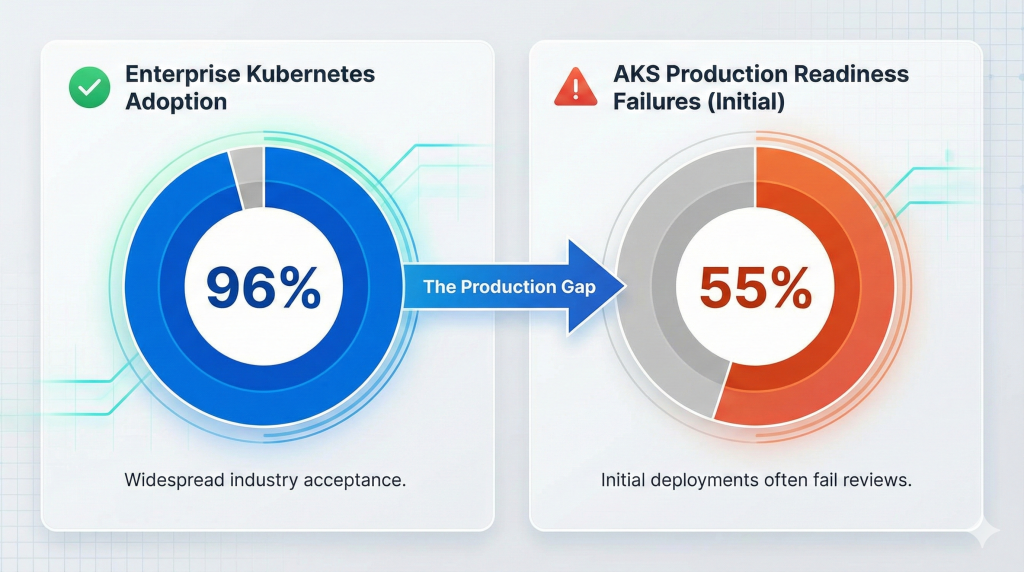
Kubernetes has achieved 96% enterprise adoption, yet 55% of Azure Kubernetes Service implementations fail their initial production readiness reviews. These failures cost organisations £100K-£500K in remediation work, delayed launches, and emergency architectural redesigns. The gap between “running Kubernetes” and “running production-grade Kubernetes” separates successful cloud-native transformations from expensive false starts.
The challenge isn’t Kubernetes complexity itself. Modern enterprises understand containerisation and can deploy development clusters within hours. The failure point emerges when organisations attempt to scale beyond proof-of-concept environments into production systems serving millions of users. Security misconfigurations, incorrect networking models, inadequate monitoring, and over-provisioned resources plague initial deployments. Platform teams spend months retrofitting production patterns into clusters designed for development workloads.
Microsoft’s September 2025 release of AKS Automatic addresses these pain points with production-ready defaults from day one. Manulife modernised legacy insurance systems using AKS, reducing operational complexity whilst increasing speed-to-market for customer-facing applications. Maersk, operating the world’s largest container shipping fleet across 130 countries, migrated critical workloads to AKS without requiring deep orchestration expertise. These aren’t isolated successes. Organisations implementing structured AKS strategies achieve 30-40% cost reductions, 60-80% faster deployment cycles, and 99.95% uptime guarantees through proper architecture from the start.
This guide provides the enterprise architecture patterns, cost optimisation strategies, and implementation roadmap that separate successful AKS deployments from failed experiments. You’ll understand how to architect AKS for production scale, implement security patterns that pass compliance audits, and optimise costs without sacrificing reliability.
The Evolution of Managed Kubernetes
Kubernetes adoption accelerated from 31% cloud-hosted clusters in 2021 to 67% in 2025, with 73% of those running on managed distributions like AKS, Amazon EKS, or Google Kubernetes Engine. This shift represents more than convenience. Organisations discovered that managing Kubernetes control planes diverted platform engineering resources from business value creation to infrastructure maintenance.
Azure Kubernetes Service eliminated control plane management overhead whilst introducing enterprise-grade features unavailable in self-managed deployments. Automated patching, integrated security, and Azure-native service integration transformed Kubernetes from infrastructure burden into business enabler. The Kubernetes market reached $2.57 billion in 2025, projected to grow to $7.07 billion by 2030 at 22.4% compound annual growth rate.
Yet rapid adoption exposed a critical gap. Development teams could spin up clusters quickly, but production deployments required architectural decisions most organisations weren’t prepared to make. Network topology choices, node pool strategies, security configurations, and monitoring implementations determined whether deployments succeeded or required expensive remediation. The 55% production readiness failure rate reflects this architectural maturity gap rather than technology limitations.
AKS Automatic, reaching general availability in September 2025, bridges this gap with opinionated defaults based on Microsoft’s experience running Kubernetes at scale for Teams, Microsoft 365, and Xbox Live. The service delivers production-ready clusters with managed system node pools, Pod readiness SLAs extending beyond API server uptime, and Karpenter-based autoscaling requiring zero configuration. Microsoft achieved Kubernetes AI Conformance certification, positioning AKS for the 140-180% growth in GenAI-specific cloud services driving 2025 infrastructure decisions.
The enterprise conversation shifted from “should we use Kubernetes” to “how do we architect Kubernetes for production at our scale.” Organisations serving 1.5 million customers (Hafslund Nett) or operating across 130 countries (Maersk) require fundamentally different architecture patterns than development teams experimenting with containerisation. Understanding these patterns determines implementation success.
AKS Architecture: Production Patterns
Production-grade AKS architecture balances three competing demands: security requiring network isolation, scalability needing dynamic resource allocation, and cost efficiency eliminating waste. Successful implementations make deliberate architectural choices in five critical areas before deploying workloads.
Node Pool Strategy
AKS clusters use node pools to group virtual machines with identical configurations. System node pools host critical platform components keeping clusters operational, whilst user node pools run application workloads. This separation prevents application failures from impacting cluster stability.
System pools require reliable infrastructure. Microsoft recommends three nodes minimum for high availability, using Standard_D2s_v3 or equivalent SKUs. These nodes run CoreDNS, metrics-server, tunnelfront, and other platform services. User pools scale independently based on application requirements, supporting GPU workloads for machine learning, burstable instances for development environments, or memory-optimised VMs for data-intensive applications.
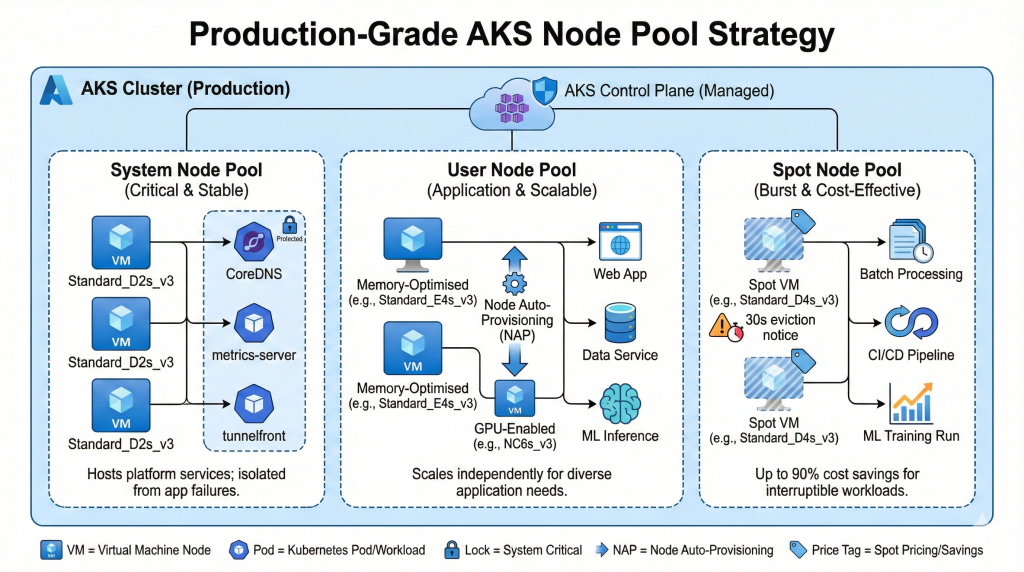
Node Auto-Provisioning (NAP) eliminates manual SKU selection by analysing pending pod resource requirements and provisioning optimal VM configurations automatically. This feature, integrated into AKS Automatic, reduces over-provisioning by 40% whilst ensuring adequate capacity for workload demands. Organisations managing diverse application portfolios benefit most from NAP, as platform teams no longer maintain complex node pool matrices for different workload types.
Spot VM node pools deliver up to 90% cost savings for fault-tolerant workloads. Batch processing, continuous integration pipelines, and machine learning training runs tolerate the 30-second eviction notice Spot VMs receive when Azure reclaims capacity. Production workloads requiring guaranteed availability combine regular node pools for critical services with Spot pools for burst capacity, achieving cost efficiency without sacrificing reliability.
Networking Architecture
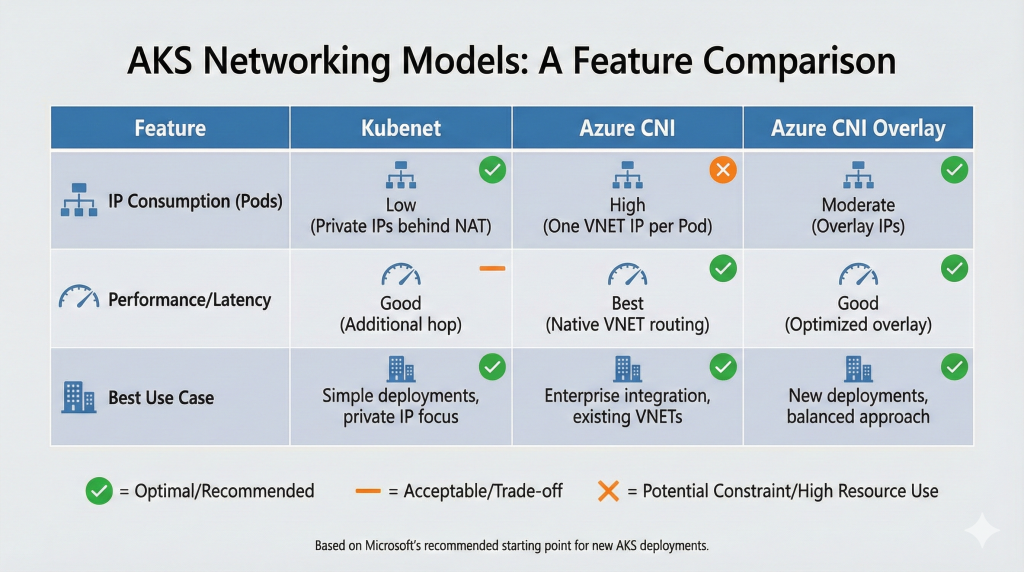
Network topology decisions made during cluster creation fundamentally constrain future architectural possibilities. AKS offers three networking models, each with distinct implications for IP address management, service integration, and operational complexity.
Azure CNI (Container Networking Interface) assigns IP addresses from your Azure Virtual Network to pods and nodes, enabling pods to communicate with other Azure resources using native VNET routing. This model excels in enterprise environments requiring integration with existing networks, on-premises connectivity via ExpressRoute or VPN Gateway, or fine-grained network security policies. The trade-off appears in IP address consumption. Large clusters exhaust available IP space without careful VNET planning, as each pod receives a dedicated IP address.
Kubenet provides simpler networking with lower IP address requirements. Nodes receive VNET IP addresses whilst pods use private network addresses behind NAT. This model suits organisations prioritising simplicity over advanced networking features, though it complicates certain scenarios like pod-to-pod communication across clusters or integration with Azure services expecting VNET-routable addresses.
Azure CNI Overlay, introduced as the hybrid approach, combines benefits from both models. Pods receive overlay network addresses whilst nodes use VNET IPs, reducing address consumption without sacrificing integration capabilities. This newer model represents Microsoft’s recommended starting point for new AKS deployments, though mature organisations with established networking patterns may prefer consistency with their existing model.
Private clusters restrict API server access to private IP addresses within your VNET, eliminating public internet exposure of cluster management endpoints. Regulated industries and security-conscious organisations mandate private clusters, accepting the operational complexity of managing private DNS zones and bastion hosts for administrative access. Our research on implementing robust cloud infrastructure explored similar network isolation patterns across cloud platforms.
Security Architecture
Production AKS security operates across five layers: identity and access management, network policies, workload security, secrets management, and compliance monitoring. Each layer requires deliberate implementation rather than relying on default configurations.
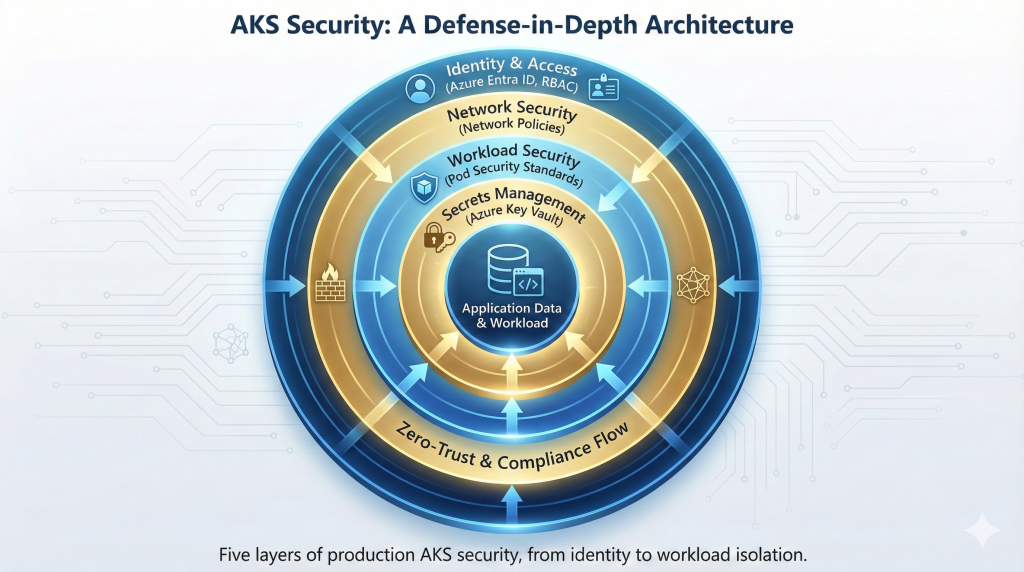
Azure Entra ID (formerly Azure Active Directory) integration authenticates cluster access using organisational identities rather than static certificates. Role-Based Access Control (RBAC) then determines what authenticated users can do within clusters. Azure RBAC integrates with existing identity governance, whilst Kubernetes RBAC provides fine-grained control over cluster resources. Mature organisations implement both, using Azure RBAC for infrastructure-level permissions and Kubernetes RBAC for namespace and workload isolation.
Network policies control traffic between pods, implementing zero-trust networking within clusters. Azure Network Policy Manager and Calico both provide policy enforcement, though Calico offers more advanced features for complex network security requirements. Default-deny policies prevent unauthorised communication, whilst explicit allow rules define legitimate traffic patterns. This approach limits blast radius when workloads become compromised.
Pod Security Standards replaced deprecated Pod Security Policies, providing three enforcement levels: privileged, baseline, and restricted. AKS Automatic enforces baseline standards by default, preventing common security anti-patterns like privileged containers, host namespace access, and privilege escalation. Organisations requiring stricter controls implement restricted standards, accepting operational overhead of managing security exceptions for legitimate privileged workloads.
Secrets management integration with Azure Key Vault eliminates secrets stored in cluster configuration. The Secrets Store CSI Driver mounts Key Vault secrets as volumes in pods, ensuring sensitive data never persists in etcd. Certificate rotation, access auditing, and centralized secrets management become Azure Key Vault responsibilities rather than cluster-specific concerns. Our guide on Kubernetes security best practices covers container security patterns applicable across orchestration platforms.
Storage Architecture
Persistent storage for stateful applications introduces architectural complexity beyond ephemeral container filesystems. AKS supports multiple storage classes, each optimised for different workload characteristics.
Azure Disk provides block storage for single-pod access patterns. Standard HDD, Standard SSD, Premium SSD, and Ultra Disk tiers offer price-performance trade-offs ranging from cost-optimised archival storage to sub-millisecond latency for database workloads. Storage classes define provisioning parameters, allowing platform teams to offer application developers standardised storage tiers without exposing Azure-specific implementation details.
Azure Files delivers shared storage accessible from multiple pods simultaneously using SMB or NFS protocols. This capability suits applications requiring shared configuration, log aggregation, or legacy systems designed for file-based storage. Performance tiers mirror Azure Disk options, though network-attached storage introduces latency compared to directly-attached disks.
Azure Container Storage, reaching general availability in 2024, provides container-native storage with higher performance and lower latency than traditional Azure storage services. Version 2.0, released in 2025, focuses on efficient resource management and Kubernetes-native user experiences for stateful workloads. This purpose-built solution addresses container-specific storage requirements that general-purpose storage services struggle to satisfy.
Ephemeral OS disks run the operating system from local VM cache rather than managed disks, eliminating storage costs and improving boot performance for stateless workloads. This optimisation applies to system node pools and stateless application nodes, though stateful workloads requiring persistent data obviously cannot use ephemeral storage.
Scaling and Autoscaling
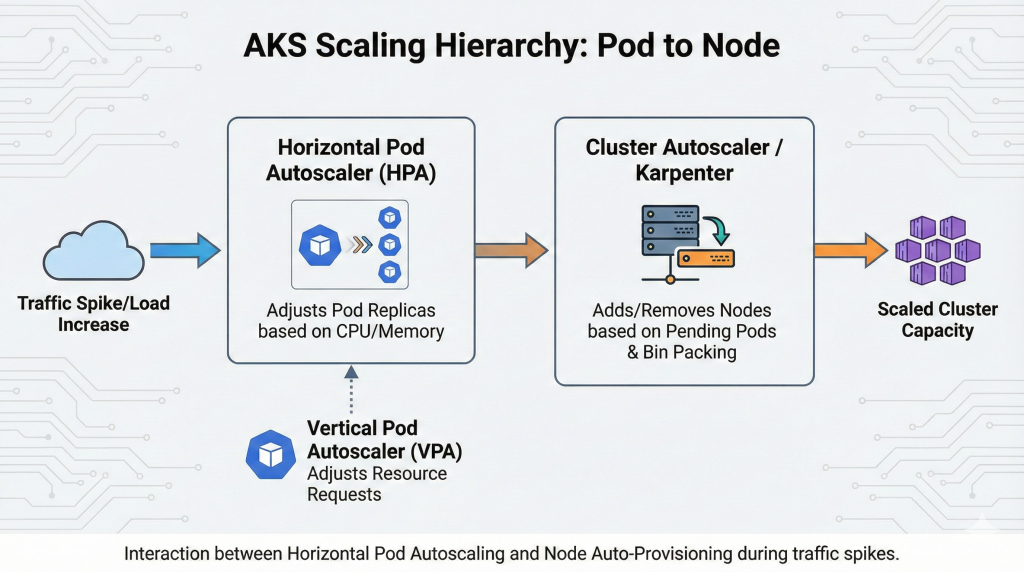
Production clusters adapt to demand dynamically rather than maintaining static capacity. AKS implements scaling at three levels: pod-level horizontal scaling, node-level cluster autoscaling, and application-level request handling.
Horizontal Pod Autoscaler (HPA) adjusts pod replica counts based on CPU utilisation, memory consumption, or custom metrics. Applications experiencing traffic spikes automatically scale out to handle load, then scale in when demand subsides. This reactive approach works well for predictable scaling patterns, though it introduces brief latency during scale-up events as new pods initialise.
Vertical Pod Autoscaler (VPA) modifies pod resource requests and limits based on observed usage patterns. This approach suits applications with variable resource requirements difficult to predict upfront. VPA prevents both over-provisioning (wasted spend on unused capacity) and under-provisioning (performance degradation or out-of-memory crashes).
Cluster Autoscaler provisions additional nodes when pod scheduling fails due to insufficient capacity, and removes underutilised nodes when capacity exceeds demand. This cluster-level scaling ensures applications can scale horizontally without hitting infrastructure constraints. Karpenter, integrated into AKS Automatic, improves upon traditional Cluster Autoscaler by grouping pending pods optimally and selecting appropriate VM SKUs automatically. Organisations using Karpenter report 30-50% better bin packing efficiency compared to manual node pool management.
KEDA (Kubernetes Event-Driven Autoscaling) extends HPA to scale based on event sources beyond standard metrics. Applications processing Azure Service Bus queues, monitoring blob storage containers, or responding to external webhook events scale automatically as work arrives. This event-driven approach reduces infrastructure costs for intermittent workloads by scaling to zero when no processing occurs. Cost optimisation strategies we covered in our Kubernetes cost optimization guide apply across managed Kubernetes services.
Enterprise Case Studies
Real-world implementations demonstrate how architectural decisions translate into measurable business outcomes. These organisations achieved production success by addressing specific challenges through deliberate AKS implementations.
Company Name & Industry: Manulife (John Hancock), Global Insurance and Financial Services
Scale Context: International operations serving millions of customers across North America and Asia, processing high volumes of policy applications and claims
Challenge: Legacy systems created operational bottlenecks limiting ability to launch new customer-facing features. Monolithic architecture prevented rapid iteration and complicated scaling during peak periods. Document processing workflows required manual intervention, creating delays in policy underwriting and claims adjudication.
Solution Implemented: Modernised legacy systems using Azure Kubernetes Service for cloud-native, containerised applications. Implemented document analysis using Azure AI services integrated with AKS workloads. Adopted microservices architecture enabling independent service scaling and deployment.
Measurable Outcomes:
- Reduced operational complexity through managed Kubernetes eliminating infrastructure maintenance overhead
- Increased speed-to-market for customer features, improving competitive positioning
- Enhanced scalability supporting peak load processing without manual capacity planning
- Improved customer experience through accelerated document processing workflows
Source: Microsoft Azure Customer Success Stories
Company Name & Industry: A.P. Moller-Maersk, Global Container Shipping and Logistics
Scale Context: World’s largest container shipping line operating across 130 countries with approximately 80,000 employees, managing complex global supply chain operations
Challenge: Traditional datacenter infrastructure couldn’t support digital transformation initiatives. IT resources required extensive lead time for provisioning, preventing rapid response to business requirements. Needed to modernise open-source software stack whilst maintaining operational reliability for mission-critical shipping operations.
Solution Implemented: Migrated key workloads to Azure Kubernetes Service as part of hybrid cloud strategy. Leveraged AKS for automated container management without requiring deep orchestration expertise. Integrated with existing open-source tools including Ansible, Cloudera, Jenkins, and multiple Linux distributions. Implemented Azure Monitor for comprehensive visibility into containerised applications.
Measurable Outcomes:
- IT engineers redirected time from infrastructure management to addressing customer requests
- Added enhanced shipment monitoring capabilities to service portfolio
- Achieved operational efficiency gains through automated resource scaling
- Maintained application availability during infrastructure changes with zero-downtime deployments
Source: AKS Case Study: Maersk
Company Name & Industry: Robert Bosch GmbH, Automotive Technology and IoT Solutions
Challenge: Required real-time processing of GPS location data to identify wrong-way drivers on German highways with life-safety precision. Existing services lacked the accuracy and speed necessary for reliable alerting. System needed to handle massive volumes of sensor data whilst maintaining sub-second response times.
Solution Implemented: Architected wrong-way driver warning (WDW) service using AKS for scalable container orchestration. Integrated Azure HDInsight with Apache Kafka for streaming data processing. Developed custom sensor data-fusion and map-matching algorithm running on AKS clusters. Implemented multistep classification approach reducing computational complexity for cost-effective architecture.
Measurable Outcomes:
- Achieved life-safety-grade precision in real-time location verification
- Processed high-volume GPS sensor data streams with sub-second latency
- Maintained cost-effective operation through optimised algorithm design
- Scaled automatically to handle variable traffic patterns across German highway network
Source: AKS Case Study: Robert Bosch
Company Name & Industry: Hafslund Nett, Norwegian Power Grid Operator
Scale Context: Serves 1.5 million Norwegian citizens across 40+ communities in Oslo region, managing critical infrastructure for electricity distribution
Challenge: Legacy meter-reading systems required higher capacity to support growing customer base. Externally developed software proved difficult to manage and customise for specific operational requirements. Needed development platform balancing rapid iteration with security and performance control.
Solution Implemented: Developed proprietary meter-system software on Azure platform using AKS for container management. Deployed Azure Monitor for containers to optimise performance and resource utilisation. Implemented Azure-native security controls maintaining compliance with critical infrastructure regulations.
Measurable Outcomes:
- IT staff time savings through managed infrastructure eliminating manual cluster maintenance
- Higher reliability for 1.5 million customers through improved meter-reading systems
- Enhanced security and performance control for critical infrastructure operations
- Accelerated development and testing cycles whilst maintaining operational safety
Source: AKS Case Study: Hafslund Nett
These implementations demonstrate common success patterns: organisations modernising legacy systems achieve operational efficiency gains, those requiring scale manage peak loads without manual intervention, and enterprises prioritising security maintain compliance whilst accelerating development velocity. Success requires matching architectural patterns to specific business requirements rather than adopting generic configurations.
Cost Analysis and Optimisation
AKS pricing complexity stems from multiple service layers each contributing to total cost of ownership. Understanding cost drivers enables architectural decisions optimising spend without sacrificing reliability.
Pricing Model
AKS offers three pricing tiers for managed control planes. The Free tier costs £0 per cluster but provides no uptime SLA, suitable for development environments and experimentation. Standard tier operates at £0.10 per hour (approximately £73 monthly) with 99.95% SLA, representing the default for production workloads. Premium tier charges £0.60 hourly (approximately £438 monthly) whilst including Long-Term Support enabling two-year Kubernetes version stability for regulated workloads resistant to frequent upgrades.
Control plane costs remain negligible compared to infrastructure expenses. Virtual machines running worker nodes constitute 70-80% of typical AKS bills. Storage, networking, and monitoring compose remaining costs in ratios varying by workload characteristics.
Virtual machine expenses depend on SKU selection and scaling patterns. Standard_DS2_v3 instances (2 vCPUs, 7GB RAM) commonly used for general workloads cost approximately £0.10 per hour in UK South region using pay-as-you-go pricing. Memory-optimised Standard_E4s_v3 instances (4 vCPUs, 32GB RAM) increase costs to £0.25 hourly. GPU-enabled NC6s_v3 instances supporting machine learning workloads reach £0.83 per hour before discounts.
Storage costs scale with volume count, size, and performance tier. Standard HDD managed disks cost £0.04 per GB monthly, whilst Premium SSD reaches £0.12 per GB and Ultra Disk approaches £0.20 per GB for sub-millisecond latency. Ephemeral OS disks eliminate these costs entirely for stateless workloads by using local VM cache rather than attached storage.
Networking expenses emerge from load balancers, public IP addresses, and data egress. Standard Load Balancer charges £0.025 per hour plus £0.005 per GB processed. Data transfer within Azure regions remains free, whilst egress to internet incurs £0.087 per GB for the first 10TB monthly in European regions.
Monitoring costs often surprise organisations implementing comprehensive observability. Azure Monitor and Log Analytics charge based on data ingestion volume and retention period. Default configurations generate 5-10GB daily ingestion for modest clusters, translating to £600-£1,200 monthly at standard rates. Container Insights and managed Prometheus offer more cost-effective alternatives for Kubernetes-specific monitoring.
Cost Optimisation Strategies
Reserved Instances reduce VM costs by 48% for one-year commitments and 65% for three-year terms compared to pay-as-you-go pricing. These savings apply to specific VM families and regions, requiring capacity forecasting accuracy challenging for organisations experiencing rapid growth or shifting workload patterns. The commitment trade-off suits stable production workloads with predictable capacity requirements.
Spot Virtual Machines leverage unused Azure capacity at 80-90% discounts, though Azure reclaims them with 30-second notice when capacity becomes constrained. Batch processing, continuous integration pipelines, and machine learning training benefit from Spot pricing’s dramatic savings whilst tolerating interruption risk through checkpoint-restart mechanisms. Production services combine Spot capacity for burst scaling with reserved capacity for baseline load, achieving optimal cost-performance ratios. Our FinOps strategic framework provides comprehensive approaches to cloud cost management beyond tactical optimisations.
Node Auto-Provisioning eliminates over-provisioning by selecting optimal VM SKUs automatically based on pending pod requirements. Traditional approaches maintain diverse node pools anticipating various workload types, often over-provisioning capacity “just in case.” NAP dynamically provisions nodes matching actual demand, reducing unused capacity by 30-40% whilst maintaining application performance.
Right-sizing workload resource requests prevents waste from pods allocated excessive CPU and memory never utilised. Vertical Pod Autoscaler analyses actual consumption patterns, recommending or automatically adjusting requests to match reality. Organisations implementing systematic right-sizing report 20-30% infrastructure cost reductions without application changes.
Cluster Autoscaler removes underutilised nodes when capacity exceeds demand, though conservative settings often leave clusters partially empty to handle sudden load increases. Karpenter improves upon traditional Cluster Autoscaler through better bin packing, consolidating pods onto fewer nodes and scaling more aggressively during scale-down. This efficiency translates into 15-25% compute cost savings for clusters with variable load patterns.
Container image optimisation reduces storage costs and improves deployment speed. Alpine Linux base images consume 5-10MB compared to 100MB+ for standard distributions. Multistage Docker builds eliminate build tools and dependencies from production images. Smaller images decrease persistent volume claims for image caching whilst accelerating pod startup times during scaling events.
Implementing AKS Cost Analysis add-on provides granular visibility into spending by namespace, label, or team. This attribution enables chargeback models holding application teams accountable for infrastructure consumption. Visibility alone drives 10-15% cost reductions as teams optimise wasteful patterns once spending becomes transparent.
Total Cost of Ownership
Three-year TCO analysis reveals significant cost differences between architectural approaches. A medium-sized production deployment supporting 50 microservices requires different investment than enterprise platforms serving hundreds of applications.
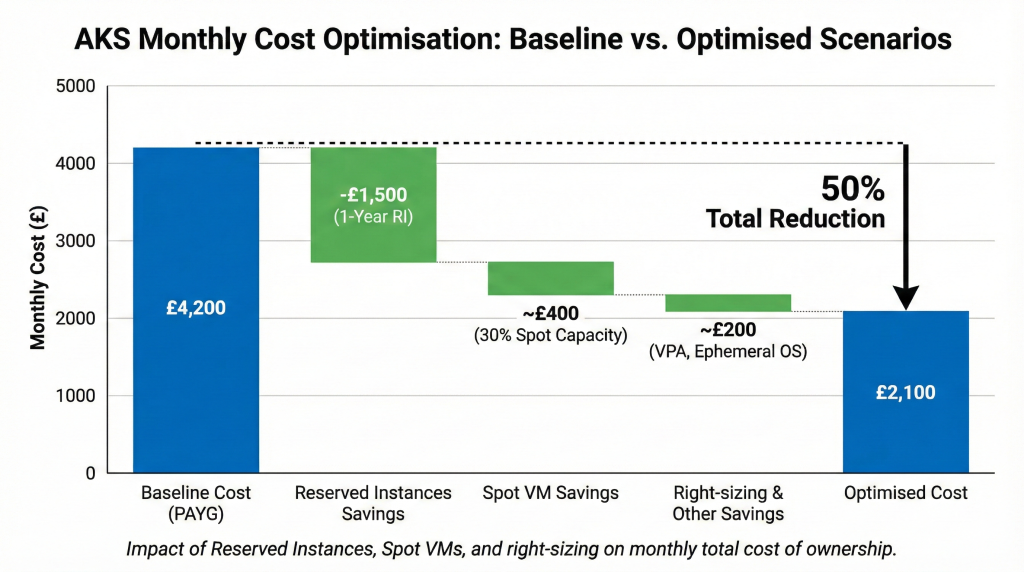
Baseline scenario: 10-node cluster (Standard_D4s_v3), Standard tier control plane, Premium SSD storage, Standard Load Balancer, and Container Insights monitoring generates approximately £4,200 monthly (£50,400 annually) using pay-as-you-go pricing. This represents development or small production deployment scale.
Optimised scenario: Same workload using one-year Reserved Instances (48% discount), Spot VMs for 30% of capacity (85% discount), Ephemeral OS disks, managed Prometheus replacing Container Insights, and right-sized resources reduces costs to approximately £2,100 monthly (£25,200 annually). This 50% reduction requires minimal architectural changes whilst maintaining reliability.
Enterprise scenario: 50-node production cluster with multi-region deployment, Premium tier control plane for LTS, comprehensive monitoring, and full disaster recovery capability reaches £18,000 monthly (£216,000 annually) before optimisation. Implementing reserved capacity, strategic Spot usage, and cost allocation drives spending to £12,000 monthly (£144,000 annually), representing 33% savings at scale.
Return on investment from AKS versus self-managed Kubernetes emerges from eliminated operational overhead. Organisations managing self-hosted Kubernetes clusters employ 2-4 full-time engineers maintaining control planes, implementing upgrades, and managing infrastructure. Assuming £80,000-£120,000 annual cost per engineer, AKS control plane management justifies itself through avoided personnel expenses before considering infrastructure costs.
Production Readiness Decision Framework
Architectural decisions made during initial AKS deployment determine implementation success. These framework questions guide teams toward appropriate patterns for specific requirements.
Networking Model Selection
Choose Azure CNI when: existing enterprise networks require pod-level integration, applications need VNET-routable IP addresses for security policies, or on-premises connectivity via ExpressRoute/VPN demands native routing. Accept higher IP address consumption requiring careful VNET planning.
Choose Kubenet when: simplicity outweighs advanced networking requirements, IP address space is limited and pods can use private addressing behind NAT, or workloads primarily communicate within the cluster rather than with external Azure services.
Choose Azure CNI Overlay when: starting new deployments without legacy networking constraints, need Azure service integration without excessive IP consumption, or want Microsoft’s recommended balance between capability and complexity.
Implement private clusters when: regulatory requirements mandate API server isolation, security policies prohibit public internet exposure of management endpoints, or accepting operational complexity of private DNS and bastion access aligns with organisational security posture.
Node Pool Strategy
Use system-only pools when: separating platform stability from application behaviour represents critical operational requirement, ensuring cluster management components remain unaffected by workload failures matters more than resource efficiency.
Implement multiple user pools when: diverse workload types require different VM characteristics (GPU, memory-optimised, burstable), cost optimisation through Spot VMs benefits specific applications whilst others need guaranteed capacity, or isolating workloads by team, environment, or compliance requirements.
Deploy Node Auto-Provisioning when: managing complex node pool matrices consumes excessive operational effort, workload resource requirements vary significantly, or automatic optimal SKU selection provides better efficiency than manual configuration.
Scaling Configuration
Implement HPA when: applications support horizontal scaling through stateless design, CPU or memory metrics effectively predict load requirements, or reactive scaling sufficiently addresses demand patterns.
Add VPA when: applications demonstrate variable resource consumption difficult to predict upfront, right-sizing resource requests manually proves time-consuming and error-prone, or systematic elimination of over-provisioned capacity justifies automation overhead.
Use Cluster Autoscaler when: workload patterns vary predictably requiring capacity changes but manual node management proves impractical, or cost optimisation through automatic scale-down during off-peak periods delivers significant savings.
Adopt Karpenter when: improved bin packing efficiency justifies migration from traditional Cluster Autoscaler, diverse workload requirements benefit from automatic SKU selection, or scale-down aggressiveness requires optimisation beyond Cluster Autoscaler capabilities.
Deploy KEDA when: workloads respond to event sources beyond standard metrics like message queues or blob storage, applications benefit from scale-to-zero capabilities during idle periods, or event-driven architectures align with application design patterns.
Security Posture
Implement Azure RBAC when: integrating cluster access with organisational identity governance represents priority, centralised management of permissions across Azure resources provides operational efficiency, or simplified permission model suffices for namespace-level isolation.
Add Kubernetes RBAC when: fine-grained control over specific resources within namespaces becomes necessary, advanced RBAC features beyond Azure’s implementation are required, or maintaining Kubernetes-native permission models enables multi-cloud portability.
Enforce Pod Security Standards when: preventing common security anti-patterns like privileged containers justifies baseline policy enforcement, regulatory compliance requires demonstrable security controls, or operational overhead of managing policy exceptions remains acceptable.
Integrate Key Vault when: secrets management requirements exceed native Kubernetes capabilities, centralised secrets rotation and access auditing provide compliance benefits, or eliminating secrets from cluster configuration addresses security concerns.
Deploy network policies when: zero-trust networking within clusters represents security requirement, limiting blast radius of compromised workloads matters for defence-in-depth strategy, or application isolation beyond namespace boundaries becomes necessary.
Implementation Roadmap
Successful AKS deployments follow phased approaches balancing velocity with architectural completeness. This roadmap structures implementation from foundation through production optimisation.
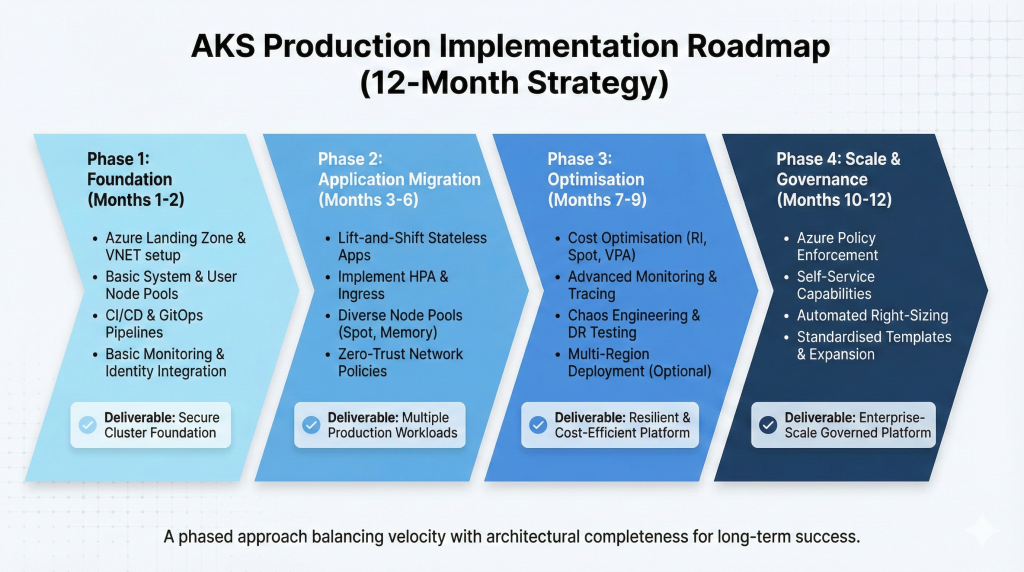
Phase 1: Foundation (Months 1-2)
Establish Azure landing zone with hub-spoke network topology supporting AKS workloads. Configure centralised logging, monitoring infrastructure, and identity integration with Azure Entra ID. Deploy initial AKS cluster using Standard tier with private endpoint configuration for enterprise security posture.
Implement basic node pools: system pool with three nodes for platform stability, single user pool for application workloads. Configure Azure CNI networking if enterprise integration requirements demand VNET-routable pods, otherwise implement CNI Overlay for optimal IP address efficiency.
Deploy Azure Container Registry for private image hosting. Establish CI/CD pipelines using Azure DevOps or GitHub Actions automating container builds and deployments. Implement GitOps patterns using Flux or ArgoCD for declarative cluster configuration management.
Configure basic monitoring using managed Prometheus and Grafana integration. Establish alerting for cluster health, node resource utilisation, and pod failures. Implement initial cost tracking enabling spend visibility before optimisation.
Expected deliverable: Production-ready cluster foundation supporting initial application deployments with enterprise security, monitoring, and deployment automation.
Phase 2: Application Migration (Months 3-6)
Migrate initial wave of applications using lift-and-shift containerisation for stateless services. Implement Horizontal Pod Autoscaler for workloads exhibiting predictable scaling patterns. Configure Ingress controllers (Azure Application Gateway Ingress Controller or NGINX) for external traffic routing.
Establish multiple user node pools supporting diverse workload requirements: memory-optimised pools for data processing, Spot VM pools for batch workloads, GPU pools for machine learning experimentation. Implement Pod Disruption Budgets ensuring application availability during node maintenance.
Configure Azure Key Vault integration using Secrets Store CSI Driver for sensitive configuration management. Implement network policies establishing zero-trust communication patterns between services. Deploy service mesh (Istio or Linkerd) if advanced traffic management, observability, or security requirements justify operational complexity.
Establish backup and disaster recovery patterns using Velero or Azure Backup for Kubernetes. Test recovery procedures validating RTO and RPO targets. Document runbooks for common operational scenarios including scaling, updates, and incident response.
Expected deliverable: Multiple applications running production workloads with established operational patterns, security controls, and recovery capabilities.
Phase 3: Optimisation (Months 7-9)
Implement cost optimisation strategies: Reserved Instances for baseline capacity, strategic Spot VM usage for appropriate workloads, right-sizing through VPA analysis. Enable Node Auto-Provisioning eliminating manual node pool management overhead.
Deploy advanced monitoring solutions providing application performance management, distributed tracing, and cost attribution by team or application. Implement custom metrics and alerting reflecting business SLOs rather than infrastructure-focused metrics alone.
Establish chaos engineering practices validating resilience through controlled failure injection. Test cluster autoscaling under load, node failure scenarios, and application degradation patterns. Validate disaster recovery procedures through scheduled drills.
Configure multi-region deployment for business-critical applications requiring geographic redundancy. Implement Azure Front Door for global load balancing and failover. Establish observability across regions enabling correlation of distributed application behaviour.
Expected deliverable: Optimised production platform with validated resilience, cost efficiency, and operational maturity supporting business-critical workloads.
Phase 4: Scale and Governance (Months 10-12)
Implement platform-level governance: Azure Policy enforcement for security standards, tag-based cost allocation, automated compliance reporting. Deploy Azure Kubernetes Fleet Manager for managing multiple clusters at scale.
Establish self-service capabilities enabling application teams to provision namespaces, configure ingress, and deploy workloads within governance guardrails. Implement Platform-as-a-Service abstraction layers if appropriate for organisational maturity.
Optimise cluster density through advanced bin packing, mixed workload placement strategies, and comprehensive resource request tuning. Implement automated right-sizing recommendations generated from production usage patterns.
Expand to additional regions or business units based on learnings from initial deployment. Standardise deployment patterns, operational procedures, and architectural decisions into reusable templates accelerating subsequent implementations.
Expected deliverable: Enterprise-scale Kubernetes platform supporting organisational growth with mature governance, operational excellence, and established patterns for expansion.
Strategic Recommendations
Production-grade AKS implementations balance five competing priorities: security requiring defence-in-depth patterns, cost efficiency demanding continuous optimisation, operational simplicity reducing management overhead, scale supporting growth, and reliability meeting business requirements.
Start with managed services wherever possible. AKS Automatic delivers production-ready defaults eliminating architectural decisions appropriate for 80% of deployments. Custom patterns address specific requirements rather than premature optimisation anticipating needs that may never materialise.
Invest in comprehensive monitoring from day one. Cost visibility, performance metrics, security telemetry, and application observability inform optimisation decisions with measurable business impact. Platform teams drowning in alerts but lacking actionable insights fail to achieve operational maturity regardless of architectural sophistication.
Implement security as architecture rather than bolt-on controls. Network segmentation, identity-based access, secrets management, and policy enforcement designed into platform foundations prove easier to maintain than retrofitted security hardening. Organisations achieving compliance certifications without emergency remediation designed security architecturally from initial deployment.
Establish clear cost accountability through granular attribution. Teams responsible for infrastructure spending optimise consumption patterns 30-50% more effectively than centralised platform groups absorbing costs as operational expense. FinOps practices driving cost awareness throughout development organisations deliver sustainable efficiency improvements.
Plan for production from development cluster deployment. Architectural decisions made during experimentation constrain future capabilities. Development-grade networking models, insufficient monitoring, or absent security patterns require expensive cluster rebuilds when promotion to production reveals architectural inadequacy. Production patterns implemented initially prove cheaper than remediation later.
Consider AKS Automatic for new deployments lacking legacy constraints. Managed system node pools, automatic upgrades, integrated monitoring, and production-ready security defaults eliminate 60-80% of cluster lifecycle management overhead. Organisations requiring custom patterns selectively override defaults rather than building complete platforms from scratch.
Useful Links
- AKS Engineering Blog – Official Microsoft engineering insights and feature announcements
- AKS Production Checklist – Comprehensive production readiness verification
- Microsoft Learn: AKS Documentation – Official technical documentation and tutorials
- Azure Kubernetes Service pricing – Current pricing calculator and cost estimation
- CNCF Kubernetes Documentation – Upstream Kubernetes concepts and patterns
- AKS Release Tracker – Regional release status and feature availability
- Azure Architecture Centre: AKS baseline – Reference architecture for production deployments
- Microsoft Cost Management documentation – Cost analysis and optimisation guidance
- Kubernetes in the Wild Report 2025 – Industry adoption statistics and trends
- Azure Monitor for containers – Monitoring implementation and best practices