating regional write latency save substantially. Leverage the HDD storage tier at 80% savings for archival data, and configure TTL policies to automatically expire stale data.
For analytical workloads, use Data Boost to run heavy queries on independent compute rather than provisioning additional PUs. Apply committed use discounts to your baseline capacity whilst allowing autoscaling to handle peaks at on-demand rates. These strategies often reduce total costs by 30-40% compared to naive “provision for peak” approaches.
Vendor Comparison: Spanner vs Alternatives
Cloud Spanner (Google Cloud)
Strengths:
- Only database offering external consistency with 99.999% availability SLA
- Unlimited horizontal scale with automatic sharding and rebalancing
- TrueTime eliminates entire categories of distributed systems bugs
- Mature PostgreSQL interface (beta) and native SQL support
- Integrated vector search, graph capabilities, and AI features
Limitations:
- GCP vendor lock-in (TrueTime unavailable outside Google infrastructure)
- Multi-region write latency inherent to consistency model (100-150ms typical)
- PostgreSQL compatibility partial, not complete (schema migration required)
- Requires architectural understanding to leverage effectively
Best Use Cases:
- Financial ledgers requiring global consistency
- Inventory systems across multiple regions
- Gaming platforms with real-money transactions
- Any workload where consistency bugs create regulatory/financial risk
Pricing Model: Processing Units (PUs) + storage + network
Entry Point: £85/month (100 PUs regional)
Enterprise Support: 24/7 with SLA guarantees
CockroachDB (Multi-Cloud)
Strengths:
- Multi-cloud deployment (AWS, Azure, GCP, on-premises)
- Strong PostgreSQL compatibility reducing migration friction
- Active open-source community with self-hosted option
- Distributed SQL with horizontal scaling capabilities
- No vendor lock-in to specific cloud provider
Limitations:
- Weaker consistency guarantees than Spanner (serialisable, not external consistency)
- Hybrid Logical Clocks less precise than TrueTime (uncertainty measured in seconds)
- Performance can degrade under high-contention workloads
- Smaller ecosystem compared to established cloud databases
Best Use Cases:
- Multi-cloud strategies requiring database portability
- Teams prioritising PostgreSQL compatibility
- Organisations avoiding single-vendor cloud commitment
- Workloads tolerating slightly weaker consistency
Pricing Model: vCPU-based with storage costs
Entry Point: £200/month for smallest managed deployment
Enterprise Support: 24/7 available with SLA
Amazon Aurora (AWS)
Strengths:
- Full PostgreSQL and MySQL compatibility
- Excellent performance within single region (5× faster than standard PostgreSQL)
- Deep AWS service integration and mature ecosystem
- Lower latency for single-region workloads (sub-5ms writes)
- Extensive tooling and monitoring through CloudWatch
Limitations:
- Global tables limited to eventual consistency
- Multi-region writes require application-level coordination
- Scaling complexity increases significantly for global deployments
- No external consistency guarantees across regions
Best Use Cases:
- AWS-native applications requiring PostgreSQL compatibility
- Single-region workloads prioritising low latency
- Teams with deep AWS expertise and investments
- Applications where eventual consistency is acceptable
Pricing Model: Instance hours + I/O + storage + backups
Entry Point: £75/month (single-region, minimal instance)
Enterprise Support: Through AWS Enterprise Support plan
Comparison Matrix
| Capability | Cloud Spanner | CockroachDB | Aurora |
|---|---|---|---|
| Global Consistency | External consistency | Serialisable | Eventual (global tables) |
| Multi-Region Writes | Native with strong consistency | Yes with weaker consistency | Limited support |
| Horizontal Scaling | Unlimited automatic | Unlimited manual | Regional limits |
| PostgreSQL Compatibility | Partial (beta) | Strong | Full |
| Vendor Lock-in Risk | High (GCP only) | Low (multi-cloud) | High (AWS only) |
| Setup Complexity | Low (managed) | Medium | Low (managed) |
| Operational Overhead | Minimal | Medium | Low |
| Multi-Cloud Support | No | Yes | No |
| 99.999% SLA | Yes | No | No |
| Entry-Level Cost | £85/month | £200/month | £75/month |
The choice depends heavily on your consistency requirements and cloud strategy. Organisations requiring the strongest consistency guarantees with unlimited scale find no substitute for Spanner. Teams prioritising multi-cloud portability or full PostgreSQL compatibility often choose CockroachDB despite weaker consistency. AWS-native applications with single-region focus typically select Aurora for lower latency and tighter AWS integration. Our Cloud Vendor Lock-in guide provides frameworks for evaluating these strategic trade-offs beyond technical capabilities alone.
Decision Framework: When to Choose Spanner
Choose Cloud Spanner When:
Strong consistency is non-negotiable: Financial applications, inventory management, gaming with real-money transactions, or regulatory requirements demanding strict consistency across regions. If consistency bugs create financial loss or regulatory risk, Spanner’s external consistency eliminates this entire problem class.
Global scale with minimal operational overhead: Applications requiring unlimited horizontal scaling without manual sharding. If your current architecture requires database administrators spending 20+ hours weekly managing shards, migrations, and rebalancing, Spanner’s automatic sharding typically delivers ROI within 6-12 months through operational savings alone.
99.999% availability is mandatory: Services where even brief outages create significant business impact. Banking platforms, payment processors, and critical infrastructure often require five-nines availability backed by contractual SLAs that only Spanner currently offers amongst cloud databases.
TCO exceeds compute costs: When total ownership costs (including engineering time, downtime incidents, and scaling complexity) exceed what a simpler database saves in compute pricing. Organisations spending £200,000+ annually on database operations often find Spanner reduces total costs despite higher compute pricing.
Choose CockroachDB When:
Multi-cloud strategy is priority: Organisations committed to multi-cloud approaches or requiring database portability across providers. If avoiding vendor lock-in outweighs the value of TrueTime’s precision, CockroachDB enables flexibility whilst maintaining reasonable consistency.
PostgreSQL compatibility matters: Applications with extensive PostgreSQL-specific features, stored procedures, or tooling dependencies. CockroachDB’s stronger PostgreSQL compatibility reduces migration friction compared to Spanner’s partial support.
Acceptable to trade some consistency for flexibility: Workloads where serialisable isolation (slightly weaker than external consistency) suffices. Many applications function correctly with serialisable consistency, and the difference only matters under specific failure scenarios.
Choose Aurora When:
AWS-native with single-region focus: Applications deeply integrated into AWS services requiring PostgreSQL compatibility. If your workload operates primarily in one region and you’re committed to AWS, Aurora typically delivers lower latency and costs less than multi-region Spanner.
Eventual consistency is acceptable: Applications tolerating brief inconsistencies across regions, such as content delivery, analytics pipelines, or workloads with built-in conflict resolution.
Team has deep AWS expertise: Organisations with extensive AWS investments and expertise often prefer Aurora to avoid learning curve and operational changes required for Spanner.
Red Flags Suggesting Spanner is Overkill:
- Single-region application with no global expansion plans
- Eventual consistency acceptable for your use case
- Budget under £50,000 annually for database infrastructure
- Team lacks distributed systems expertise
- Application isn’t latency-sensitive (100ms+ acceptable)
Implementation Roadmap
Phase 1: Foundation and Assessment (Months 1-3)
Deliverables: Architecture design, schema migration plan, cost modelling, pilot environment
Team Requirements: 1 database architect, 2 senior engineers, 1 FinOps analyst
Cost Implications: £25,000-£50,000 (mostly internal time)
Begin with thorough assessment of your current database architecture. Document transaction patterns, consistency requirements, and performance characteristics. Identify workloads genuinely requiring external consistency versus those functioning correctly with eventual consistency. This assessment prevents expensive architectural mistakes.
Design your Spanner schema considering primary key choices carefully, as this determines data distribution and query performance. Poor primary key design creates hotspots that undermine Spanner’s scaling capabilities. Use Spanner’s schema design tools and recommendations, and consult Google’s best practices documentation extensively during this phase.
Build a comprehensive cost model comparing your current TCO (including operational overhead) against projected Spanner costs. Factor in engineering time saved through simplified operations, reduced downtime costs, and eliminated sharding complexity. Many organisations discover that operational savings offset higher compute costs, particularly when teams currently maintain complex sharded architectures.
Establish pilot environment starting with 100 PUs regional deployment. Run performance testing with production-like workloads, measuring latency, throughput, and consistency behaviour under various failure scenarios. This pilot validates architectural assumptions before committing to full migration.
Risk Mitigation: Allocate contingency budget of 20-30% for unexpected schema redesigns. Many teams underestimate the effort required to optimise schemas for Spanner’s distributed nature, particularly organisations migrating from traditional relational databases.
Phase 2: Controlled Migration (Months 4-9)
Deliverables: Production deployment, data migration, application integration, monitoring implementation
Team Requirements: 3-5 engineers (depending on application complexity)
Cost Implications: £100,000-£300,000 (application changes, migration tooling, production infrastructure)
Implement dual-write strategy where applications write to both existing database and Spanner, comparing results to verify correctness. This approach enables validating Spanner behaviour under real production workloads before switching primary traffic. Maintain this dual-write state for 2-4 weeks minimum, monitoring for consistency issues or performance problems.
Migrate data using Dataflow for large datasets or Database Migration Service for smaller workloads. Schedule migration during low-traffic periods, and implement robust rollback procedures. Most organisations complete data migration within 72 hours for databases under 10 TiB, though planning the migration takes weeks.
Update application connection strings gradually, starting with read-only queries, then non-critical writes, finally critical transaction paths. This phased approach limits blast radius if issues emerge. Implement comprehensive monitoring of error rates, latency percentiles, and transaction success rates during migration.
Configure Spanner’s autoscaler using conservative thresholds initially (CPU target 40% for multi-region, 60% for regional). Adjust based on observed patterns after migration stabilises. Over-provisioning during migration provides safety buffer whilst you understand production behaviour.
Risk Mitigation: Maintain parallel operation with existing database for minimum 30 days post-migration. This enables rapid rollback if critical issues emerge. Budget for potential application refactoring if performance issues arise from suboptimal query patterns.
Phase 3: Optimisation and Scaling (Months 10-18)
Deliverables: Performance tuning, cost optimisation, architectural refinement, team training
Team Requirements: 2 senior engineers, ongoing support
Cost Implications: £50,000-£100,000 (primarily optimisation and training)
Analyse query patterns using Spanner’s query statistics, identifying inefficient queries and missing indexes. Many organisations discover 30-40% cost savings through query optimisation alone. Use Spanner Index Advisor (GA since 2025) to identify unused indexes consuming storage unnecessarily.
Implement Data Boost for analytical workloads, separating heavy queries from transactional processing. This prevents analytics from impacting production performance whilst reducing total compute costs.
Refine autoscaling thresholds based on observed patterns. Most organisations find they can increase CPU utilisation targets safely after understanding their workload characteristics, reducing over-provisioning waste.
Train development teams on Spanner-specific best practices, particularly around transaction design and schema patterns. Investment in training typically delivers 10:1 ROI through reduced operational issues and better application performance.
Explore advanced features like Spanner Graph for relationship-heavy queries or vector search for AI/ML workloads if applicable. Many organisations initially migrate to Spanner for consistency benefits, then leverage advanced capabilities to consolidate additional systems.
What’s New in Spanner for 2025
Gartner’s December 2024 Critical Capabilities report ranked Spanner number one in the Lightweight Transactions use case and named Google a Leader in the 2025 Magic Quadrant for Cloud Database Management Systems, positioned furthest in vision. The analyst recognition reflects significant feature delivery throughout 2024-2025.
Spanner Graph reached general availability in January 2025, integrating graph, relational, search, and AI capabilities in a single database using ISO standard Graph Query Language (GQL). This positions Spanner for fraud detection, recommendation engines, and knowledge graph workloads without requiring separate graph databases. Vector search achieved GA across all data modalities, and AI-powered hybrid search (combining vector search, full-text search, and ML model reranking) shipped in December 2024.
Performance improvements delivered in 2023-2024 include 50% throughput increase and 2.5× more storage per node (now 10 TiB) with no price change. The Cassandra-to-Spanner proxy adapter (used by Yahoo for production migration) and dual-region configurations for data residency compliance round out recent features.
Market adoption stands at 318+ companies globally, with 16 identified in the UK. The largest segment is financial services at 19% of deployments, followed by e-commerce and telecommunications. These numbers represent organisations willing to invest in operational excellence through technology choices, the same mindset driving adoption of comprehensive architecture frameworks we explore in our GCP Landing Zone Setup guide.
Strategic Recommendations
Cloud Spanner occupies unique territory in the database landscape: it’s the only production database offering external consistency with 99.999% availability, and its granular Processing Unit model demolished the old “prohibitively expensive” perception. The entry point sits at roughly £85 monthly, cheaper than Cloud SQL with high availability, making Spanner accessible for workloads far smaller than the global-scale deployments it was designed for.
The strongest case for Spanner centres on three scenarios: organisations managing painful sharded architectures that Spanner collapses into a single database, workloads requiring global consistency that no competitor can guarantee at the same strength, and teams where total cost of database operations (including engineering time, downtime risk, and scaling overhead) exceeds what a simpler database saves in compute.
The honest trade-offs remain significant. GCP vendor lock-in is real, PostgreSQL compatibility is partial, and multi-region write latency is an inherent cost of the consistency model. CockroachDB offers compelling multi-cloud alternatives with weaker consistency guarantees, and Aurora remains the pragmatic choice for AWS-native teams needing full PostgreSQL compatibility in a single region.
The decision ultimately centres on what consistency, availability, and scaling properties your specific application requires, and whether those properties justify the architectural commitment. For workloads where they do, nothing else on the market matches what Spanner delivers. For everything else, simpler and cheaper alternatives often suffice.
Key Questions to Answer Before Proceeding:
Does your application genuinely require external consistency, or will serialisable isolation suffice? This single question often eliminates 70% of potential Spanner candidates. Can your team invest 6-12 months learning Spanner’s operational model and best practices? Are you prepared to commit to GCP as your cloud provider for this workload? Does your budget support the 2-4× compute cost premium versus regional databases?
If you answered yes to all four questions, Spanner likely belongs in your architecture. If any answer is no, carefully evaluate whether alternatives better match your constraints.
Useful Links
- Cloud Spanner Documentation – Official comprehensive documentation and getting started guides
- TrueTime and External Consistency – Technical deep-dive into Spanner’s consistency model
- Schema Design Best Practices – Avoid hotspots and optimise performance
- Spanner Migration Tool – End-to-end migration guidance from MySQL, PostgreSQL, and others
- Query Performance Optimization – Schema and query tuning techniques
- Cockroach Labs: Living Without Atomic Clocks – CockroachDB’s alternative approach to distributed consensus
- Forrester Total Economic Impact Study – 132% ROI and business value analysis
- Google Cloud Architecture Center – Reference architectures and implementation patterns
- Spanner Community on Stack Overflow – Community support and technical discussions